Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support
A Streamlit app that happily runs locally fails when deployed to CDF.
The line `st.dataframe([{‘key’: ‘value’, ...}])` produces this error. Not every time, but once the error happens, it does not recover and keeps showing this error even though the app reruns to show updated data.
Error: External format error: File out of specification: Repetition level must be defined for a primitive type
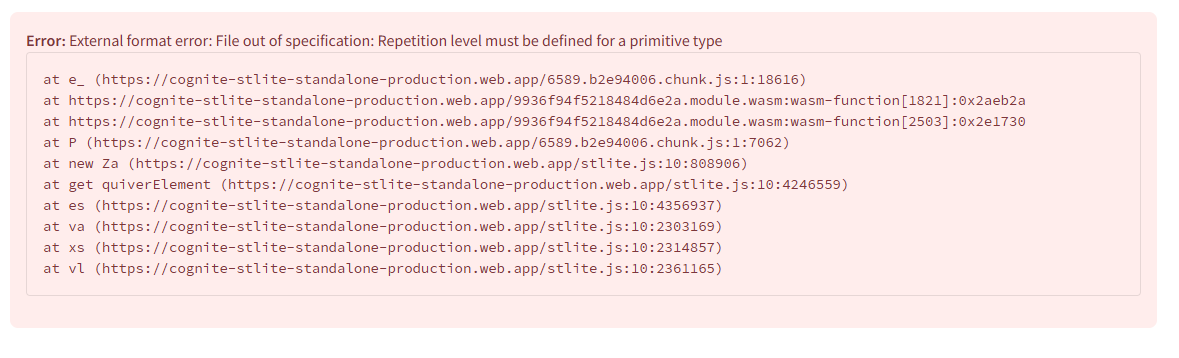
Do you have a workaround?
It is a simple data set really just string key-value pairs. When it works, it looks like this:

Contact me and I will share the URL of the deployed streamlit app.