

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


Dear Community!
We are excited to announce the September 2024 release of Cognite Data Fusion! This post covers some significant highlights and will walk you through selected functionality.
These enhancements will be made available on September 17th, 2024. You can also find more detailed information in our release notes on our Documentation portal. We would love to hear your feedback here on Cognite Hub over the coming weeks.
We also want to thank all our community members for their contributions so far. We're eager to continue this collaborative process with you, seeking your valuable input on both existing and upcoming product features. Please share your Product Ideas here in the community. This helps us understand how we can keep improving Cognite Data Fusion to fit your needs. Let's keep this momentum going!
Here’s a short video summarizing the exciting updates
Data foundation
This September, our feature updates come with a unifying theme: Data Foundation. But what exactly does that mean, and why is it important now? As the name suggests, Data Foundation is about creating a solid base to build on and expand upon. The key reasons to invest in this foundation include:
-
Accelerating onboarding: By streamlining the onboarding process, we reduce the time it takes for users to start seeing value.
-
Laying the groundwork for future success: A strong foundation is crucial for success in areas like Atlas AI, digital operator rounds, turnarounds, and much more to come.
-
Enhancing user experience: Aligning our entire tech stack around these foundational features ensures a seamless and consistent user experience.
Cognite core data model enablement
We've simplified our approach to data modeling and aligned all our technologies around it to enhance your experience. We’re introducing out of the box Cognite data models, which streamline industrial data management by integrating a standardized core model with industry-specific extensions and customizable solutions.
Starting this September, you’ll have access to the Cognite core data model and the initial version of the Process Industry data model — the first in a series tailored to meet specific industry needs. These models serve as building blocks to solve your unique challenges without data duplication, offering guaranteed functionality without the need for additional configurations. Everything just works!
In this release, we’ve achieved a lot — over 30 new features are coming your way, many of them tied to the Data Foundation theme. All our applications and underlying services now support the Cognite core data model.
Rapidly onboard to Cognite data models
You can now onboard data from source systems directly into Cognite data models using our Cognite File, OPCUA, PI, and SAP_OData extractors. This process is fully supported, with seamless integration into the Cognite core data model, allowing for the transformation of data, creation of time series, files, and annotations. With this release, you can also access, search, and contextualize 3D data together with other Cognite data within a unified model. This enhances insights, boosts efficiency, and enables better decision-making.
Search across the same data in all applications
You can search and find the same data from your desktop in the office or your mobile device while in the field. Enhanced search functionality uses the Cognite core data model to deliver more optimized results. Customer-defined data models can also be used and users can select and arrange columns and customize views.
Express the data in your own way with the tools you already love
We’re not stopping here — we know you love the tools you already use, so we’ve made sure they benefit from the latest updates. With this release, you can leverage powerful no-code troubleshooting and root cause analysis in Charts, using time series and activities natively from the Cognite core model. Additionally, you can now search and explore data seamlessly across both the Cognite Core model and existing models in Industrial Canvas. In short, this update provides a more intuitive and uniform search experience across all CDF applications.
Industrial tools
Filtering and navigation
Filtering: In addition to location filters in Search, Canvas, and Charts, you can select specific data models. Choose between predefined location filters and specific data models for a flexible user experience that meets different needs for different users.
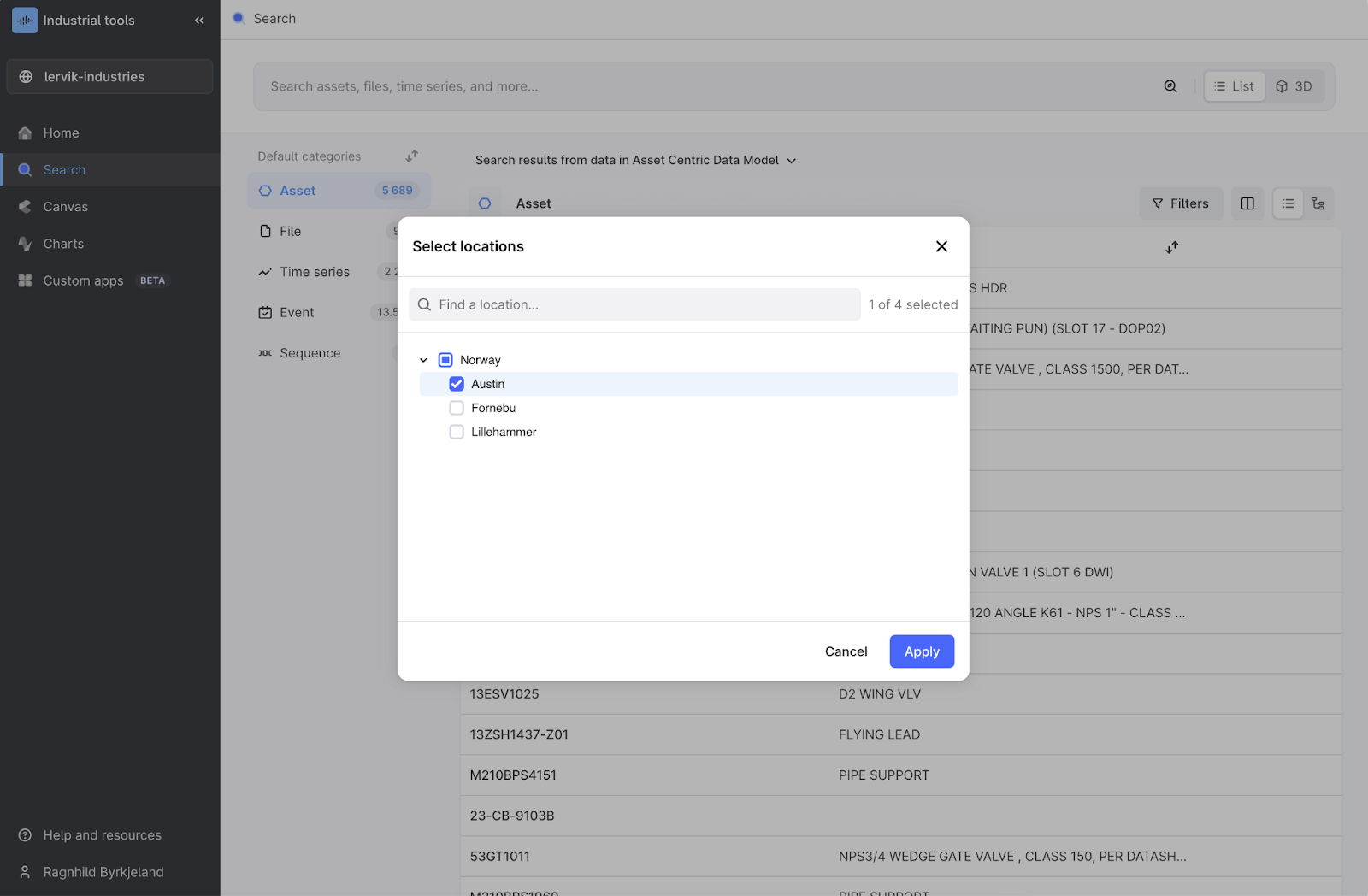
Unified navigation: Users have faced challenges when navigating through the CDF platform, leading to confusion and inefficiencies. In response to this feedback, we're thrilled to introduce a unified top bar with breadcrumbs. This new feature is designed to streamline navigation across all applications and services within the platform.
Search defaults and improvements
Default exploration tool: To enhance accessibility and usability, we are making Search the default search engine for our industrial users. Users will still have the option to switch back to Data Explorer easily by clicking the “Switch to Data Explorer” option. By making Search the new default search experience, we bring the Cognite core data model closer to end-users, ensuring a more streamlined experience when exploring data.
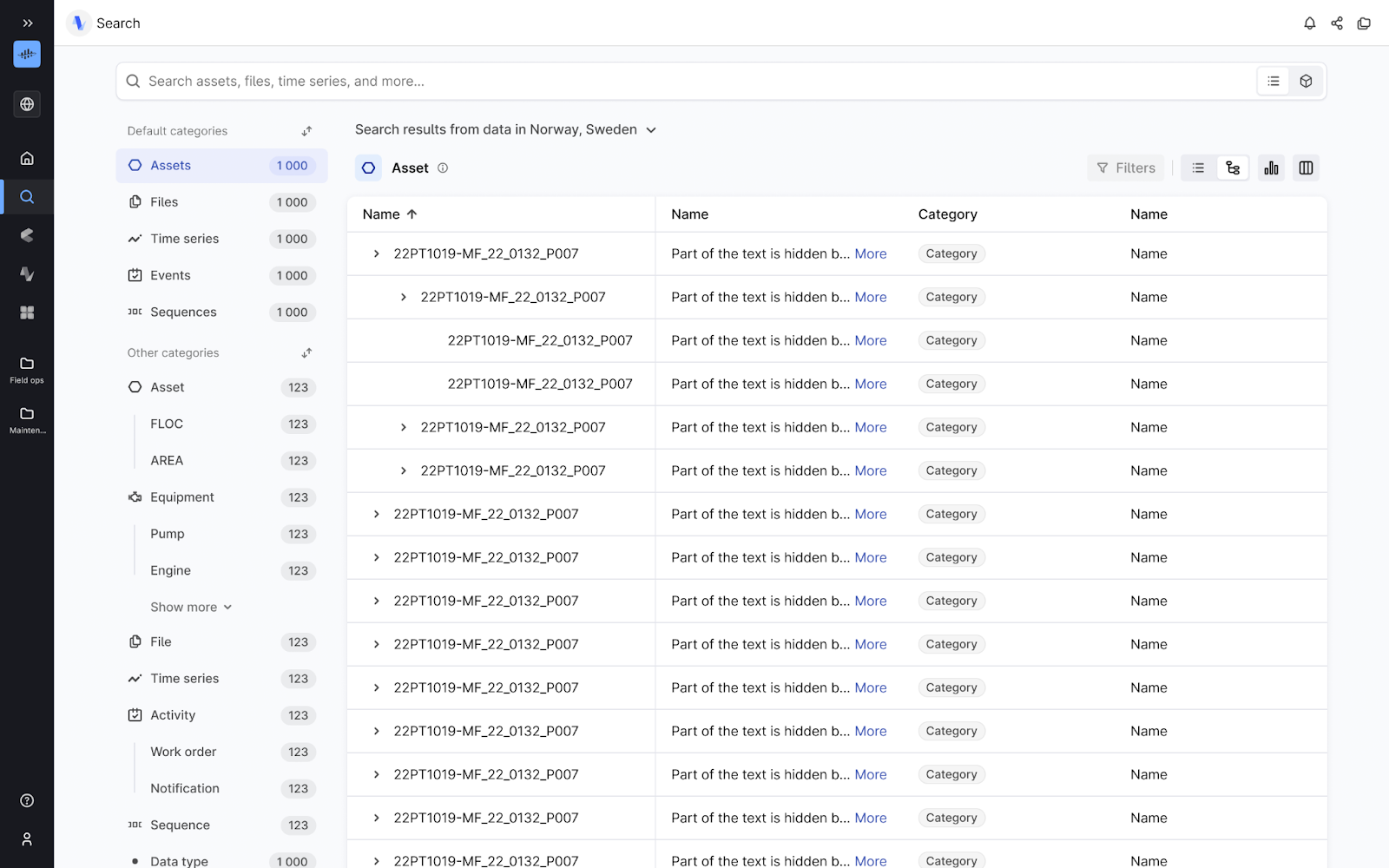
Hierarchy view: We are excited to announce a significant enhancement to the search functionality that addresses navigation challenges within the asset hierarchy!
To improve the user experience, we are rolling out a hierarchical view for asset-centric data model assets. This new feature lets users look at assets in a clear and organized tree-view format. They can quickly browse and understand relationships between assets, which makes data handling more efficient.
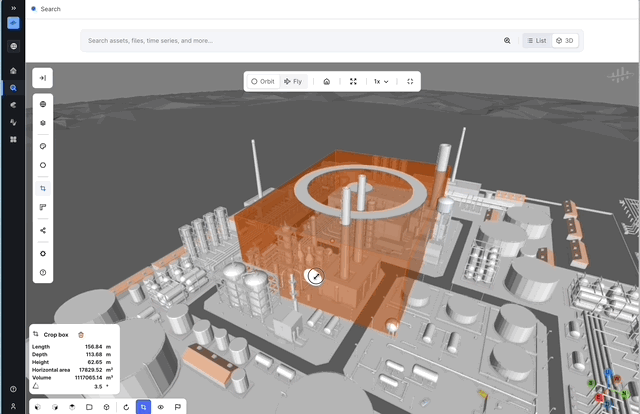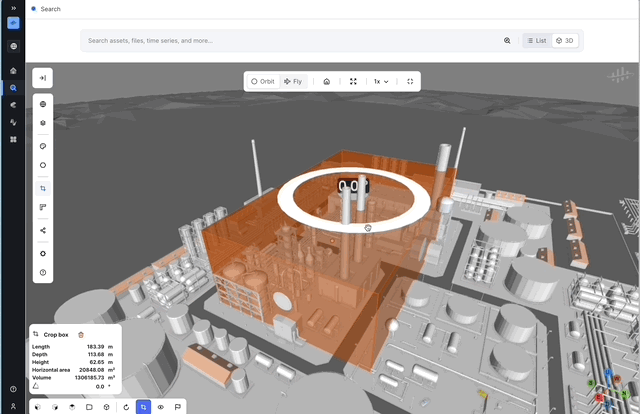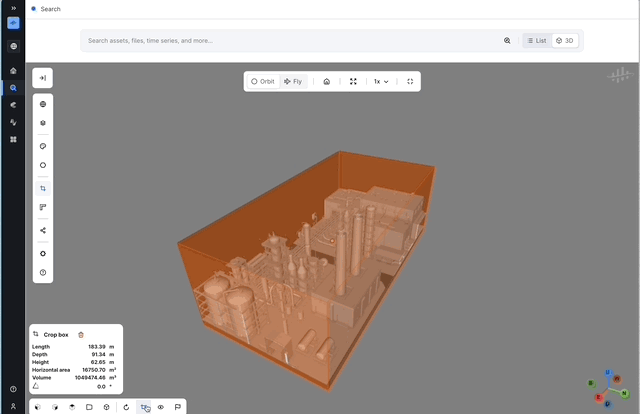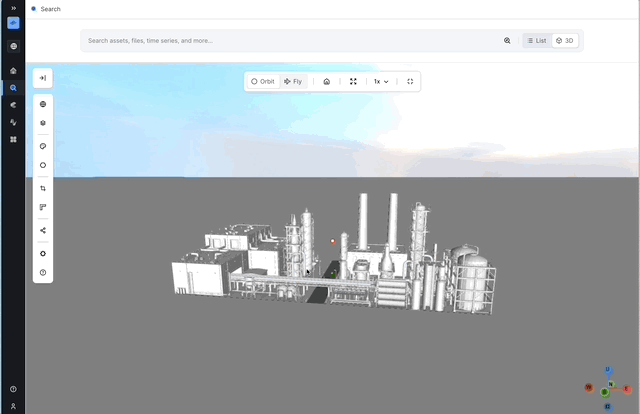
Slicing in x, y, and z direction in 3D: Many users have had trouble when trying to look at specific parts of 3D models. The inability to precisely crop and slice planes has led to inefficiencies and limited insights, making it challenging to focus on the areas that matter most. To address these issues, we are introducing new tools for cropping and slicing 3D models along the X, Y, and Z planes. This will enable users to conduct detailed examinations of specific 3D sections, enhancing their understanding of complex models and reducing the time required to isolate areas of interest, allowing for faster analyses.
Industrial Canvas
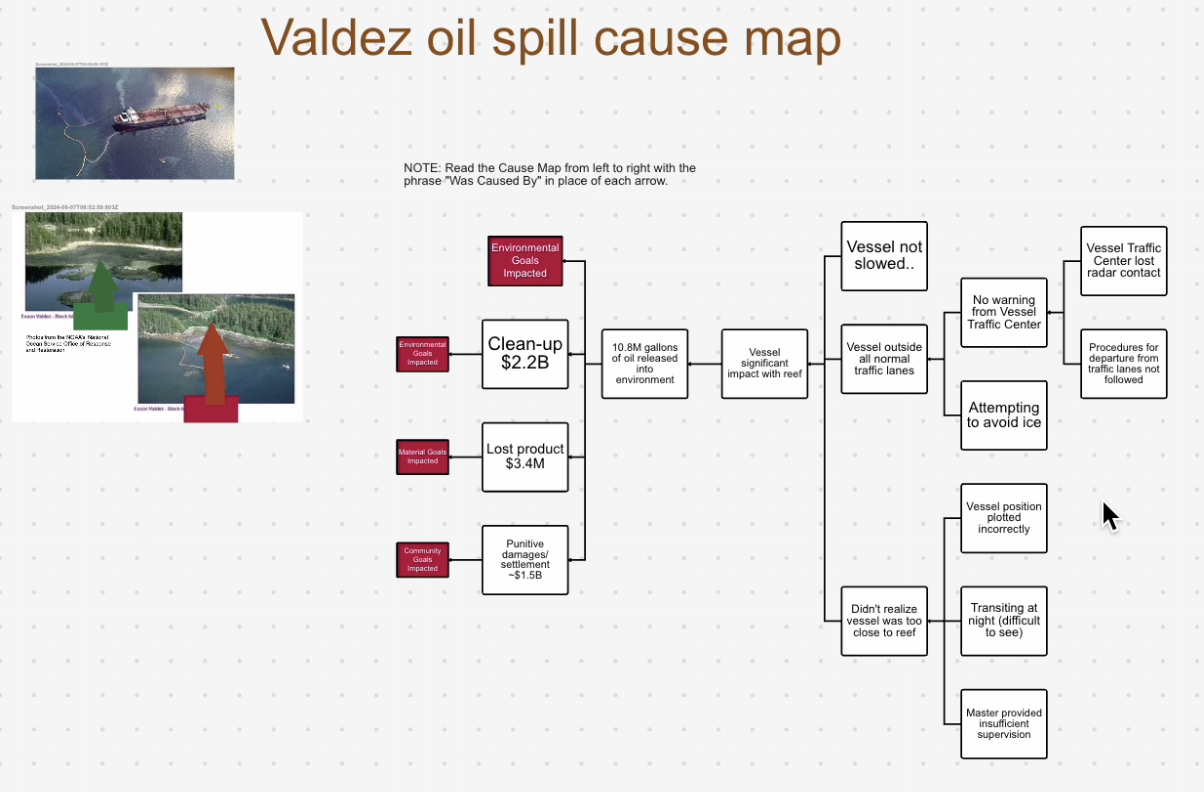
Dedicated cause map diagram (Beta): Our users have expressed that they are spending more time managing tools and data, rather than focusing on the root causes of issues and analyzing them. This limits their ability to derive insights and slows down their time to value. To address this challenge, we are excited to introduce the ability to easily create cause maps directly in Industrial Canvas, where all necessary data is readily available as evidence for approving or rejecting a hypothesis. This feature includes auto-alignment when creating cause maps and built-in status indicators to streamline the process even further.
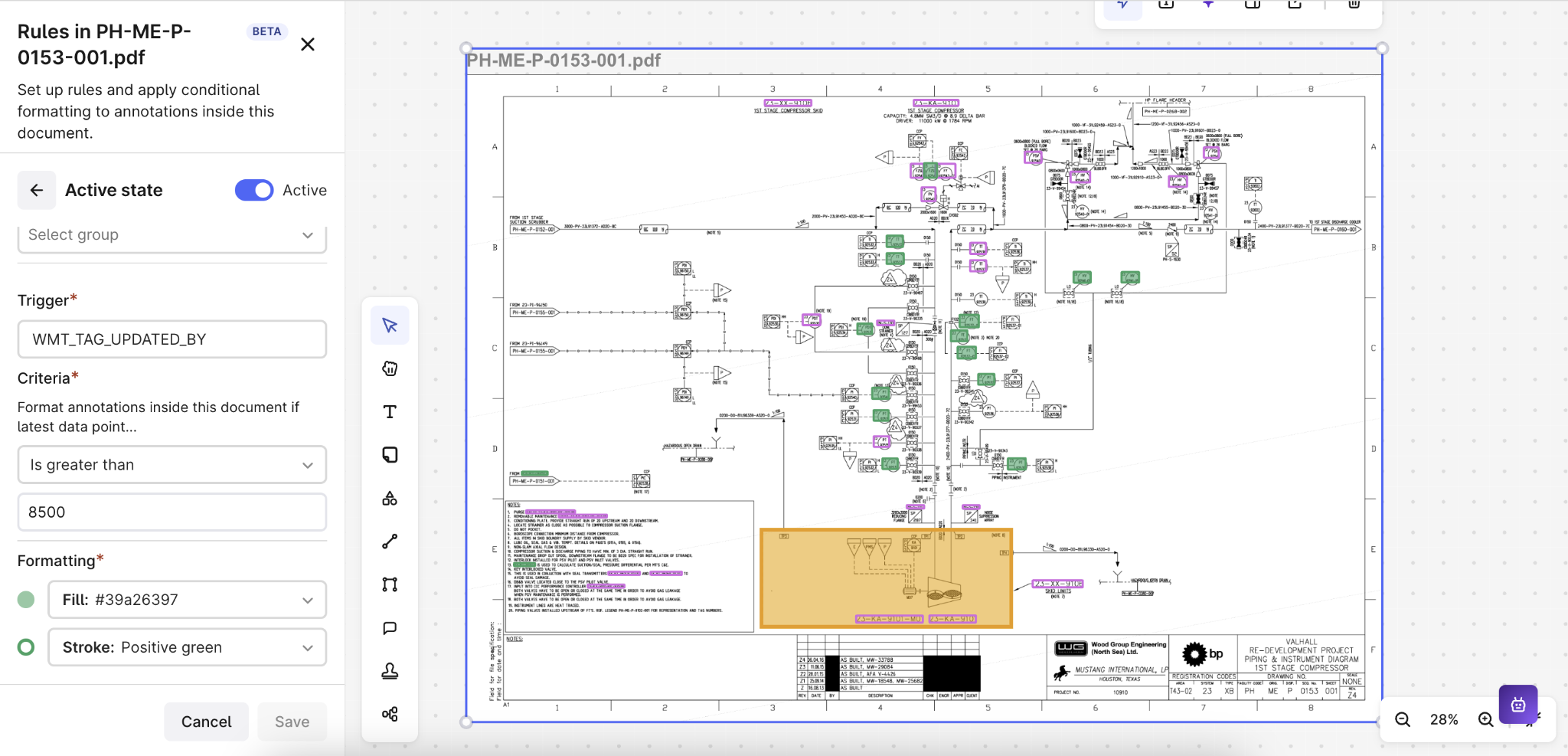
Rule based coloring (Beta): This release also includes a significant enhancement that will empower reliability engineers to better monitor the health of their plants and critical systems. Currently, this process involves checking each piece of equipment individually, which can be both time-consuming and cumbersome. To streamline this process, Canvas is introducing support for color coding assets and pipes on diagrams. This feature will categorize equipment based on several vital rules, such as corrosion rate, operating temperature, and more, providing a clear and immediate visual representation of conditions.
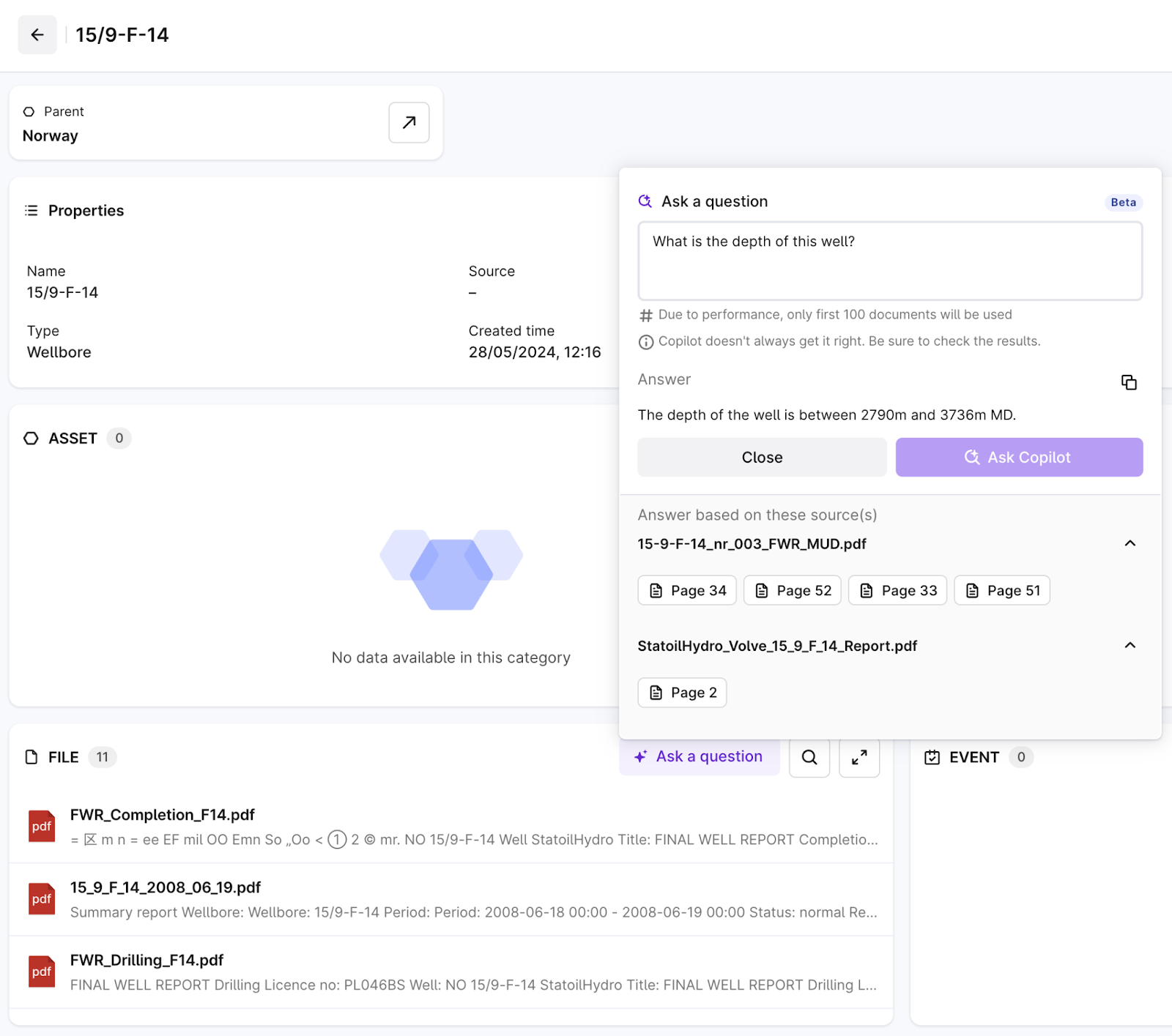
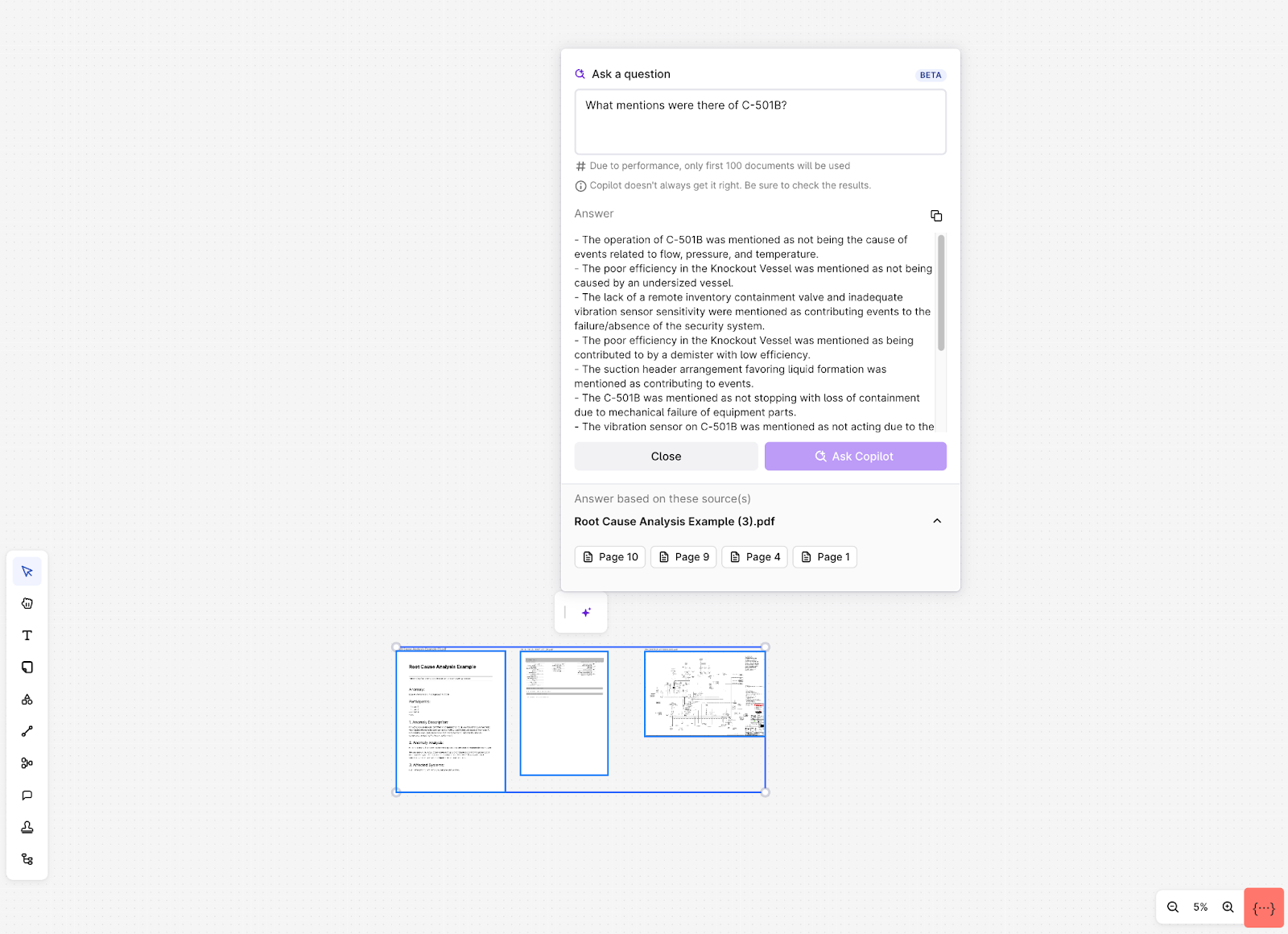
AI-improved retrieval for multiple documents in Industrial Canvas and search (Beta): It's time-consuming for industrial users to identify relevant documents and search for specific data within each document. To make this easier, we're introducing the ability to ask Copilot questions, which will search up to 100 documents simultaneously. This will allow users to use insights across multiple documents and get relevant information quickly and effectively.
Maintain
Budget awareness in turnaround scoping: Managing the cost impact of turnaround scopes can often be complex, especially as the scope evolves. By enhancing cost awareness throughout the scoping process, organizations can significantly improve the return on investment (ROI) for their shutdown projects. Users now get supported with automatically calculated costs based on work orders and resource estimates within a planned scope. This allows for real-time cost assessment as changes occur. Also, Maintain now supports the evaluation of different scope scenarios against their associated costs. This enables teams to make informed decisions and assess the financial impact of various scoping options.
Data Operations
Data Workflows
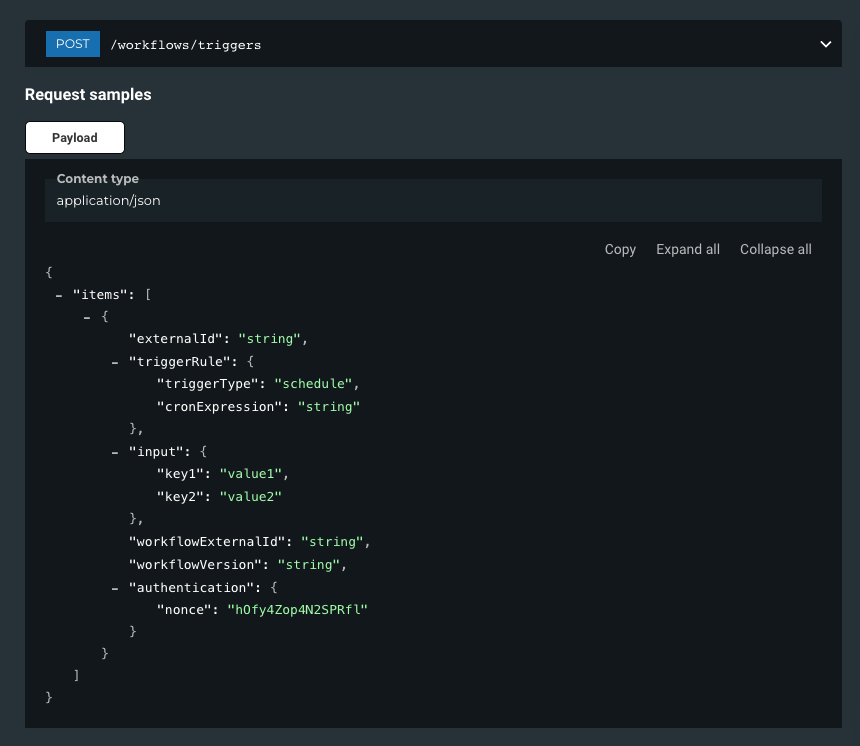
Scheduled-based triggers: Automating data workflows has often required cumbersome custom workarounds, leading to time-consuming implementation processes. Additionally, understanding the triggers behind each workflow could be complex and unclear. To streamline this, we are introducing the ability to natively define schedule-based triggers within your data workflows. This lets you include input parameters directly within trigger configurations and access a detailed run history for each trigger. Built-in triggers simplify the automation of data workflows, reducing complexity and implementation time.
Time Series
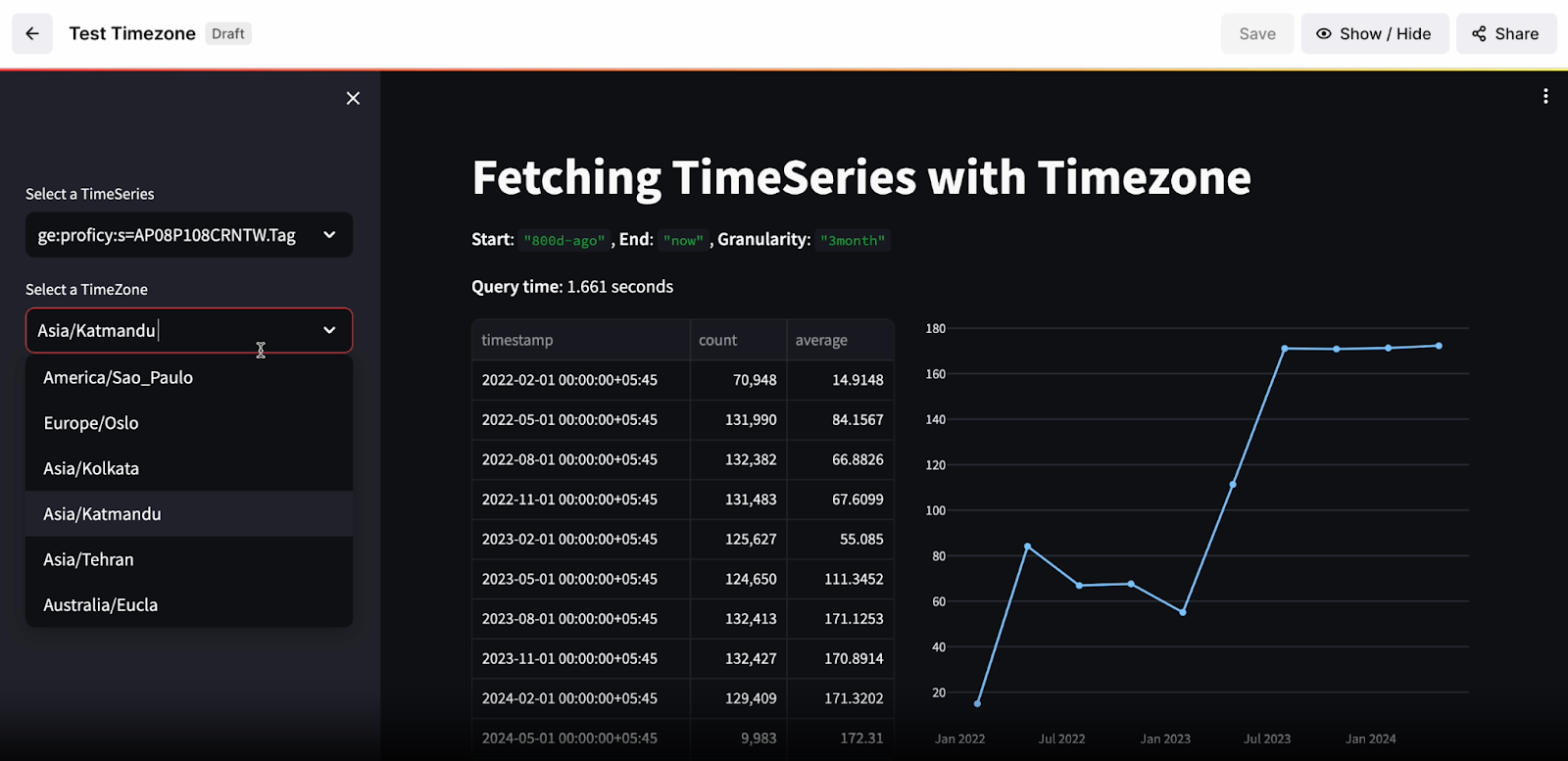
Improved data point queries: Users want better ways to get data points from time zones other than UTC. They also want to be able to specify calendar months in their queries. Previously, answering queries such as “Give me the average values for the month of February 2022, in the India time zone” was cumbersome and complicated. To facilitate easier data access, we are enabling users to retrieve data points based on a named time zone, or using specified time offsets, directly from the Time Series API. More details can be found in the API guide.
Also, we've added monthly granularity support for retrieving aggregates. The users can now specify the aggregate bucket size in months, and the API will automatically return the aggregates they want based on the start and end date they specified For more information on granularity, please refer to the API guide.
3D
Improved experience in setting up 3D content: Users have faced challenges with the current 3D content upload and configuration process. This has led to prolonged time to value and limited scalability for projects relying on 3D content. To address these issues, we have revamped the 3D sub-application to provide a simplified experience. This enhancement streamlines the upload and configuration process, making it easier and more intuitive.
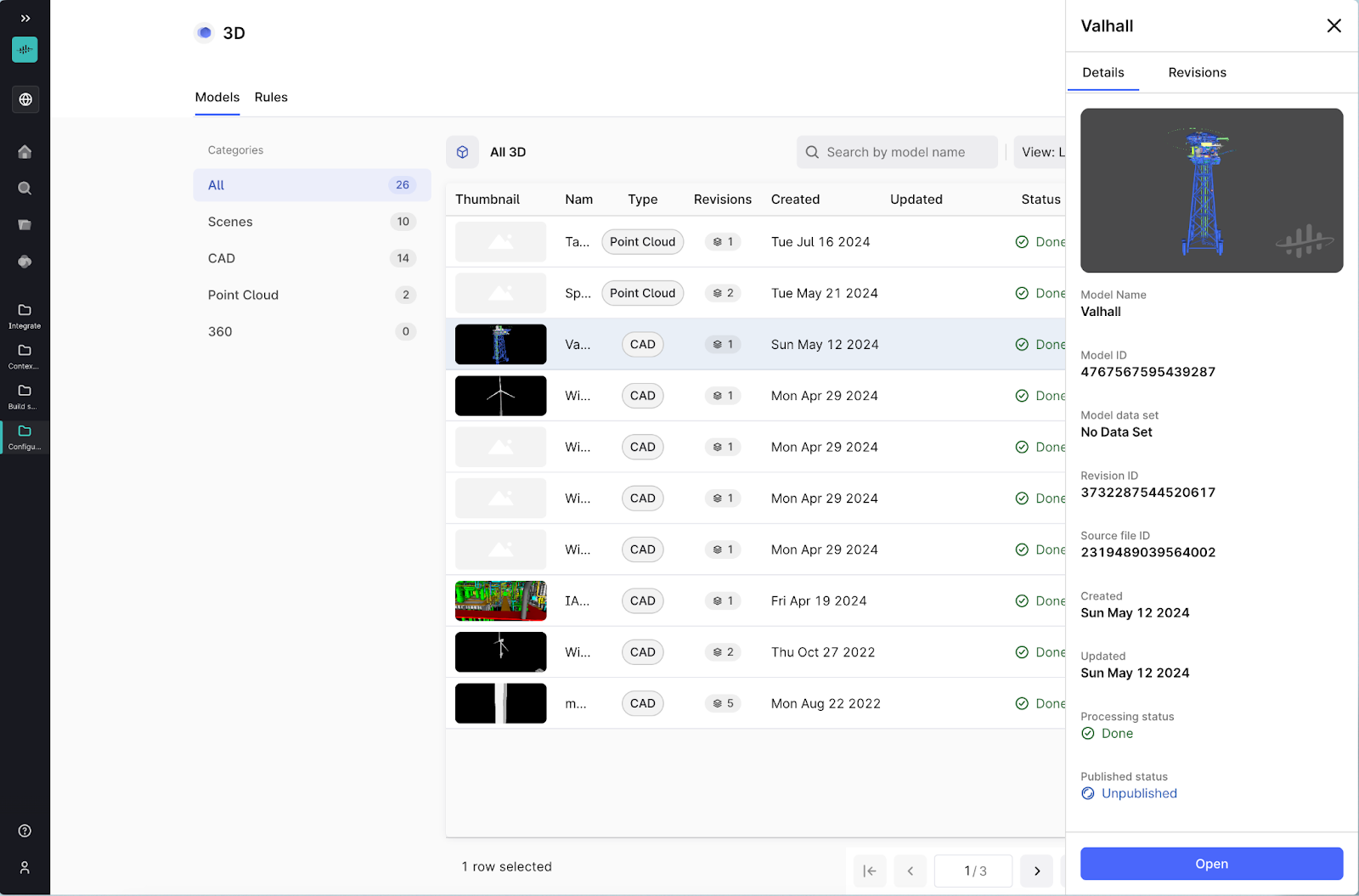
Extractors
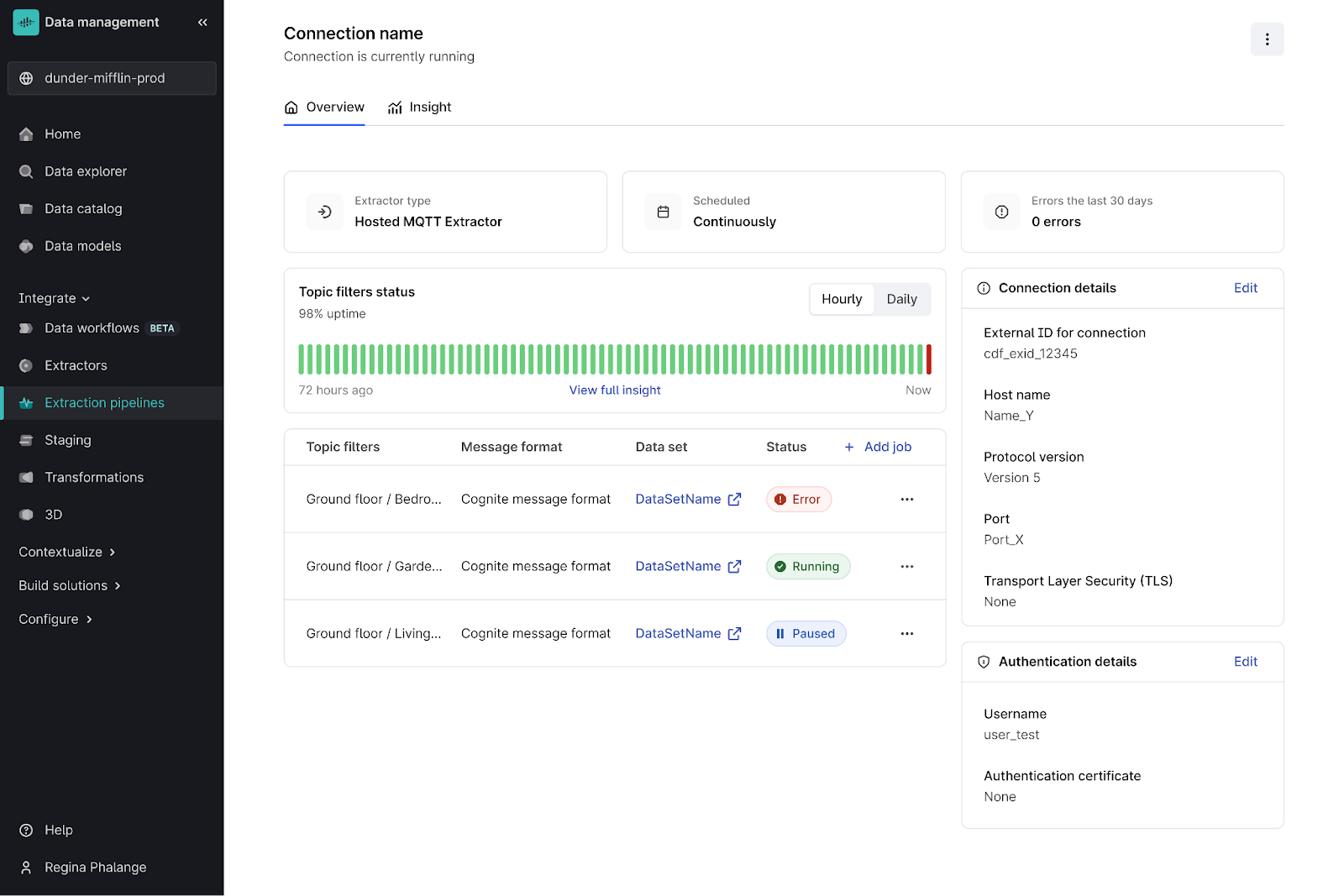
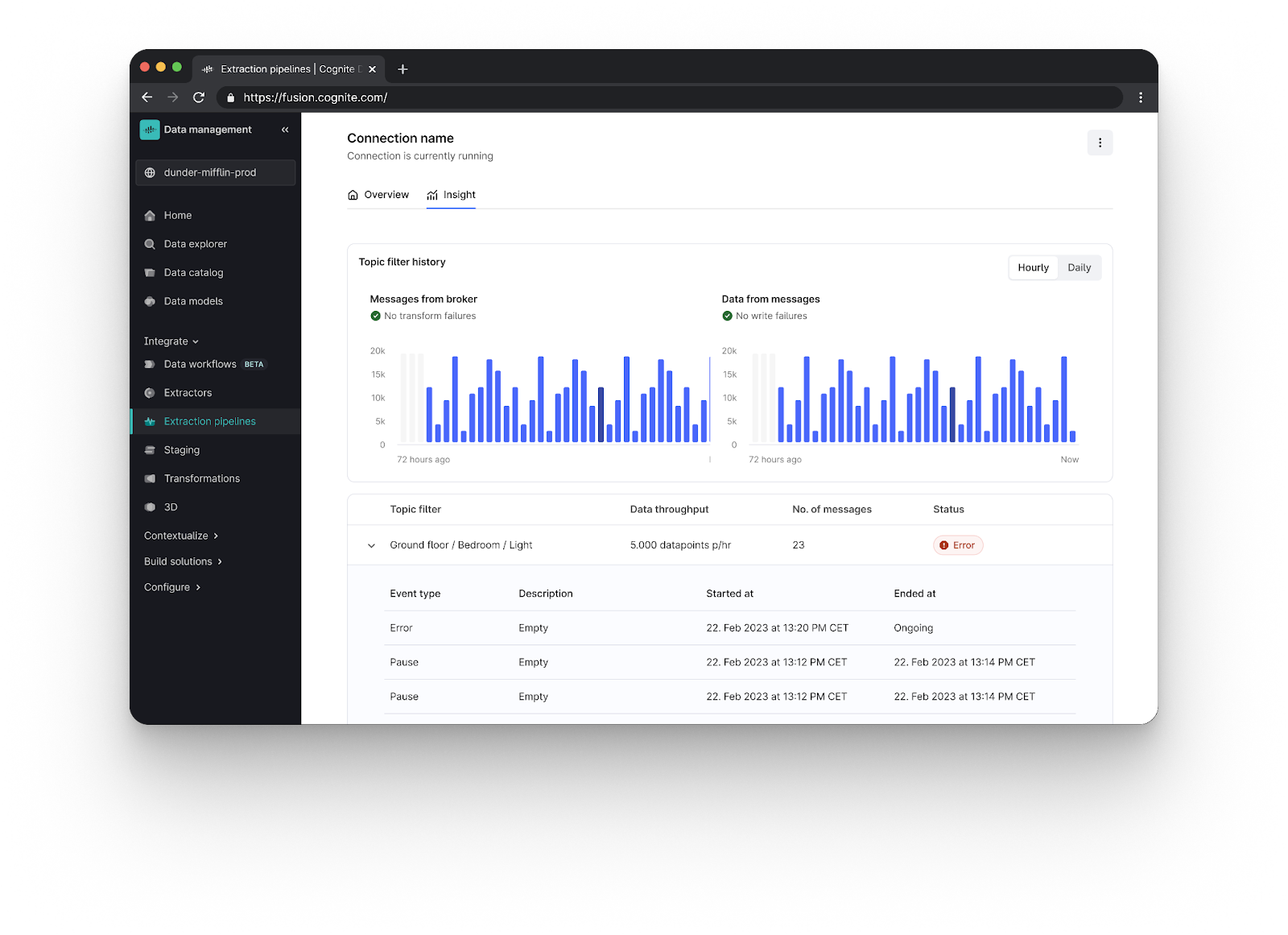
Hosted extractors for MQTT and Kafka: Traditionally, Cognite extractors have only been deployed on-premise, and operate on a schedule. This deployment and management model has represented significant management challenges for local IT teams. The maintenance and management of these extractors can be burdensome, consuming valuable resources and time. In this release, hosted extractors begin to address these problems. Cognite is now taking on the burden of maintenance, updates, and management from local IT teams. This will significantly improve the flow of data from source systems to Cognite Data Fusion.
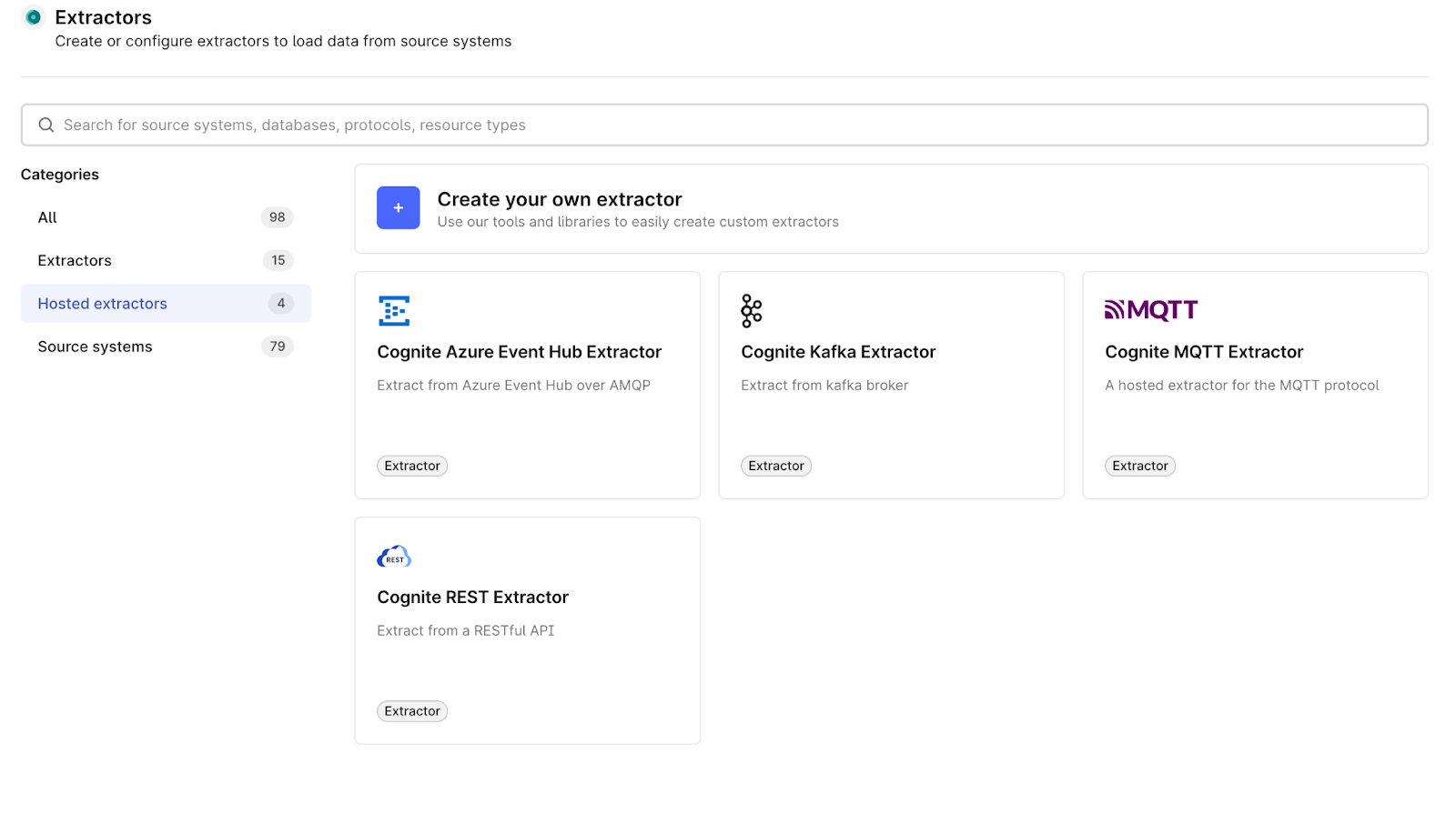
Hosted extractors for REST, and Azure Event Hub (Beta): Extractors can pose a considerable management challenge, particularly for local IT teams, leading to resource allocation and management issues. To address this, we are introducing hosted extractors. This transfers the responsibilities of maintenance, updates, and management from local teams to specialists at Cognite. The cloud hosted REST extractor facilitates data extraction from source systems behind a REST API, enhancing accessibility and integration.The cloud hosted Azure Event Hub extractor streamlines data extraction processes from Azure Event Hub, providing efficient data management and flow.
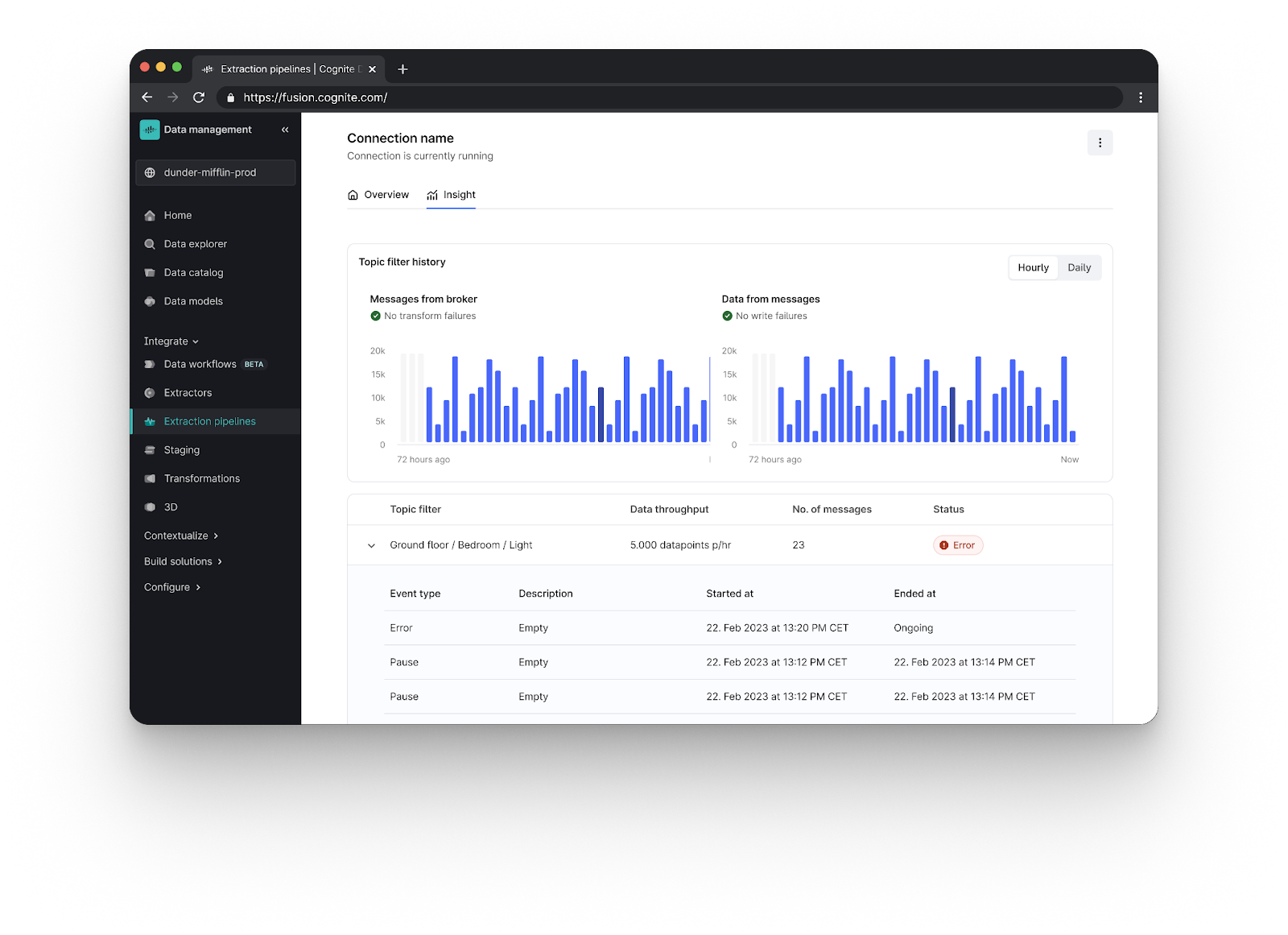
Write back to SP source system (Beta): Users managing maintenance operations through Cognite InField have faced challenges due to the existence of two “sources of truth” for specific SAP data. This requires two updates after field maintenance operations, one in Cognite InField and one in the SAP source system. This leads to inefficiencies and potential discrepancies. We're excited to announce the implementation of a bidirectional data flow that enables seamless synchronization of SAP notifications data between SAP S4HANA and Cognite Data Fusion. Now, when Cognite applications update SAP notifications, these changes will automatically reflect in both systems.
We believe this enhancement will streamline workflows, improve data accuracy, and improve the overall user experience for maintenance operations.
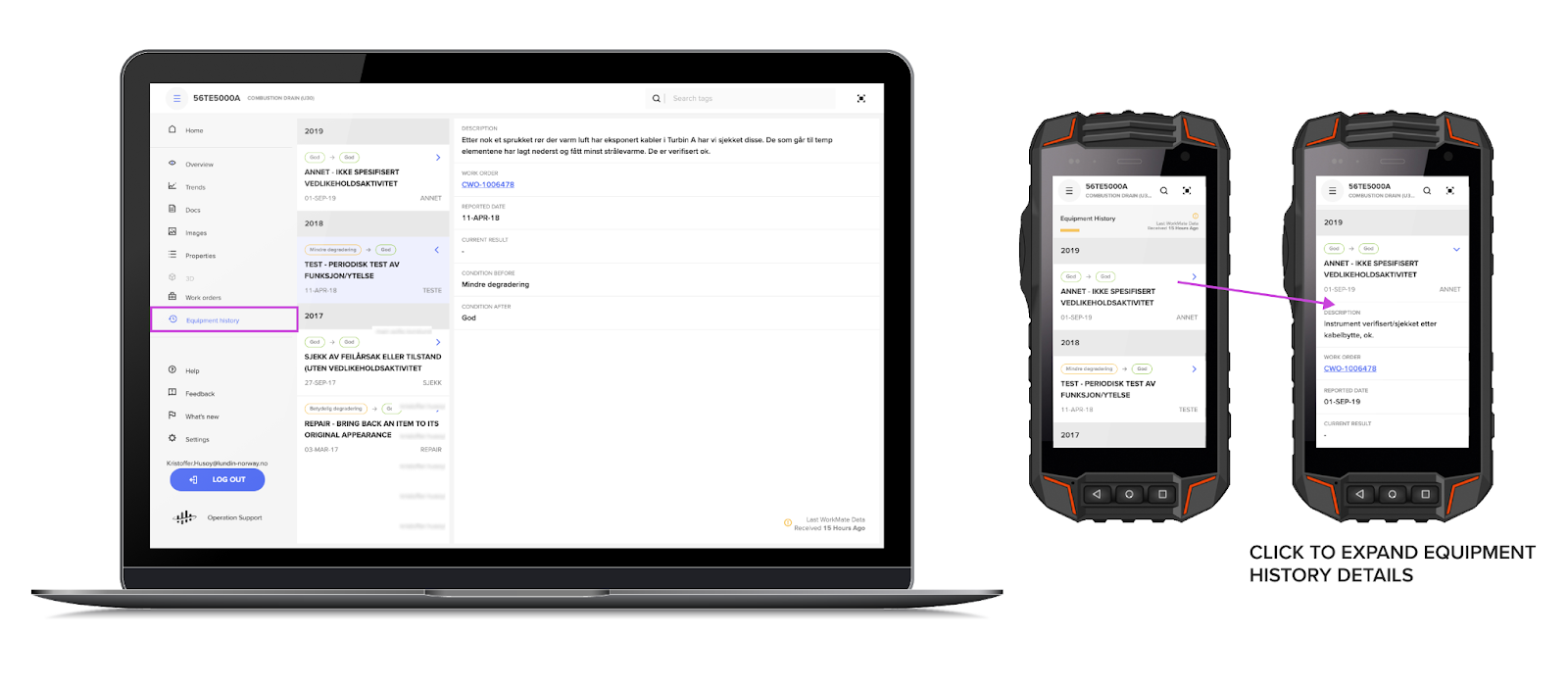
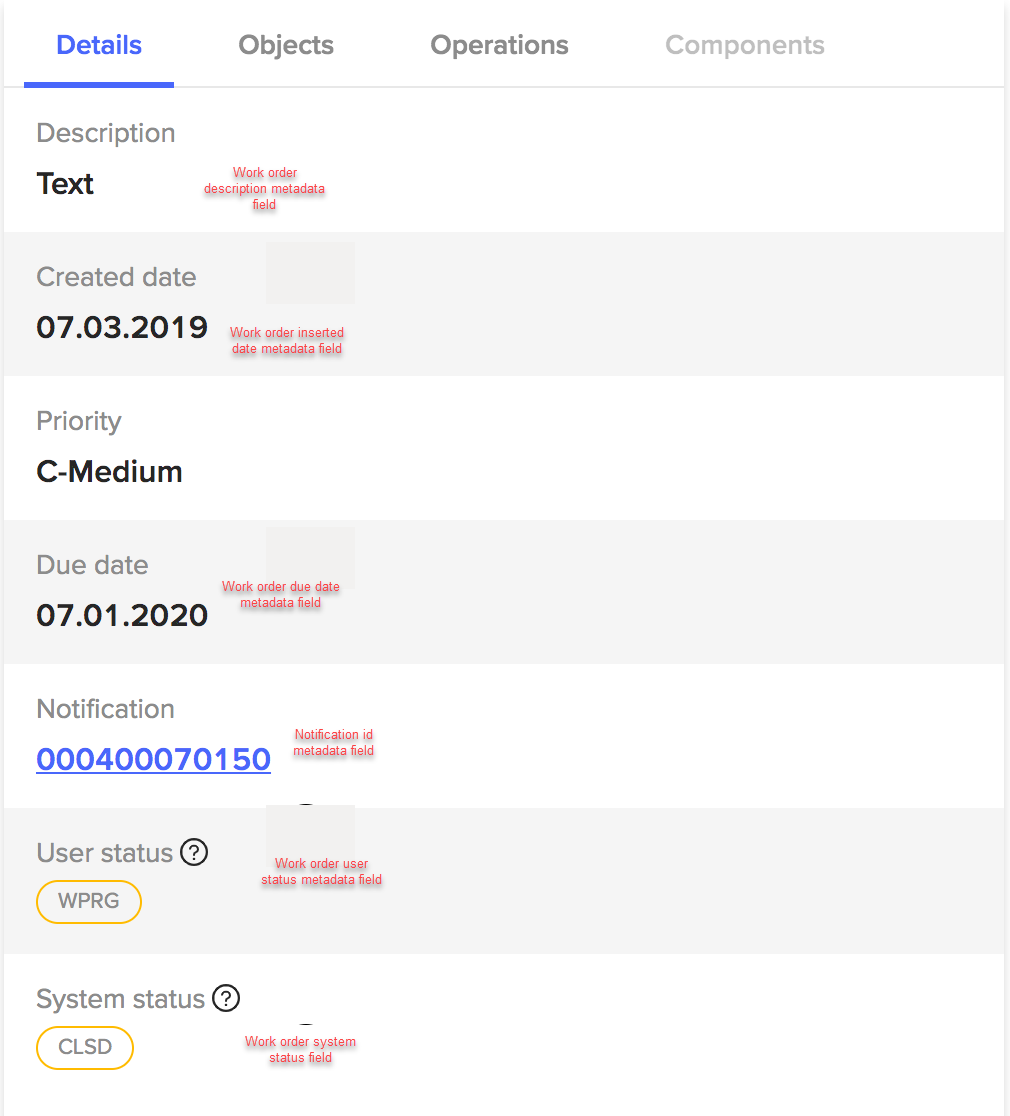
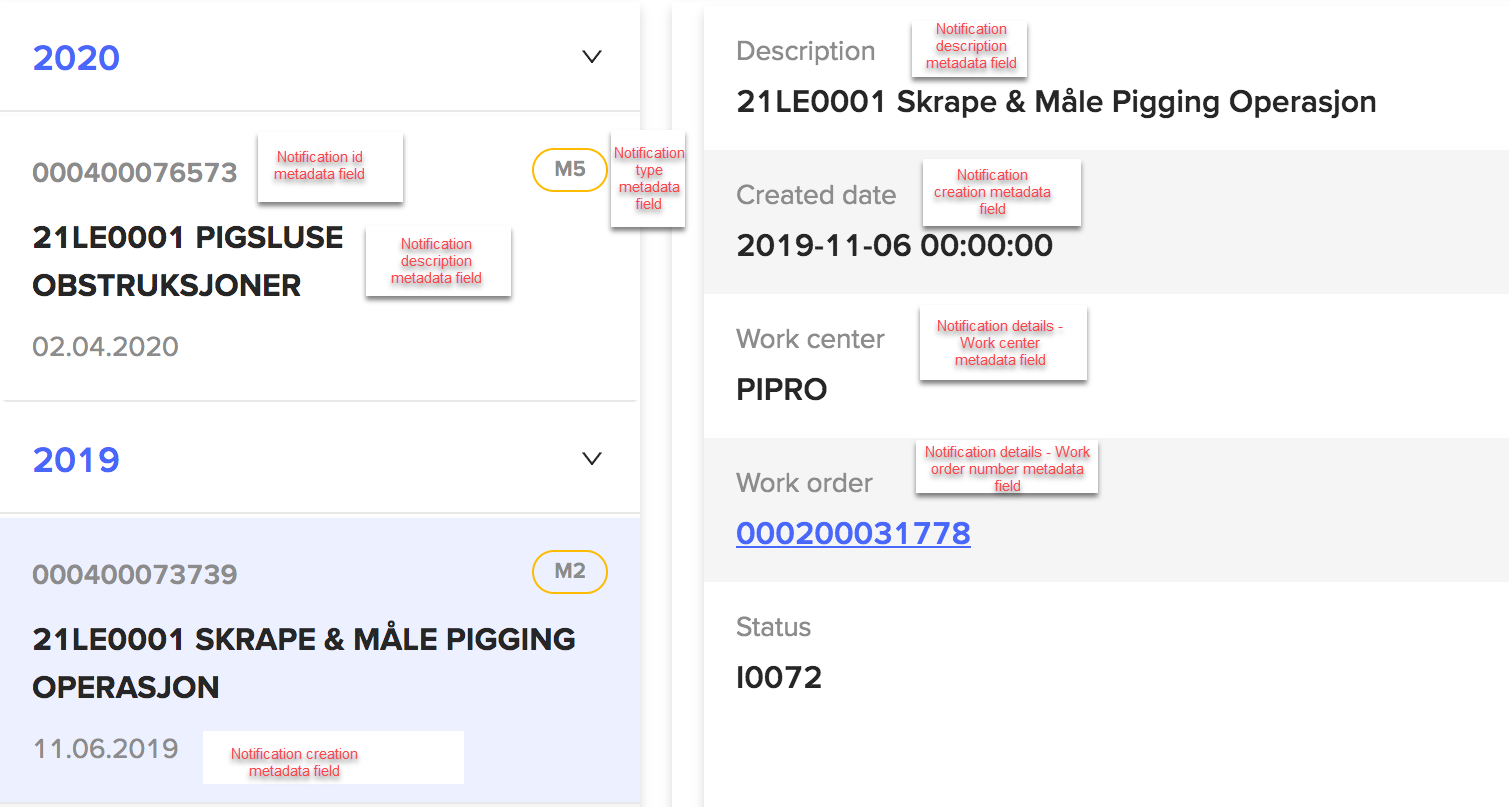

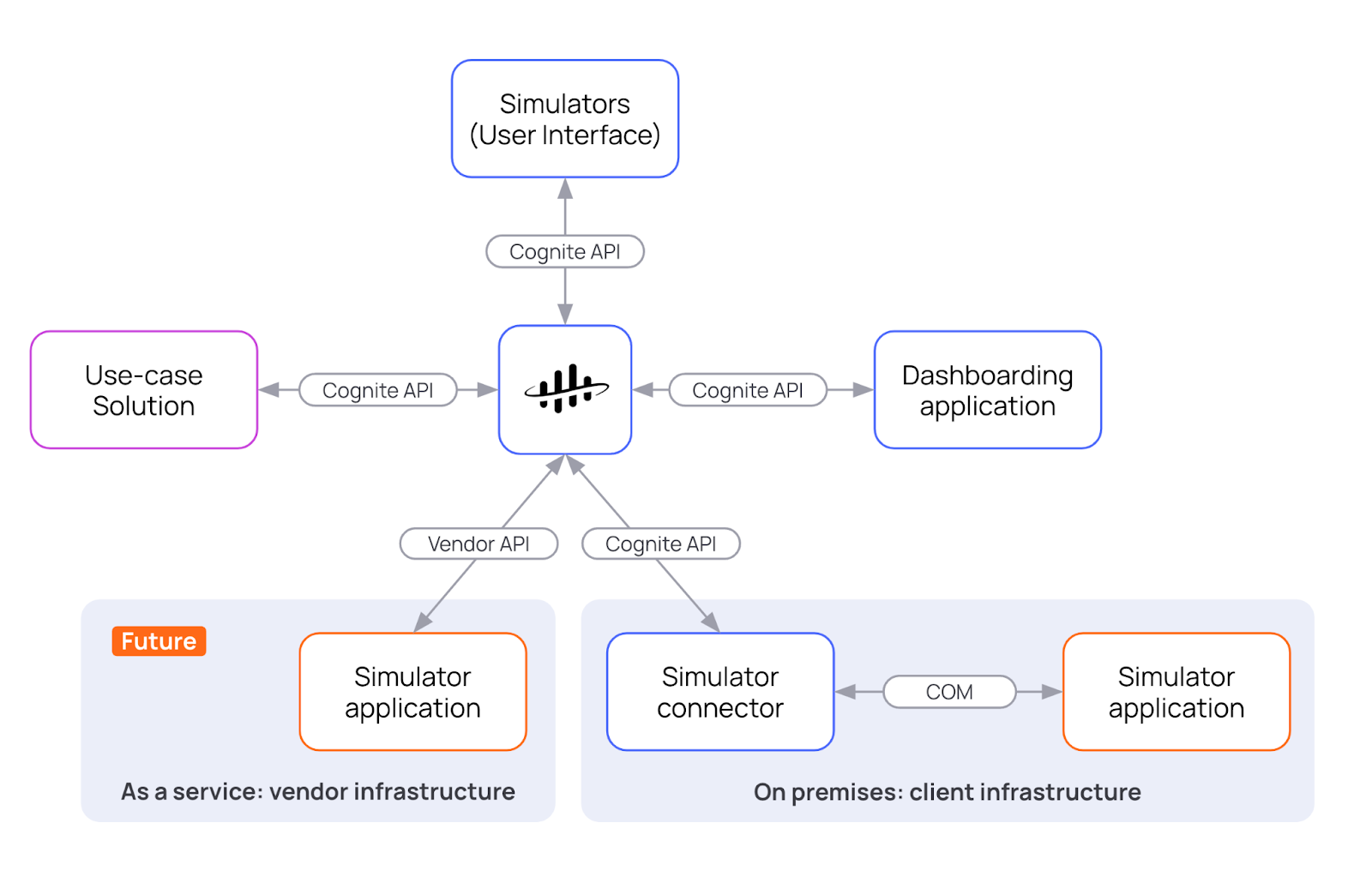
Simulators and connectors
Simulator integration service (Beta): Industrial organizations often miss opportunities to generate valuable insights by combining simulators with plant data. The traditional process of integrating these powerful tools is usually expensive and time-consuming, which leads to underutilization of simulators in production applications. We're proud to introduce a vendor-agnostic service that supports integration with simulators from multiple vendors. This includes out-of-the-box connectors to industry-standard simulator tools, ensuring streamlined integration processes, as well as Simulators API that allows for programmatic interaction and orchestration of simulator resources. This integration enables real-time asset performance optimization, predictive maintenance, and what-if scenario analysis, driving significant operational improvements.
Gap connector (Beta): Oil & Gas operators have faced challenges in integrating the PETEX GAP simulator with their ET, OT, and IT data. This limitation hinders their ability to leverage GAP's sophisticated multiphase network optimization capabilities and build process twins in cloud-based, real-time applications. Cognite introduces a native GAP connector within Cognite Data Fusion. This enhancement allows for seamless integration of the GAP simulator, alongside efficient handling of GAP and PROSPER dependencies. This integration will significantly reduce both the time and costs associated with building digital Process Twins using Cognite Data Fusion, streamlining your workflows.
Development of new simulator connectors (Beta): Developing simulator connectors for different vendors and disciplines has historically been challenging, time-consuming, and costly. This limitation has limited customers from fully using their preferred simulation tools within Cognite Data Fusion. To address these challenges, we are introducing the Connector Developer Toolkit, which includes:
- Detailed Documentation: Comprehensive guidance for creating new connectors tailored to your specific needs.
- Library of Reusable Logic: A collection of reusable connector logic and building blocks to streamline development.
- Open-Source Example: Access to a functional example of a connector, aiding developers in understanding best practices and implementation.
