

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


What makes Cognite unique? Why is partnering with Cognite the best investment of your time and resources?
This is a 3 part series where
These posts are for those of you who are new to using Cognite Data Fusion and want to understand how we approach the challenges of working with industrial data without losing focus on delivering business impact. The topics we discussing are:
-
What is Cognite Data Fusion and why did we build it? (Last post)
-
Data modeling grounded in business impact (This post)
-
The opportunity cost of custom building your industrial data platform (DIY)
In the first Why Cognite post, Ben and I shared why we built Cognite Data Fusion. The short answer, industrial companies need simple access to complex industrial data. The reason, most operations teams have many business opportunities, but are struggling to effectively use data to improve production.
For too long, our industry has lacked an approach that can combine both domain and data expertise into one product to power solutions across many improvement areas (asset management, energy reduction, connected worker, etc.). Traditionally, operations have been forced to buy point solutions from vendors that only meet 70% of their needs, and IT has been tirelessly trying to build a solution specifically for operations using generic tools and services. Neither has proven effective at scale.
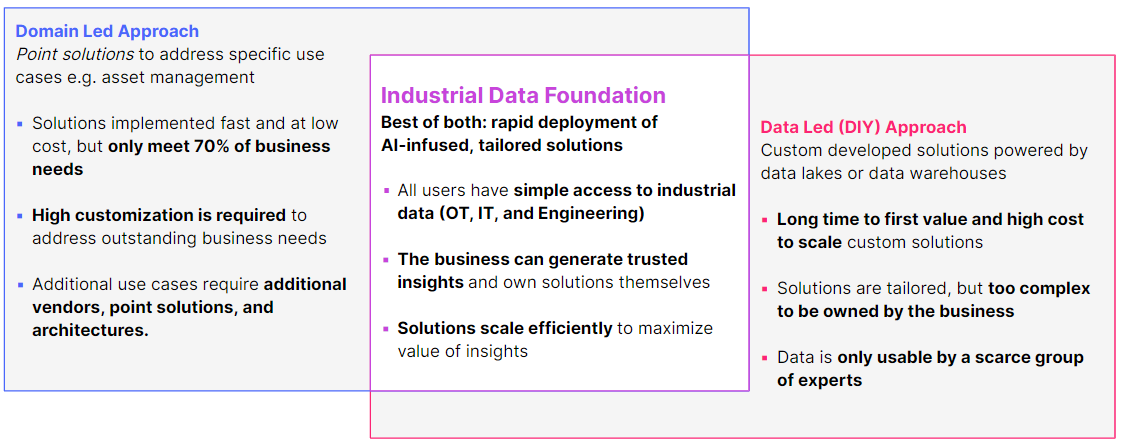
An industrial data foundation can infuse domain and data expertise into one product
To transform operations, industrial companies need to build 10s of data-driven solutions and then scale them across 100s of production facilities. Our industry needs an approach that can combine domain and industrial data expertise into a single product, enabling reuse of data to rapidly develop many tailored solutions.
Data modeling becomes incredibly relevant when we think about how to efficiently reuse data to support many use cases. To simplify how Cognite approaches this topic (as there are many books that cover data modeling in much greater detail), we think about data modeling at 3 levels:
-
Solution Data Model - models that support specific solutions
-
Domain Data Model - a foundational model abstracted from data sources
-
Source Data Model - the models that exist within every data source
Illustrated in the slide below, each model serves a specific purpose as data is made available, meaningful, and valuable to your organization.
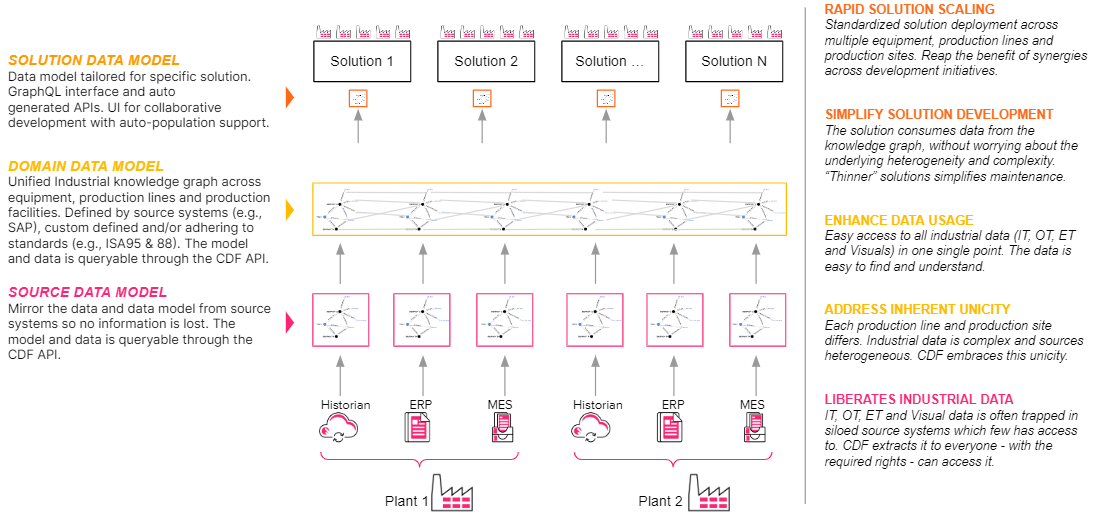
Cognite Data Fusion provides different layers of data models
Solution Data Model
To deliver business impact, you need Solution Data Models. These offer a solution-specific schema and the data within it (think “what data do I need to populate a pump performance model”). There will typically be one solution model per domain (e.g. operations, quality, maintenance, etc.) or one per solution (e.g. asset performance use case).
In Cognite Data Fusion, this functionality is provided using templates. This secures a separation of concern between the schema a solution may need and the underlying data, enabling decoupled versioning and change management across plant and solution needs. This way, it's possible to scale solutions across plants and simultaneously update the solutions in a controlled manner across the fleet of plants and equipment. For more information about the Templates capability of Cognite Data Fusion, see the product documentation.
Domain Data Model
You need one or more Domain Data Model(s) to capture the specific solution areas – e.g., plant-specific, production line-specific, or equipment-specific data models – and ontologies needed to solve the business problems.
The Domain data model can be created based on information in source systems (e.g., Asset hierarchy and production flow in SAP), or one can have more custom definitions adhering to industrial standards (e.g., ISA88 and ISA95).
This is the foundational data model and solution data models use subsets of the larger domain data model to solve specific use cases. In this way, the domain data model provides reusability of the data as new solution models can continue to be created using the foundational domain model.
Source Data Model
Closest to the data source (see Source Data Model in the illustration), Cognite Data Fusion is persisting a carbon copy of the data as it is available with full source system metadata from the source system. This is the RAW staging area of Cognite Data Fusion, serving as an on-platform data lake, mirroring the data and possible data models from individual source systems.
The benefit of this layer is to support ELT rather than requiring to revisit the source systems should any new transformations be required on raw data from one or multiple sources, as is the case with a conventional ETL pipeline. In other words, transformations can be performed at will without loading any source systems, which often causes distress to them (as industrial source systems have not been designed for high query loads.)
The reason Cognite has taken this approach to data modeling
"The diverse and distributed nature of IoT solutions means that a traditional, one-size-fits-all, control-oriented approach to governance is insufficient. Organizations need to be able to apply different styles of governance for different types of data and analytics" (Source: Gartner, Successful Internet of Things Initiatives Require Adaptive Data and Analytics Governance, June 2020)
The different data product layers enable distributed responsibility of those close to the data to provide consumable data products (i.e., easy to find, easy to understand, easy to trust). It also fosters collaboration between different domains (e.g., Solution architects, Data Engineers, Solution Developers, and Solution consumers) across organizational levels (e.g., the IT and analytics teams on the plant, regional and global levels).
With Cognite Data Fusion, different system owners (e.g. ERP, MES, and CMMS), the various domains (e.g. operations quality, maintenance, etc.), and solution owners (e.g. back to our asset management solution) can have responsibility for their data products. This is important as the data product serving a specific solution requires a different schema, data, and quality than a domain data product.
While it is crucial that solution owners can set specific requirements on their data product, it is equally essential that global teams can enforce global data standards, e.g., global naming standards, global data quality rules, and global documentation standards. Such global data standards typically cover a subset of the total data available, with strict and centrally controlled governance. From the ERP world, this is generally data such as customer name, customer address, and other core data with strict governance.
For Industrial data, this is a less-established concept. Thus, it's important to start small and focus on what information drives immediate value and is common for all production lines and equipment. When this model is defined, it may easily be reflected in Cognite Data Fusion, and schema coherence for the data in Cognite Data Fusion is then governed as a data quality parameter to make sure that all data comply with the data expectations. This can be used to check compliance with technical standards (e.g., naming of objects, what metadata should be present, and more). It may also contain high-level data quality rules, e.g., empty values, inconsistency, and multiple formats.
This flexible, federated governance approach strongly contrasts with the traditional “master data management” approach. The master data management approach has not scaled due to bottleneck challenges in central data management teams, and the focus on central government has been disconnected from business impact. This has resulted in decisions being made based offline on ungoverned Excel spreadsheets. To truly deliver business impact at scale, we need an approach to data modeling that:
-
Provides simple access to all complex OT, IT and engineering data
-
Enables the business to generate insights and own solution
-
Scales efficiently to unlock the many business opportunities across production
I always appreciate feedback and discussion, so I hope you’ll share your thoughts at the bottom of this article. Next week we will discuss The Opportunity Cost of DIY.