Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support
Hello,
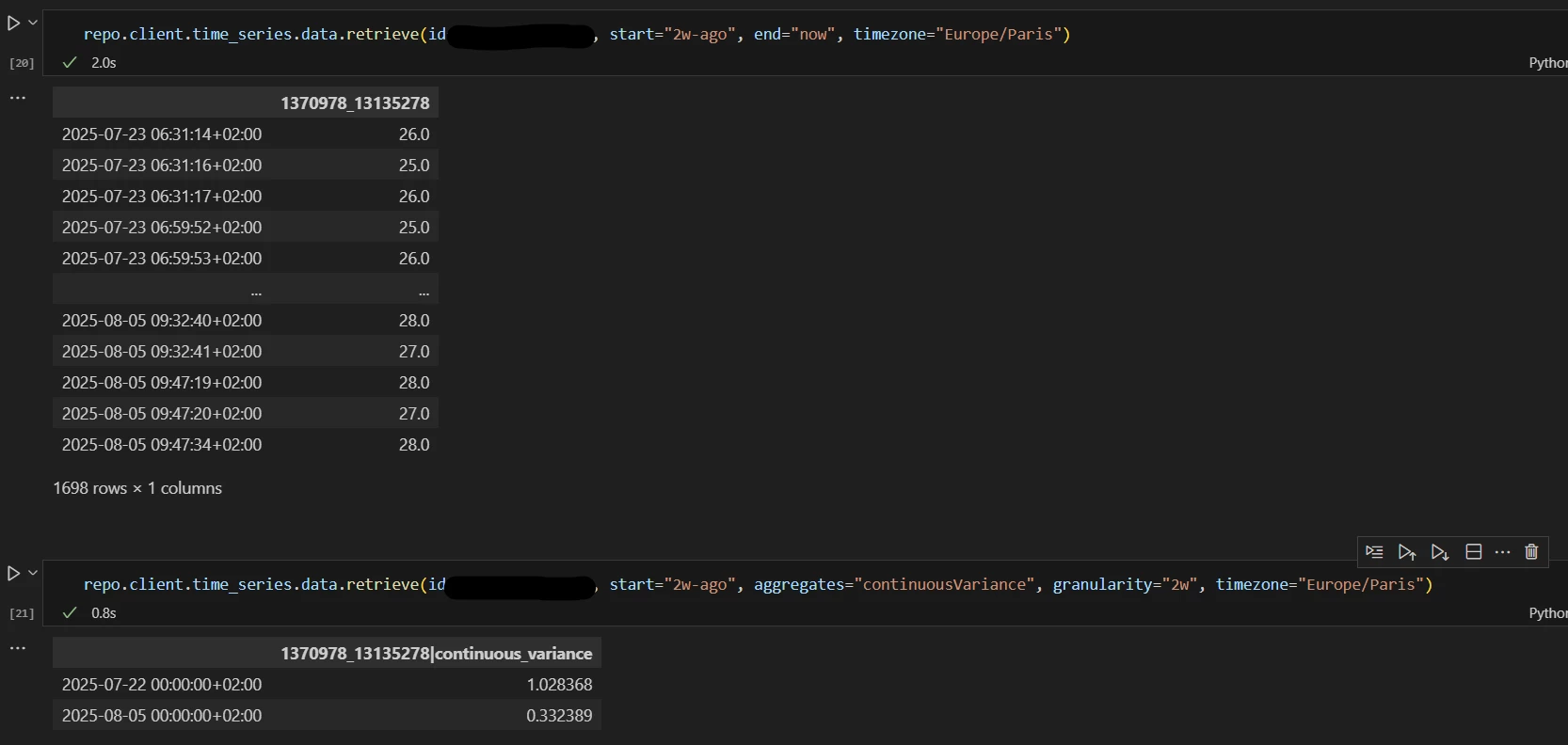
I’m looking to compute the standard deviation of a timeseries on the fly with synthetic timeseries.
I expected to use this pseudocode formula : sqrt(avg(pow(TS{externalid}-avg(TS{externalid}),2))) with endpoint :
client.time_series.data.synthetic.query(
expressions=expression,
start="2w-ago",
end="now"
)Unfortunately, avg expect at least 2 inputs, I try to switch to aggregate feature but I found it available only for timeseries, not synthetic timeseries.
expression = '''
sqrt(
avg(
pow(
ts{ID} - ts{ID, aggregate="average", granularity="14d"},
2
)
)
)'''Do you have any tips or workaround to compute this value when “start” value changes ? Dont hesitate to explain
I'm open to any opportunity to calculate this metric using another method.
Thanks in advance,
Pierre
edit : I find this function in additionnal library : Rolling standard deviation of data points time delta — indsl 8.7.0 documentation but i’m looking for a answer without additionnal package if it’s possible.