Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


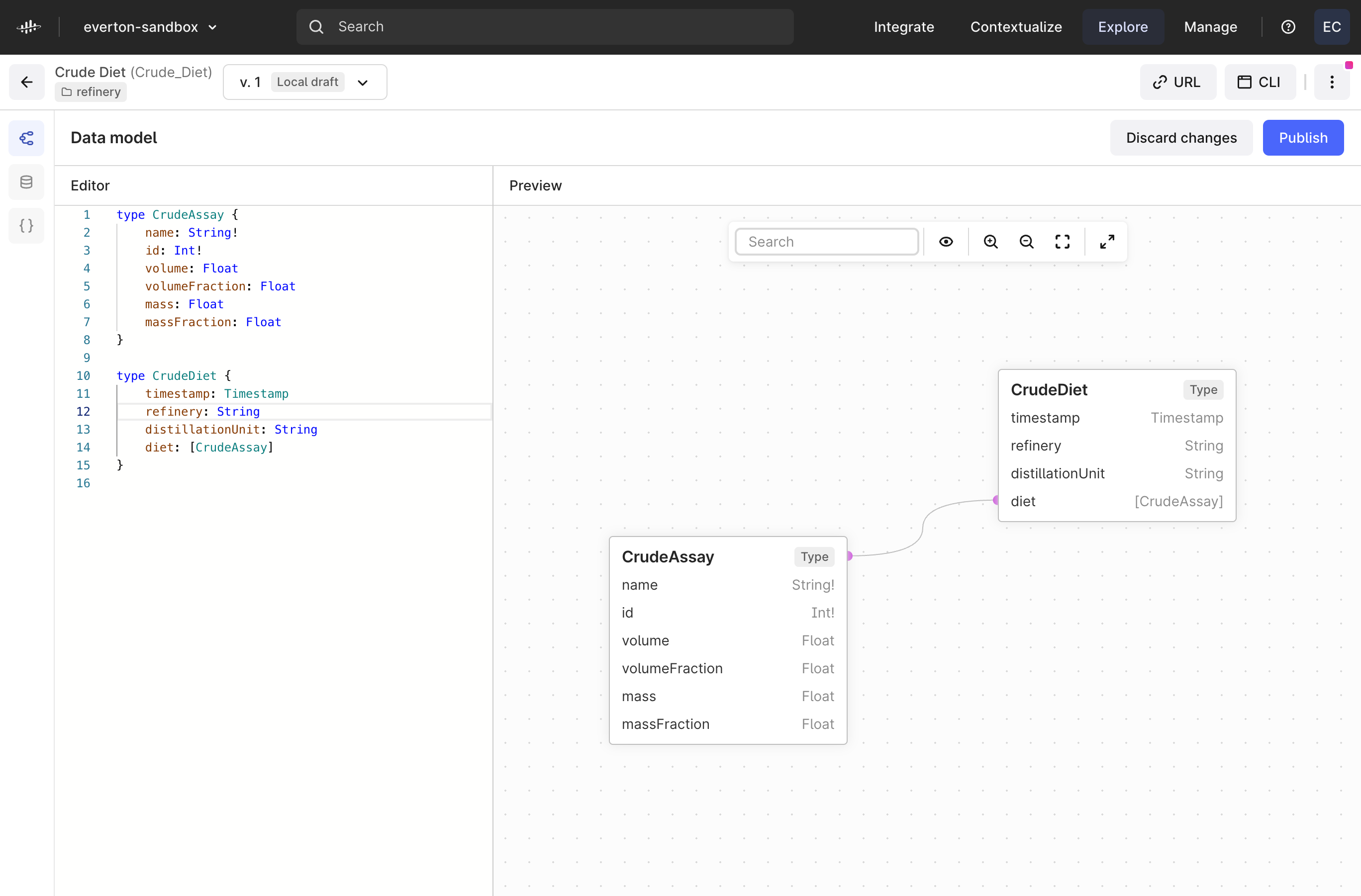
We have a unique use case where there are data points collected from PI server for refinery plant and alongside, we have other refinery data like Crude assays, Diet, Mass Balance. All these data points (in tabular format) are collected and then some formula is applied across to get properties (like swing cut %, CBLISS, Vol%, etc.) and some derived tables are created. Then some input feed is made from the actual data sent to a Petro-Sim tool (math simulation tool/modeling) and then output from that tool is collected and stored. All these data wrangling is done and finally charts are finally made for some 50+ crude product variants to measure yield tracking (Actual data, non-linear model data, linear model data). As per design, we are planning to use the CDF raw tables and then do all the computations and create derived raw tables to fulfil the purpose. Then use Petro-Sim connector and then store the data output from the model tool as well in raw tables.
So, we don't tend to see the typical CDF style data construct like Assets, Sequences, work-order, maintenance-data, files, events, labels 3D diagrams etc. So, when we see the data-model, it is very unique.
Can someone suggest if our approach to implement in CDF is right and if our interpretation is wrong?
Please share pointers and also on some guides on how to design and architect a solution model.