Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support

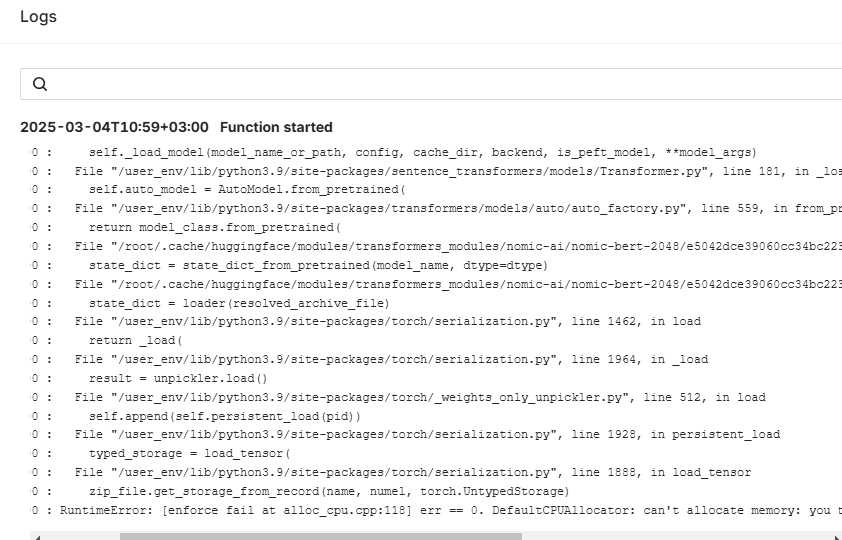
I have created a function that was configured to 5G of memory and 2 CPUs to run huggingface AI model (py311). Deploying the function went fine. However, when running the function it throws this error.
RuntimeError: [enforce fail at alloc_cpu.cpp:118] err == 0. DefaultCPUAllocator: can't allocate memory: you tried to allocate 9437184 bytes. Error code 12 (Cannot allocate memory)