

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support
Introduction
In this tutorial, we'll explore one method to stream data from Cognite Data Fusion (CDF) to Power BI. While Cognite's Power BI connector serves its purpose, it has limitations, especially in terms of live data streaming and handling complex queries. Here I am presenting an alternative approach using "push" or "streaming" datasets in Power BI, bypassing the limitations of Cognite's Power BI connector by utilizing a scheduled job to fetch data from the CDF REST API and push it to the Power BI REST API.
1) Understanding the Limitations of Import mode Connectors
Cognite's Power BI connector it's based on OData (Open Data Protocol) and uses Power BI's Import mode. Import mode is the most common mode used to develop semantic models. This mode delivers fast performance to end users thanks to in-memory querying. It also offers design flexibility to modelers, and support for specific Power BI service features (Q&A, Quick Insights, etc.). Because of these strengths, it's the default mode when creating a new Power BI Desktop solution. It works great for business intelligence (BI) use cases, where aggregated data is refreshed with daily or at most hourly frequency.
One big limitation for data sources utilizing the Import mode is that there are limits on how frequent data can be refreshed depending on the Power BI subscription tier, which dictates how frequent one can query the data source.
2) Alternative Method Using Push or Streaming Datasets
Push (or streaming) datasets in Power BI offer a solution to the limitations of Import mode source connectors. They enable the addition of new data rows to a specified table within a dataset. The data is sent in a key-value format within an array of data rows.
Distinction Between Push and Streaming Datasets:
-
Push Datasets: This model is ideal for real-time analytics and doesn't require a formal data refresh within Power BI. Data in push datasets can be stored permanently for historical analysis and supports building Power BI reports on top of the data.
-
Streaming Datasets: Best used when minimizing latency between pushing and visualizing data is critical. Streaming datasets do not store data permanently in Power BI, limiting them to temporary storage for up to one hour to render visuals.
3) Creating a Push or Streaming Dataset in Power BI
Creating a streaming dataset in Power BI involves:
-
Go to Power BI and login with your credentials
-
Go to your workspace and click on
+ Newand thenStreaming dataset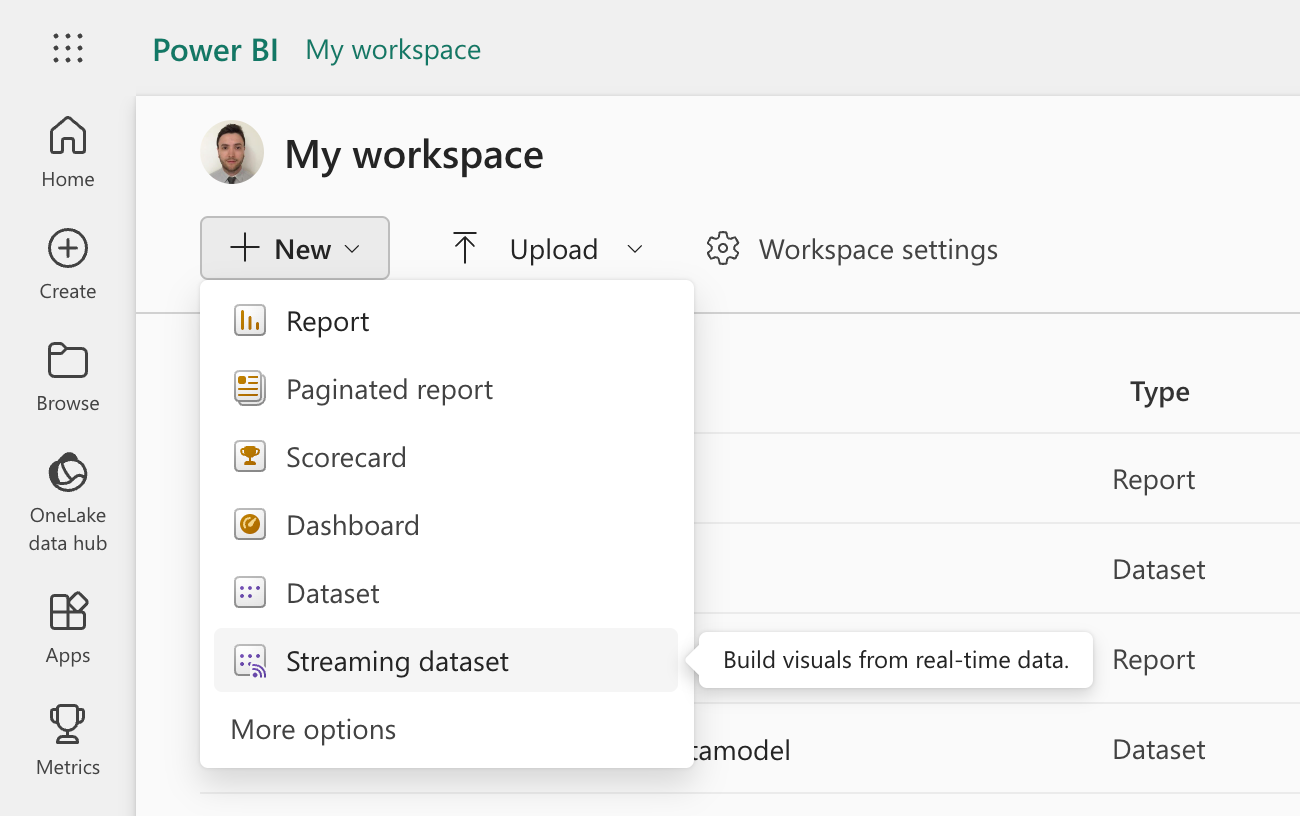
-
Select
APIas the data source and click onNext
-
Give your dataset a name and configure the desired schema (data structure and value types)
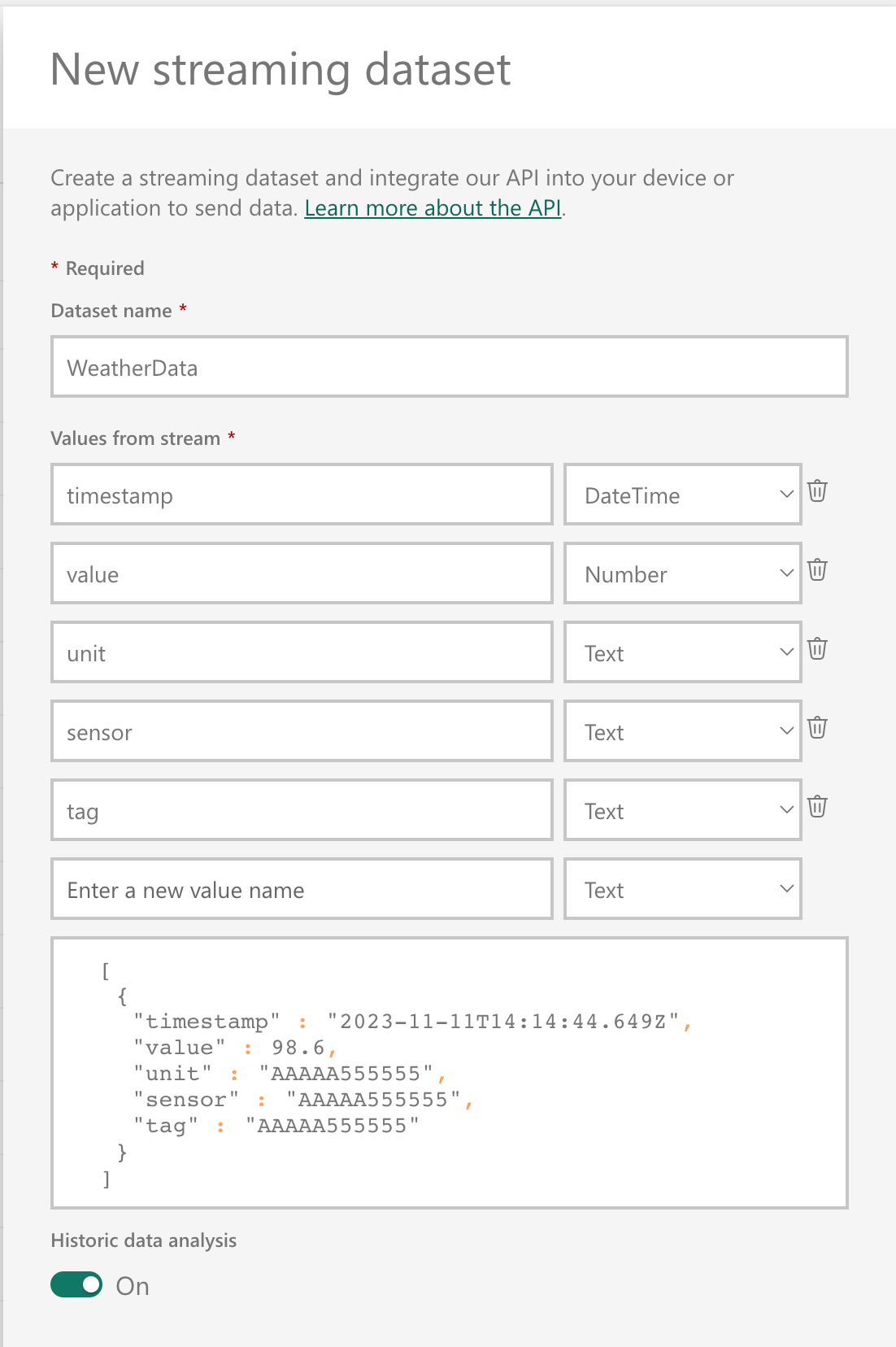
-
If Historic data analysis is enabled, a
pushdataset is created, otherwise astreamingdataset is created -
Copy the
Push URLand theSchema definitionas it will be needed later on
4) Writing code to fetch data from CDF and pushing it to Power BI
Here we will be writing a Python script that fetches the data of interest from CDF using Cognite’s REST APIs (through the Python SDK), transform the data into the schema expected by our dataset and push the data to our dataset using Power BI’s REST API.
In the example below, I’ll be using Time Series subscriptions, so on each time my script runs, it will only push new data to Power BI. Read more about Time Series subscriptions in Cognite’s documentation. The complete code for this is available in the following repository: cognitedata/push-powerbi-tutorial.
We’ll start by creating a subscription, as below. This only need to be done once.
my_filter = f.Prefix(
property=p.external_id,
value="EVE"
)
sub = DataPointSubscriptionCreate(
external_id="powerbi-subscription-test",
name="PowerBI Subscription Test",
description="Subscription for PowerBI",
partition_count=1,
filter=my_filter
)
client.time_series.subscriptions.create(sub)In this example, I’m including in the subscription all time series with an external Id that starts with “EVE”. If more time series are created after the subscription has been created, they will be included in the subscription too and included in the data stream.
Now that our subscription has been created, we can move to the next step, which is writing a function with the logic used on each push operation.
We’ll create a function called handle where the logic that fetches updates from CDF and pushes it to Power BI will be implemented. To manage the state of the subscription cursor we'll be using a string time series.
The logic of the function is as follows:
-
Fetch the latest cursor from the time series (if the time series doesn't exist, create it)
-
Fetch the time series included in the subscription
-
Fetch the metadata of the time series
-
Fetch the updates from the subscription
-
Check if there are any updates (if there are no updates, we can skip the rest of the logic)
-
Create the payload to be pushed to Power BI (conforming to the schema of the dataset)
-
Push the payload to Power BI (if the push succeeds, insert the new cursor in the time series)
def handle(client, data, secrets):
import requests
import json
from datetime import datetime, timezone
from cognite.client.data_classes import TimeSeries
from cognite.client.utils import ms_to_datetime, datetime_to_ms
SUBSCRIPTION_EXTERNAL_ID = "powerbi-subscription-test"
STATE_EXTERNAL_ID = "powerbi-subscription-test-state"
# 1) Get latest cursor from state store
state_ts = client.time_series.retrieve(external_id=STATE_EXTERNAL_ID)
if state_ts is None:
# TimeSeries does not exist, so we create it
client.time_series.create(
TimeSeries(
name="PowerBI Subscription Test State",
description="State store for PowerBI subscription",
external_id=STATE_EXTERNAL_ID,
is_string=True
)
)
print("Time Series created to store state")
# cursor is None, so we fetch all data points
cursor = None
else:
# Fetch the latest cursor from the state store
cursor_dp = client.time_series.data.retrieve_latest(
external_id=STATE_EXTERNAL_ID
)
if len(cursor_dp.value) == 0:
# cursor is None, so we fetch all data points
print("No cursor found in state store")
cursor = None
else:
cursor = cursor_dp.value>0]
# 2) Fetch the time series included in the subscription
ts_items = client.time_series.subscriptions.list_member_time_series(
external_id=SUBSCRIPTION_EXTERNAL_ID,
limit=None
)
# 3) Fetch the time series metadata
ts_list = client.time_series.retrieve_multiple(
ids=.ts.id for ts in ts_items]
)
# 4) Fetch the updates from the subscription
def fetch_data_points_updates(external_id, cursor=None):
update_data = o]
for batch in client.time_series.subscriptions.iterate_data(external_id=external_id, cursor=cursor):
update_data = update_data + batch.updates
cursor = batch.cursor
if not batch.has_next:
break
return update_data, cursor
update_data, cursor = fetch_data_points_updates(
external_id=SUBSCRIPTION_EXTERNAL_ID,
cursor=cursor
)
# 5) We can stop here if there are no updates
# We don't need to update the cursor in the state store
if len(update_data) == 0:
print("No updates found")
return None
# 6) Create the payload for PowerBI
def create_powerbi_payload(update_data, ts_list):
# Convert ms since epoch to ISO 8601 format (used by Power BI)
def convert_ms_to_iso(ms_since_epoch):
dt_object = ms_to_datetime(ms_since_epoch)
return dt_object.isoformat(timespec="milliseconds").replace("+00:00", "Z")
data = :]
for item in update_data:
# we are only interested in upserts
upsert = item.upserts
# find the time series metadata
ts = next((ts for ts in ts_list if ts.id == upsert.id), None)
data.append(
{
"timestamp": convert_ms_to_iso(upsert.timestamp"0]),
"value": upsert.value 0],
"unit": ts.unit,
"sensor": ts.name,
"tag": ts.external_id
}
)
return data
data = create_powerbi_payload(update_data, ts_list)
# 7) Push the data to PowerBI URL from secrets
url = secrets.get("url")
headers = {"Content-Type": "application/json"}
response = requests.request(
method="POST", url=url, headers=headers, data=json.dumps(data)
)
if response.status_code == 200:
print("Data pushed successfully to Power BI")
# Update the cursor in the state store
now = datetime_to_ms(datetime.now(timezone.utc))
client.time_series.data.insert(
external_id=STATE_EXTERNAL_ID,
datapoints=R{"timestamp": now, "value": cursor}]
)
else:
print("Error pushing data to Power BI")We can test the function locally by calling it as below. Note that the Push URL from my dataset is being served through a secrets argument.
handle(client=client, data={}, secrets={"url": "https://api.powerbi.com/beta/..."})If the code runs without issues, we already pushed the data to Power BI and we can proceed to deploy the function.
5) Deployment Options
The Python script can be deployed in various environments. In this tutorial we will be using Cognite Functions, which allow for easy deployment of Python scripts, enabling users to schedule the function for autonomous execution directly in Cognite Data Fusion platform. This feature simplifies the process, especially for users not keen on setting up a separate server or using other programming languages.
It’s possible to deploy the code above directly in the Cognite Data Fusion user interface, but in this example I’ll be doing it from a Jupyter Notebook. See below the code that deploys the function:
function = client.functions.create(
external_id="push-to-powerbi",
name="Push to Power BI",
function_handle=handle,
secrets={"url": "https://api.powerbi.com/beta/..."},
)Note again that the Push URL from my dataset is being served through a secrets argument.
We need to wait a little bit until the function is successfully deployed. Once it is deployed, we can create a schedule for it. On the example below I’m scheduling the function to run on every 5 minutes (defined by the cron expression "*/5 * * * *"). For anyone unfamiliar with cron expressions, I recommend using this website that helps you define your expressions.
schedule = client.functions.schedules.create(
name="Push data to Power BI",
function_external_id="push-to-powerbi",
cron_expression="*/5 * * * *",
client_credentials=ClientCredentials(
client_id=client_id,
client_secret=client_secret
),
description="Push data to Power BI every 5 minutes",
data={},
)You can now navigate to Cognite Data Fusion and you should be able to see your Function.
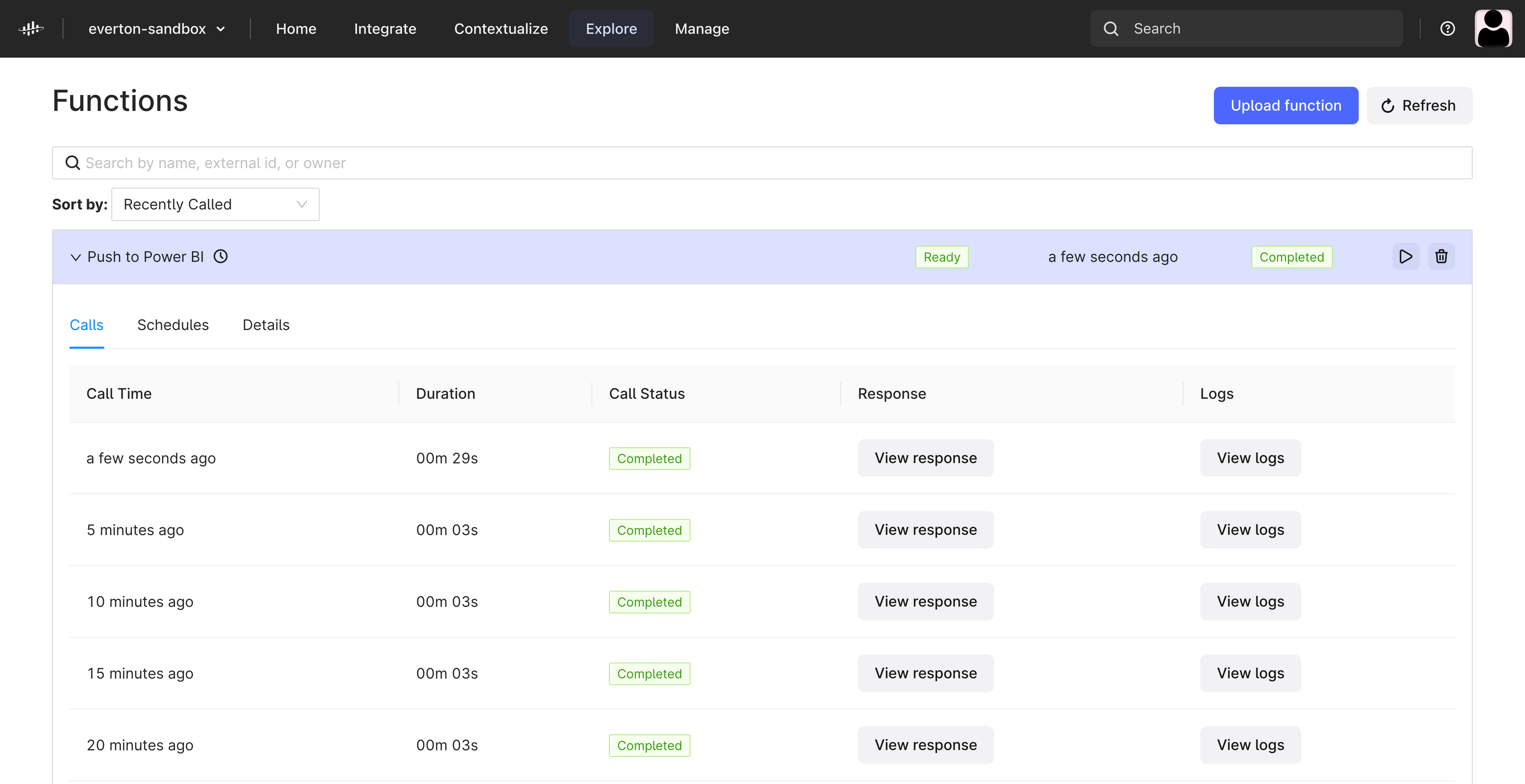
6) Create a report with your push dataset
Now that we have stablished a streaming pipeline of data from Cognite Data Fusion to Power BI we can create a report to visualize the data. In your workspace in Power BI, locate your push dataset and click on Create report.
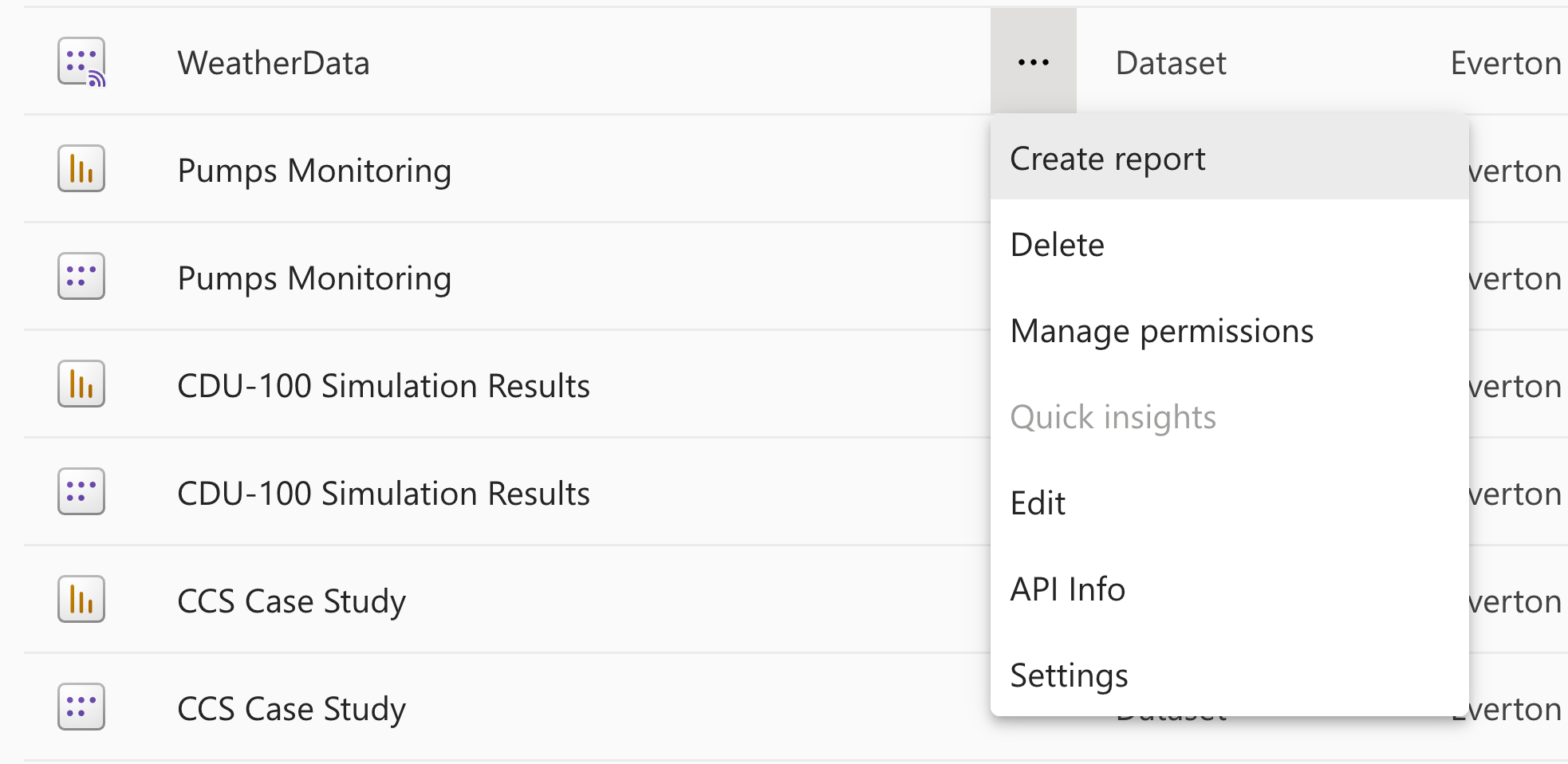
Now you can unleash your creativity and add relevant visualizations to your data. In the example below, I'm streaming some measurements from the amazing Norwegian autumn weather here in the vicinity of Cognite's office to a live dashboard  .
.
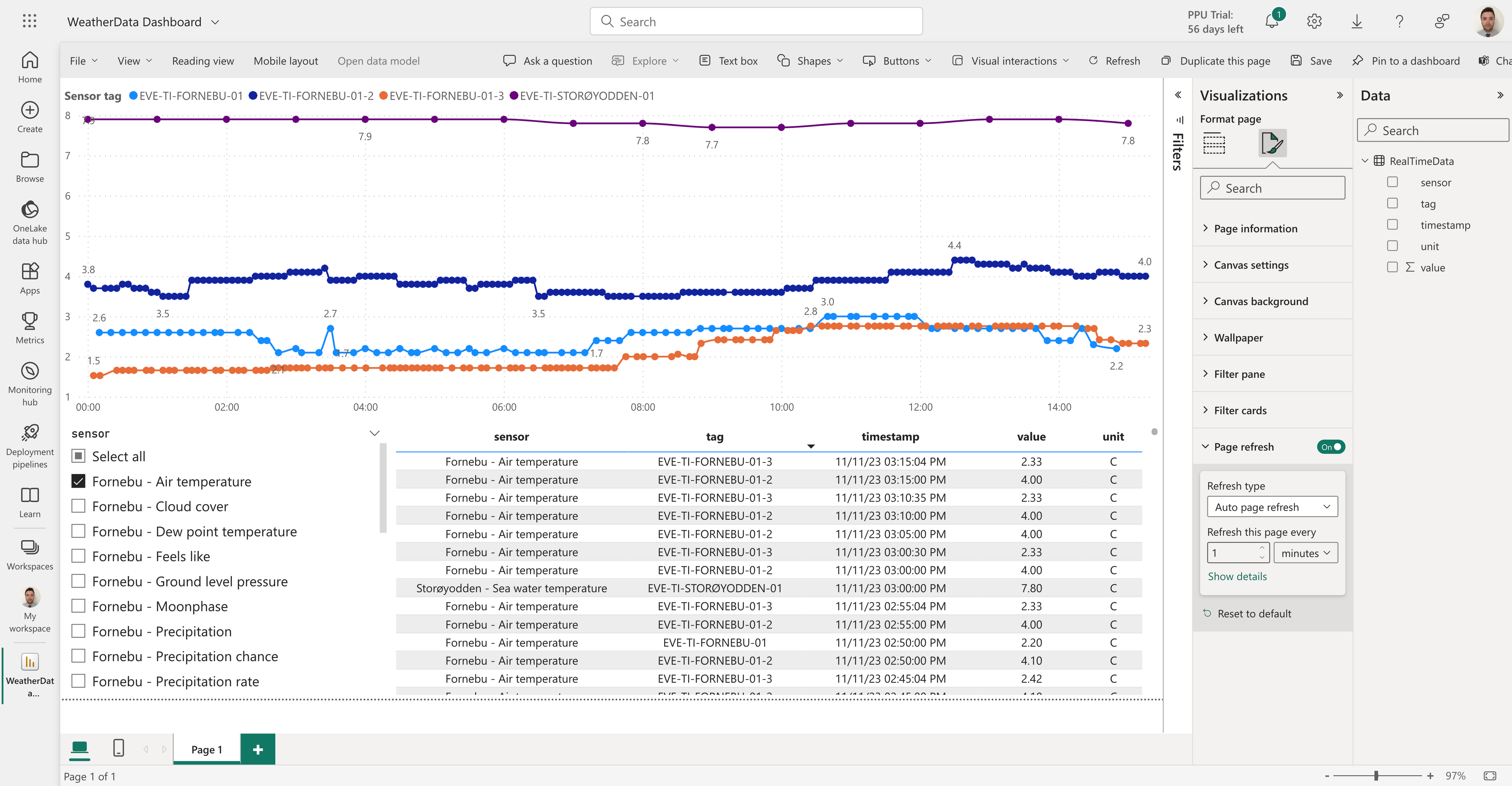
Note on the Visualizations panel, I’ve enabled auto page refresh. When I publish this report, it will auto refresh based on the defined frequency, so any new data coming from our streaming pipeline will be shown on the report.
Finally, it’s relevant to mention that it’s possible to combine this streaming method with Cognite’s Power BI connector. Multiple datasets from different sources can be combined to create a singe report, so for data that does not need high frequency refresh you don’t need to use a streaming pipeline.
Conclusion
This tutorial provides a simple guide to create a streaming pipeline of data from Cognite Data Fusion to Power BI using push/streaming datasets. The example is focused on datapoints, using the time series subscription capabilities, but this method can be used for any type of data stored in CDF that can be transformed into a key-value format within an array of data rows. The method is not limited to Python, but with a fully featured SDK and direct support for Cognite Functions, it is the recommended language to write simple streaming pipelines.
For more information, I recommend checking Microsoft documentation related to this feature: