

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support
Introduction
Co-author:
Cognite Functions provide a run-time environment for hosting and running Python code, similar to Azure Functions, Google Cloud Functions, or Amazon Lambda. One of the benefits of utilizing the built in Functions capability of CDF is that it is tightly coupled with CDF and gives you, as a developer, an implicit Cognite client allowing you to seamlessly interact with your CDF data and data pipeline.
CDF Extraction Pipelines allow you to monitor the data flow and gain visibility into the run history and receive notifications from data integration events that need to be paid attention to, all of which is an important part of the resulting data quality. CDF Extraction Pipelines offer a great feature for storing extractor configuration settings, allowing you to remotely configure the extractor. This can be extremely helpful as it avoids having to locally manage extractor configuration.
This article will explore the combination of Extraction Pipelines for flexible configuration and visibility in combination with Cognite Functions. We will use the extraction pipeline configuration to dynamically configure the Cognite function without having to redeploy the function itself.
Define a data set
Before we create our Extraction Pipeline we need to create a data set that our extraction pipeline can be associated with. Within the extraction pipeline we will also provide the configuration that our Cognite Function also will be configured.
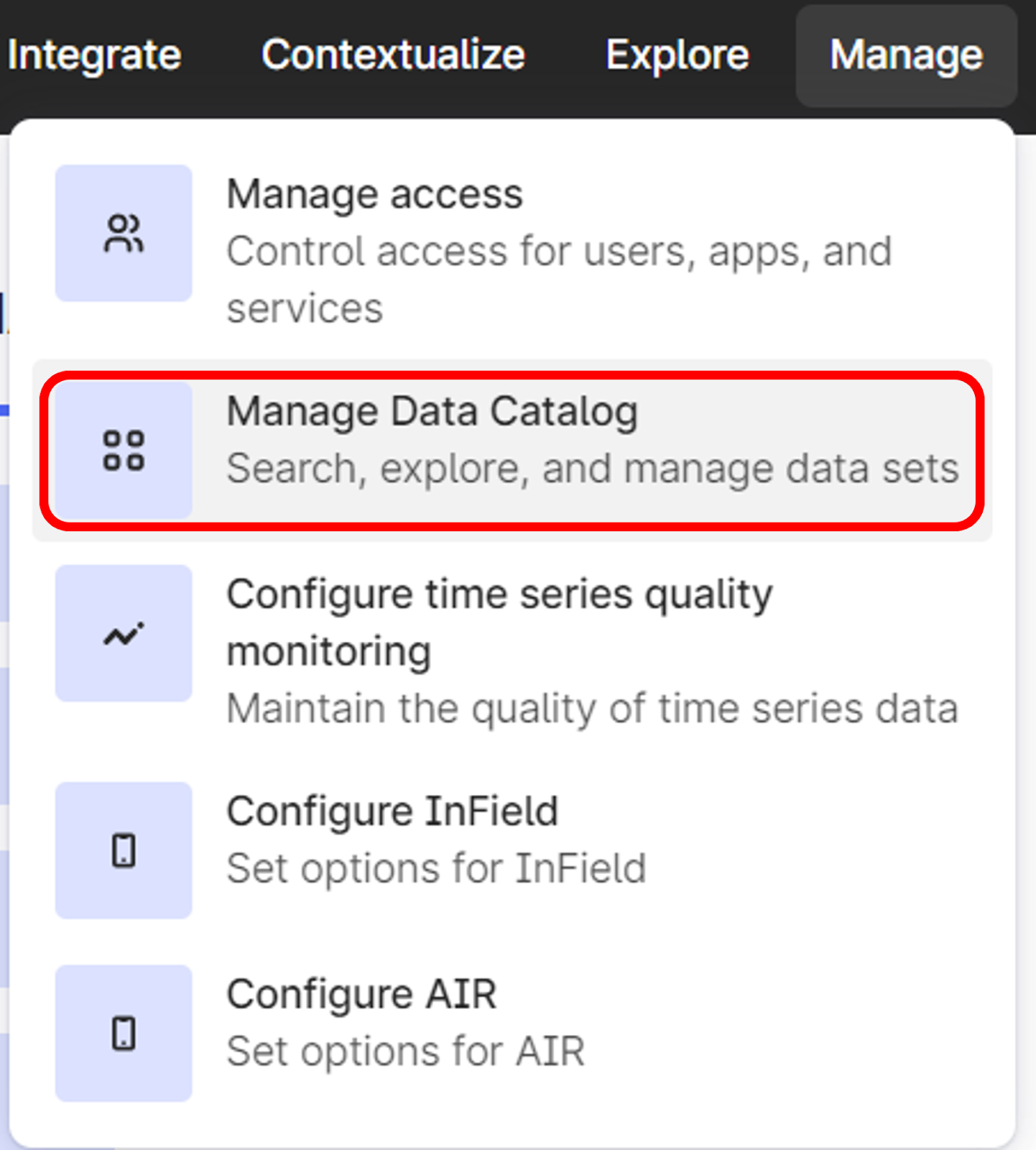
Select Manage Data Catalog from the Manage menu:
Create a new data set
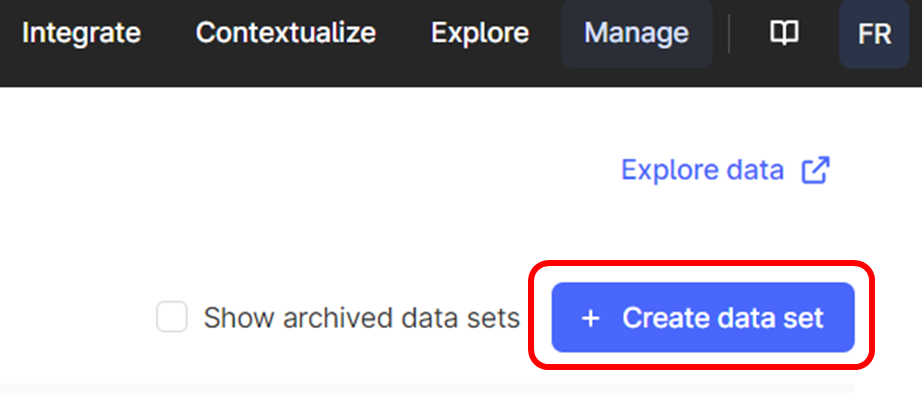
Name the data set: “Function pipeline configuration”.
Setting up the extraction pipeline
Access rights required
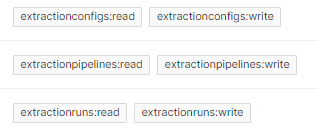
Create the extraction pipeline
From the Integrate-menu select Create and Monitor Extraction Pipelines from the Integrate menu.

In the upper right corner select Create extraction pipeline and fill in the required details. In our example we have created the Function pipeline configuration dataset


Document the function in the extraction pipeline
Easily accessible documentation. Add documentation to the Extraction pipeline, connect the notification service to an e-mail address for ease of understanding and easy access to documentation close to the code and notifications when the process fails.
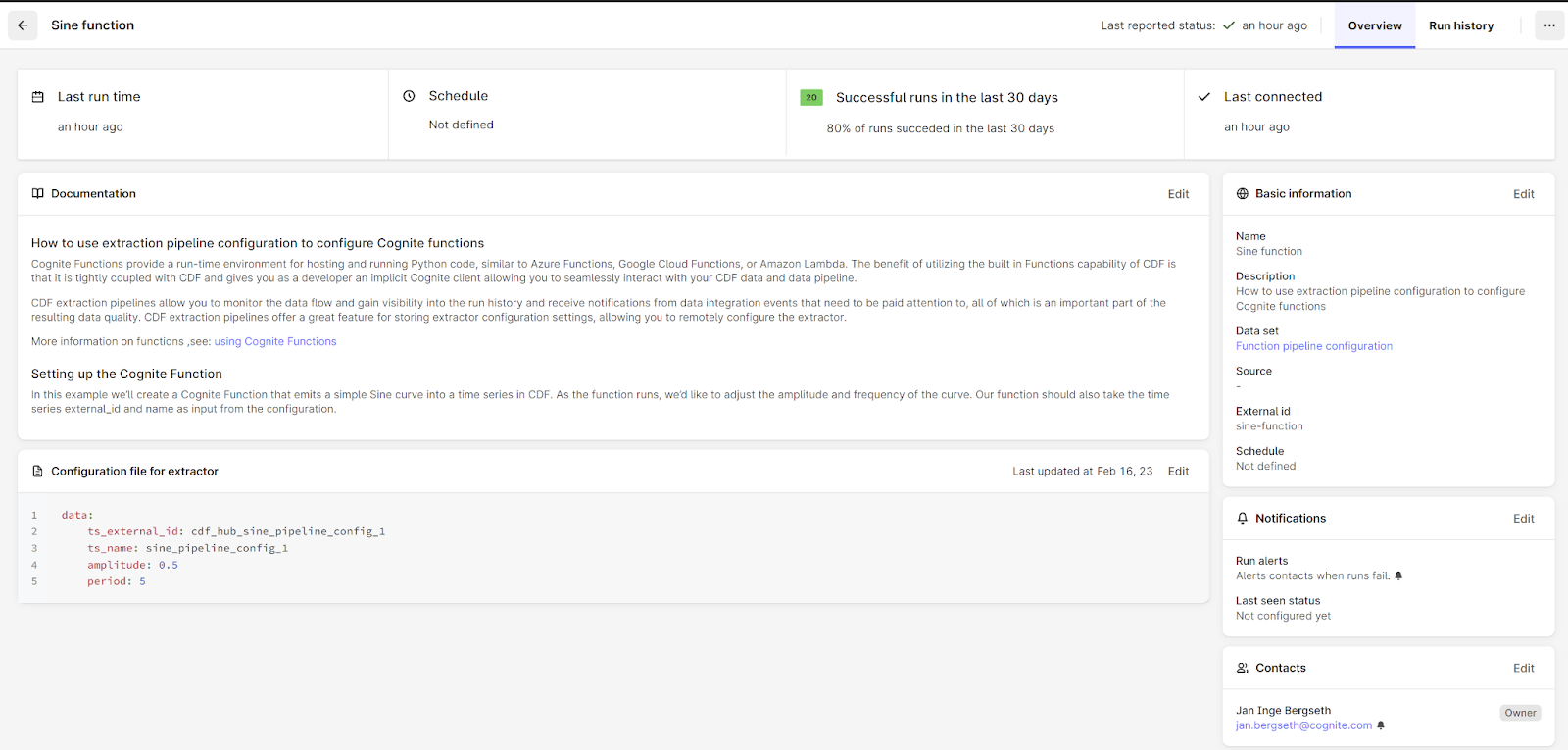
Define the configuration for your function
Choose to edit the documentation and add the text below and publish the configuration.
Please note that the data-block and below text needs to be copied as is with indents and all.
Example #1
data:
ts_external_id: cdf_hub_sine_pipeline_config_1
ts_name: sine_pipeline_config_1
amplitude: 0.5
period: 5
Setting up the Cognite Function
In this example we’ll create a Cognite Function that emits a simple Sine curve into a time series in CDF. As the function runs, we’d like to adjust the amplitude and number of periods of the curve. Our function should also take the time series external_id and name as input from the configuration.
The function will write time series data from the time you run the function and forward in time. The code for our test function is also available in the GitHub repository: https://github.com/cognitedata/how-to-cognite-function-extr-pipeline-config
Deploy your Function to Cognite Data Fusion
As described in the article: https://docs.cognite.com/cdf/functions/ there are multiple ways of deploying your function to CDF. In this example we will deploy by uploading of a zip file to CDF.
You will find the files handler.py and requirements.txt. Handler.py contains the code for the function, and requirements.txt list python packages used in the function that are not included by default in Cognite Functions.
Select handler.py and requirements.txt. And create a zip file that you can name anything ( in example we named it sine.zip)

Then from the Cognite Data Fusion UI, select Explore -> Cognite Functions:
In Functions, click on:

In the Upload function forme you only have to:
-
Drag and drop in your zip file ( with handler.py and requirements.txt) into the Function file box.
-
Give your function a name
-
Give your function and External Id (This is optional but good practice to always do)
-
For rest of the configuration you can just leave it blank or use the provided default values
-
Click on


Once uploaded the function will show in the UI as Queued. From Queued the function will move to Deploying to Ready

Test running your function
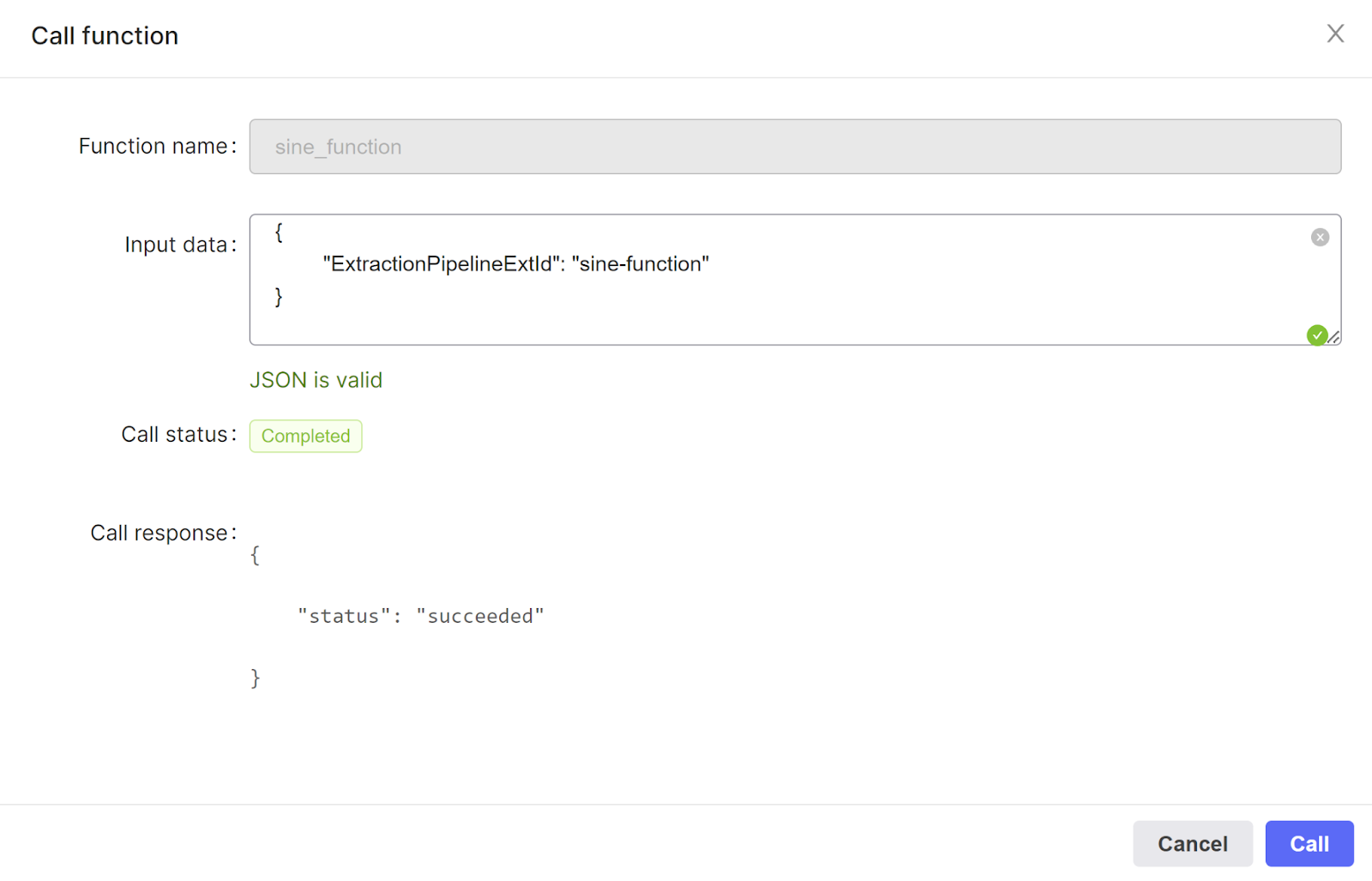
Once ready, we can run the function by clicking on the arrow :
As input data use:
| { "ExtractionPipelineExtId": "sine-function" } |
Value here is the same as you used as external ID when you configured your extraction-pipline in the Cognite Fusion UI.
Then click on to run the function. One completed you should see:
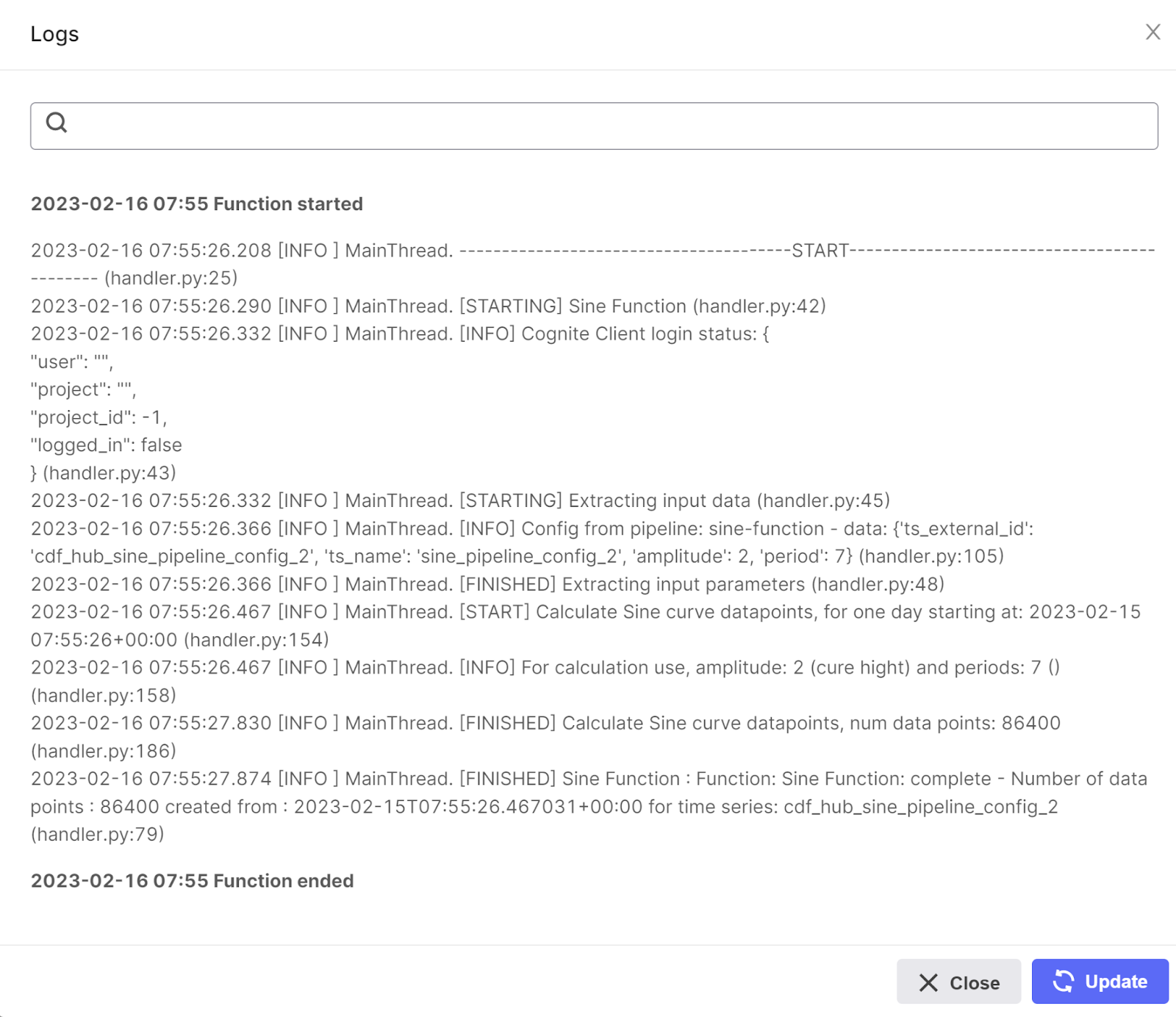
You now have the possibility to explore the logs created by the function, expand the sine_function details, and click on view logs

The log should look something like this:
Next step would now be to see the effects of updating the configuration for the function. The configuration was part of the extraction pipeline.
Update your configuration in the Fusion UI ( Extraction Pipeline - Sine Function)
Example #2
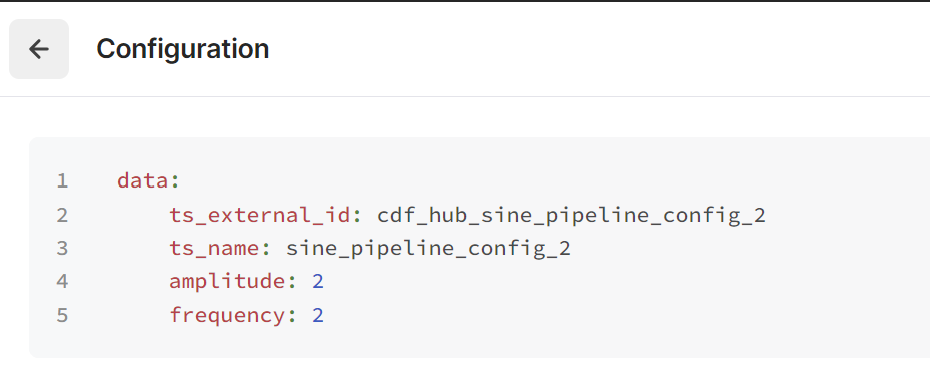
data:
ts_external_id: cdf_hub_sine_pipeline_config_2
ts_name: sine_pipeline_config_2
amplitude: 2
period: 7
Re-run the function with the new configuration, but the same function input data as before (pointing to the extraction pipeline external_id). Check the new output. This will create a new time series. When looking at the time series data points, please note the changes made in the configuration reflected in the new time series.
Creating a failed run
Next we will create a failed run, just to see how this looks in the Extraction Pipeline run history. Update the configuration in the extraction pipeline as follows:
Example #3
data:
ts_external_id:
ts_name:
amplitude: 2
period: 7
Check the extraction pipeline run history
Go back to the extraction pipeline you created at the beginning and select Run History in the upper right corner.
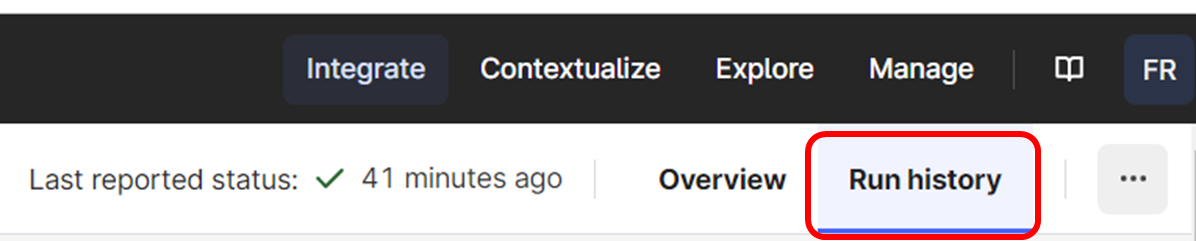
This will give you an overview of the runs the function has logged in the extraction pipeline.
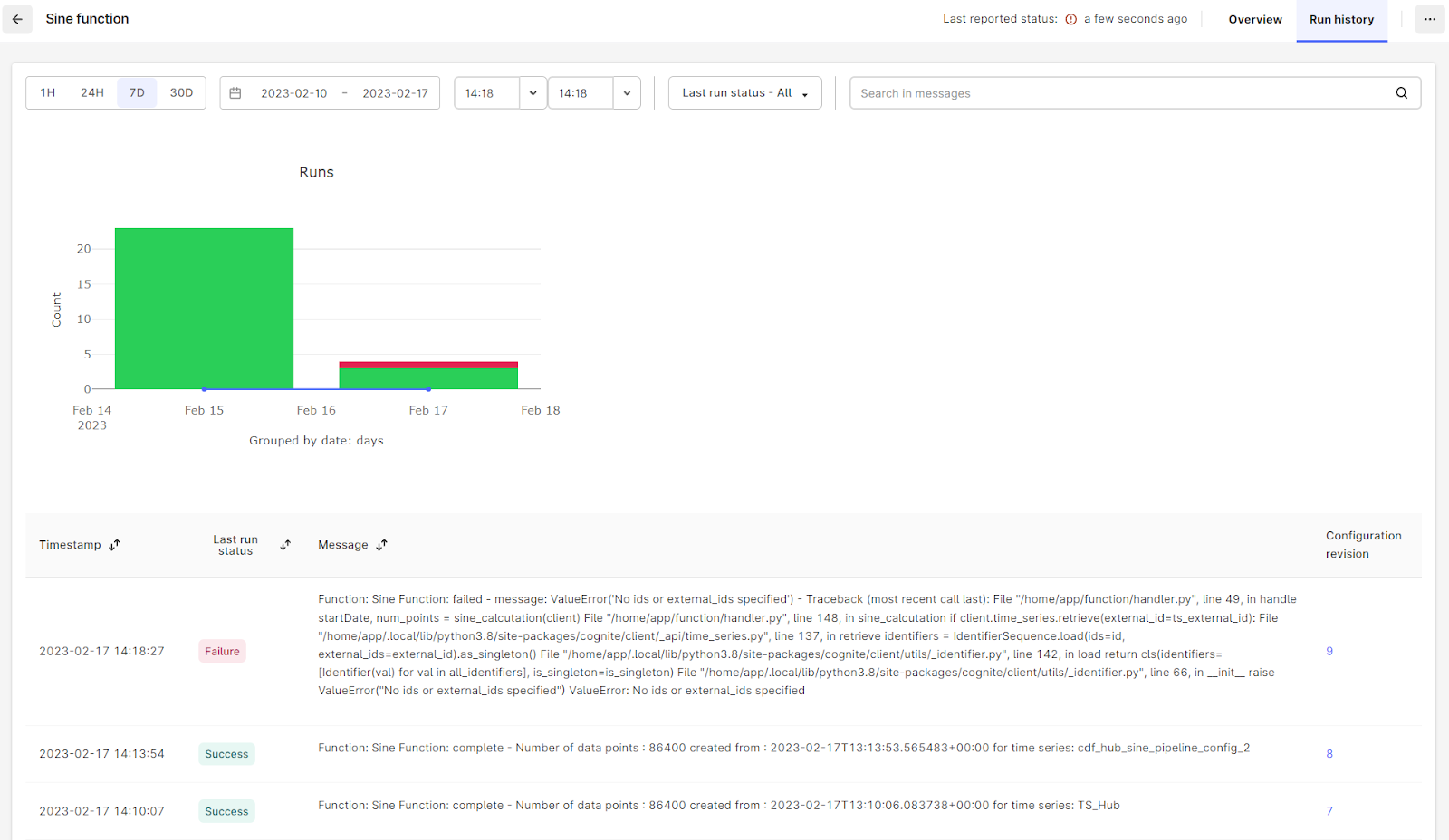
As you will note there are some successful runs and one failed run.
The failed run should also have triggered an email notification to the email address defined as the owner of the extraction pipeline.
For each logged run there is also an overview of which configuration revision being used for that particular run. By clicking the revision number you will be able to see the actual configuration settings the function has used.
View your result in Cognite Charts
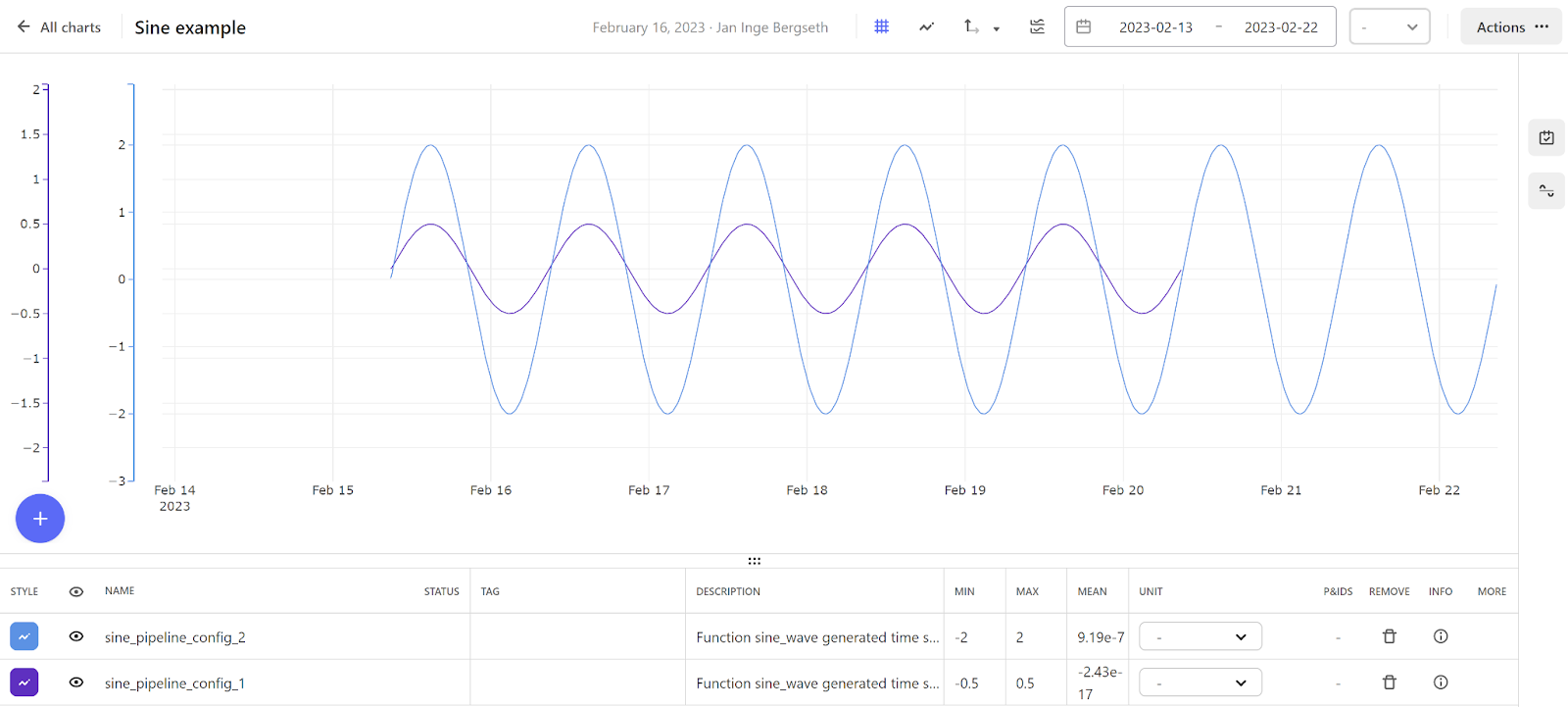
Cognite provides a tool called Charts that we will use to view the generated time serieses from our function. Charts is a powerful and speedy tool for engineers and domain experts to explore, trend, and analyze industrial data. It gives industrial experts instant access to data and no-code tools to find, understand and troubleshoot for actionable insights.
The description below on Chart usage will be very limited, for more information see: https://docs.cognite.com/cdf/charts/
| Open Charts in the Fusion UI: |
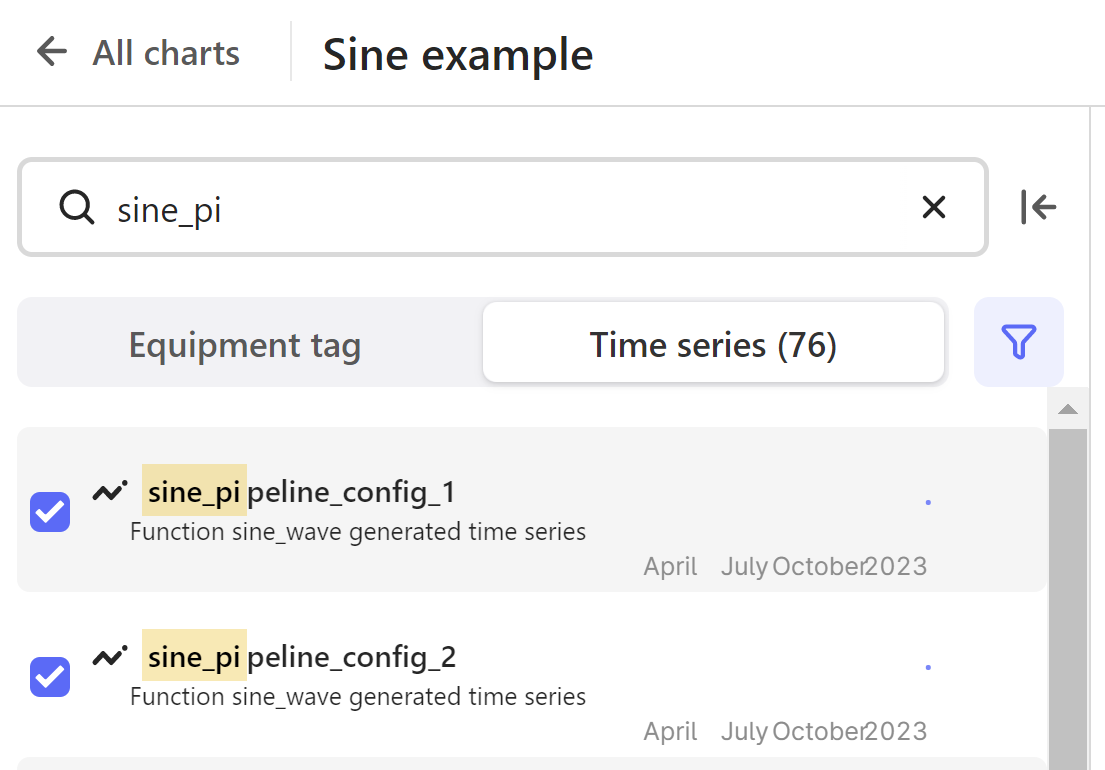
| Click on the button: (give it a name if you want to, as Sine Function) and find the function generated Sine time series by clicking on Time series. Search for the names you used on your time serieses, and select them in the list of found time serieses | |

You will now get the plotter sine curves in the application. You might have to adjust the Y axis - after the adjustment you should be able to see 2 different curves corresponding to the names, amplitude and number of periods you configured for the function in the extraction pipeline.
Conclusion
In this article we have covered how we can define a Cognite function that uses the Extraction Pipeline configuration feature to dynamically update configuration settings without having to redeploy the function. We have also looked at defining a data set, Cognite function deployment and logs.
References:
Demo code repo: https://github.com/cognitedata/how-to-cognite-function-extr-pipeline-config