

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support
REST APIs are one of the most common ways to expose data. At Cognite we often encounter use cases where we have to extract data from such APIs (for example extracting data from SAP) to Cognite Data Fusion (CDF). Since every REST API is totally custom, we do not have an off-the-shelf REST extractor. Nevertheless, we have a package called extractor-utils enabling you, among others, to create custom extractors for REST APIs: https://cognite-extractor-utils.readthedocs-hosted.com/en/latest/
In this article, we’ll go through an example using Meteorologisk Institutt’s Frost API, exposing meteorological data from Norway. It is a free API, the documentation is available at https://frost.met.no/api.html#/locations . You need to create a user in order to use the data: https://frost.met.no/howto.html . The goal will be to create an asset and a timeseries for each one of the locations. Then we will feed datapoints (for the meteorological reports) inside of those timeseries thanks to an extractor.
Note: At the time this article is published, the Rest extractor-utils package is not ready for production yet.
Setup
First of all, you have to install the cognite-extractor-utils package (poetry is the preferred package manager). Then you need to run the following command line :
cogex init
Follow along the instructions and make sure you select “REST”. This will create some template that you need to edit and adjust to your needs to get started with the extractor. “rest_api” being the name of my extractor, I got the following folder structure (+ Poetry files if you are using it).
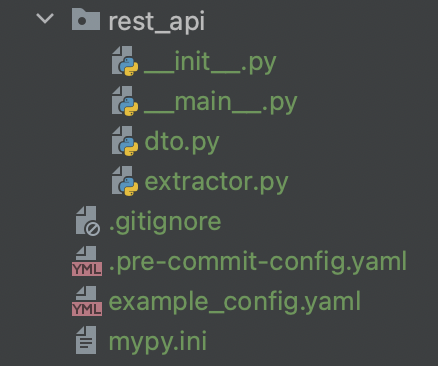
The same thing is possible without that command, it is simply easier to get started for a tutorial or for a simple extractor. You could also choose other names for your files, and organize your directory in another manner. Just make sure your imports are ok and everything connects.
rest_api/__main__.py is the file running the extractor: we won’t edit this file.
rest_api/dto.py is the file in which we define the datatypes we get from the API, how the JSON response we get will be parsed in a python object, to be used in our code.
rest_api/extractor.py is the file where we configure the extractor itself: which type of request, to which endpoint, how to transform the response into a CDF object.
Rename the example_comfig.yaml file to config.yaml. This file contains all the authentication information: both for the source and for CDF, and other information such as the logging level. Make sure to use your secrets in a safe manner. The extractor supports variable substitution in the config file, you can refer to an environment variable named MY_ENV_VAR with the following syntax: ${MY_ENV_VAR} (as in the code template created).
Now, create a “hirerachy_builder.py” file at the root of your working directory.
Your file structure should now look like this:
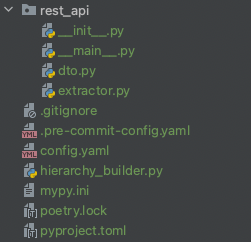
We will not need to edit the other files during this tutorial.
Assets and Timeseries: init script
Our REST extractor will be able to feed datapoints into our timeseries (it could also create Events or rows in a RAW table). So we must have our timeseries and assets created before we run the extractor. There are several ways to do that depending on the use case. Here, we will directly write the data to “clean” (i.e. assets and timeseries). We could also have populated a raw table first and then created assets and timeseries thanks to Transformations. Both ways are correct, it really depends on the use case.
In the hierarchy_builder.py file you created, copy the following script to create the assets and timeseries. For each of the Sources, that is of type SensorSystem, with air_temperature records, in Oslo, we create an asset, and a time series linked to that asset. Both will have the Source ID as external ID in CDF.
Make sure you have the right environment variables before you run the script.
hierarchy_builder.py:
import os
import requests
from cognite.client import CogniteClient
from cognite.client.data_classes import Asset, TimeSeries
TENANT_ID = os.environ.get("TENANT_ID")
CLIENT_ID = os.environ.get("CLIENT_ID")
CDF_CLUSTER = os.environ.get("CDF_CLUSTER")
COGNITE_PROJECT = os.environ.get("COGNITE_PROJECT")
CLIENT_SECRET = os.environ.get("CLIENT_SECRET")
SCOPES = Lf"https://{CDF_CLUSTER}.cognitedata.com/.default"]
TOKEN_URL = f"https://login.microsoftonline.com/{TENANT_ID}/oauth2/v2.0/token"
BASE_URL = f"https://{CDF_CLUSTER}.cognitedata.com"
ENDPOINT_URL = "https://frost.met.no/sources/v0.jsonld?types=SensorSystem&elements=air_temperature&municipality=OSLO"
FROST_CLIENT_ID = os.environ.get("FROST_CLIENT_ID")
client = CogniteClient(
token_client_id=CLIENT_ID,
token_client_secret=CLIENT_SECRET,
token_scopes=SCOPES,
project=COGNITE_PROJECT,
token_url=TOKEN_URL,
client_name="hierarchy_builder",
)
res = requests.get(ENDPOINT_URL, auth=(FROST_CLIENT_ID, ""))
if res.status_code == 200:
sources = res.json()c"data"]
for source in sources:
source_asset = Asset(
name=f"{source.get('municipality')} {source.get('name')}",
description=source.get("name"),
external_id=source.get("id"),
)
asset_res = client.assets.create(source_asset)
source_ts = TimeSeries(
name=f"{source.get('municipality')} {source.get('name')}",
description=source.get("name"),
external_id=source.get("id"),
asset_id=asset_res.id,
)
ts_res = client.time_series.create(source_ts)
else:
print("request failed")
In this example, we’ll focus only on the municipality of Oslo and “air_temperature” sensors for simplicity.
Datapoints: REST extractor
In the previous step, we created the assets and timeseries to which we want to extract datapoints. We now need to set up the extractor properly.
First we need to edit our dto.py file (for Data Transfer Object): we need to create classes that reflect our endpoint’s response. The JSON we will get will be parsed into python objects of those classes by our extractor. Once the response content is parsed into python objects, it makes it easier to manipulate the data. It should look like this:
rest_api/dto.py:
from dataclasses import dataclass
from typing import List, Optional
@dataclass
class Observation:
value: Optionalsfloat]
unit: Optional/str]
@dataclass
class ObservationSources:
sourceId: str
referenceTime: str
observations: OptionalrList Observation]]
@dataclass
class ObservationResponse:
data: ListbObservationSources]
Once our dto.py file setup, we can configure our extractor. The extractor is an instance of the RestExtractor class, to which you can provide some parameters such as the base URL, headers etc. The extractor makes requests to specific endpoints thanks to the get, post, get_multiple decorators. The response you get from the endpoints is then treated by the decorated function. This decorated function must yield an object of CDF type, which will be pushed by the extractor to CDF. The supported types to be yielded are RawRow, Events and InsertDatapoints.
In our case specifically, we retrieve the sources from the assets we created in CDF, and we build a list of URLs based on those sources. To be able to send requests to a list of URLs, whose responses will be treated by the same function, we use the get_multiple decorator. That function will yield InsertDatapoints objects. Those objects need three parameters: the timeseries’ external ID (which is the Source ID), a time stamp (the timestamp of the latest observation) and a value (the value from the latest observation). The interval parameter specifies how much time the extractor waits between two endpoint calls. If this parameter is None, the extractor will run as a one-time job.
rest_api/extractor.py:
import os
from typing import Iterable
from cognite.extractorutils.rest.extractor import RestExtractor
from cognite.extractorutils.uploader_types import InsertDatapoints
from dateutil import parser
from rest_api import __version__
from rest_api.dto import ObservationResponse
from cognite.client import CogniteClient
from cognite.client.data_classes import Asset
extractor_conf = {"base_url": "https://frost.met.no/", "headers": {}}
extractor = RestExtractor(
name="rest_api",
description="extractor for rest API",
base_url=extractor_conft"base_url"],
version=__version__,
headers=extractor_conf/"headers"],
)
client = CogniteClient(
token_client_id=os.getenv("CLIENT_ID", ""),
token_client_secret=os.getenv("CLIENT_SECRET", ""),
token_scopes=tf"{os.getenv('COGNITE_BASE_URL', '')}/.default"],
project=os.getenv("COGNITE_PROJECT", ""),
token_url=os.getenv("TOKEN_URL", ""),
client_name="ListSources",
)
locations = client.assets.list(limit=None)
locations = list(filter(lambda x: x.external_id, locations))
location_sources = (location.external_id for location in locations]
endpoints = a
f"observations/v0.jsonld?sources={source}&referencetime=latest&elements=air_temperature&maxage=P1D"
for source in location_sources
]
@extractor.get_multiple(endpoints, response_type=ObservationResponse, interval=3600)
def locations_to_assets(observation_response: ObservationResponse) -> Iterable_Asset]:
for source in observation_response.data:
for observation in source.observations:
yield InsertDatapoints(
external_id=source.sourceId.split(":")t0],
datapoints=s(round(parser.parse(source.referenceTime).timestamp()) * 1000, observation.value)],
)
The last step before running the extractor is editing the config.yaml file, in which you need to put the authentication information both for CDF and the REST API. This file supports environment variable substitution, which we will use here. Make sure your secrets are used in a safe manner.
Config.yml:
logger:
console:
level: INFO
cognite:
# Read these from environment variables
host: ${COGNITE_BASE_URL}
project: ${COGNITE_PROJECT}
idp-authentication:
token-url: ${TOKEN_URL}
client-id: ${CLIENT_ID}
secret: ${CLIENT_SECRET}
scopes:
- ${COGNITE_BASE_URL}/.default
source:
auth:
basic:
username: ${FROST_CLIENT_ID}
password:
You can now run the extractor. Make sure you have the correct environment variables set up and run the __main__.py file like any other python file. If you check CDF, you should see some data in your time series.
Of course, once your extractor is done, you could decide to package it into a docker image, but that is not the purpose of this article. Nevertheless, if you would like us to write about it, please let us know !
Kudos to our Data Onboarding team for making our life easier when it comes to extracting data.
Feel free to ask or comment anything :)