

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support

My name is Sigrid Schaanning, and I have written this post together with Atussa Koushan. We both work as Software Engineers in Cognite’s Disruptive-MVP team, which focuses on robotics and computer vision. In this post, we will look further into how to develop a computer vision model, from gathering data to deploying the model on a robot. First, let’s set the scene for what we are trying to achieve in this post.
Imagine performing routine inspections at an industrial facility or an oil platform. You might have to read and note down the values of multiple gauges three times a day - every single day. Or, you might have to inspect different parts of the facility to check for corrosion or wear damage.
Routine inspections could be tedious and repetitive work, and it might take place in surroundings which are dangerous to humans.
Robots, on the other hand, have no perception of tedious work and they could also operate in hostile environments. Robots, together with computer vision, constitute a powerful tool which could be used to perform repetitive tasks with high precision - at some tasks they even outperform humans.
Thus, developing computer vision models and using them together with robots could strongly contribute to digitalising heavy-asset industries and leaving time for humans to perform more intricate and intellectual jobs.

1. What model do I want?
It would be incredibly convenient if you could just set your robot to perform any task and that the robot would have a complete perception of the world. We must however warn you, that setting out to solve this problem will quickly be overwhelming and possibly discouraging when you realize that there is no finish line in sight. Hence, the first step will be to identify a use case for your robot to solve. The more specific the use case, the better and the more likely you are to succeed with your model. You will always have the opportunity to extend your model later on.
Typical tasks solved by computer vision in robots are inspection tasks. When looking for use cases, think about what inspections are repeated very frequently. Is it possible to take a picture of for instance the gauge or valve you are inspecting? Are you able to get the information you need from the image? Note that the computer vision models we talk about here are still not able to see beyond the pixels in an image. If you are not able to recognize something (even by zooming in), the model is most likely just as blind.
In this article, to illustrate how to train and test a computer vision model, we will assume that you want to create a model to detect dogs on industrial sites.
2. Gather training data
The next step towards a computer vision model is to gather data for model training. The model training is essentially where the computer vision model learns how to perceive the real world.
Computer vision is not magic. A person who lacks knowledge of how computer vision works, might think that a computer vision model could recognize any dog - even though the model is trained using images of a few dog species only. The reality is that the model is more likely to recognize dog species it has seen before, but it could also recognize dogs in general as many dogs resemble one another. Therefore, it is important that the data used for training the computer vision model reflects what the model should be able to identify.
Moreover, the quality of the data used for training is important. As mentioned earlier, the data used for training should prepare the model for what it will actually encounter in the real world. Let’s stick to dogs on an industrial site - and let’s imagine that you have been able to get hold of five thousand images of dogs. If half of the images display dogs laying on the ground, and the other half includes completely blurred images - the computer vision model has no basis to recognize dogs walking around the facility captured in high resolution images.
On the other hand, twenty high resolution images of dogs in various poses won’t be sufficient either. Neither of these cases would provide the model with the desired diversity. Thus, when gathering a training dataset it is important to consider both data quality and data quantity. A rule of thumb is to use at least 5000 images when training a model to ensure a robust model. Nevertheless, it is possible to start training a model using less data, and then retrain the model when more data are available.
You should also keep in mind where the model will be used and who will use it. If it is a ground robot, the world will be perceived from a frog perspective, and maybe even from a fisheye camera. The computer vision model only sees image data as matrices of numeric values, meaning that a photo of a dog captured from below the dog in landscape proportions might be perceived as very different than a photo you would capture with your smartphone from above.

Source: https://www.istockphoto.com
3. Train model in CDF
After the data has been gathered, the process of training a computer vision model can start. Cognite Data Fusion supports training of computer vision models, which makes it possible for people without much technical competence to complete model training. Before the actual training could start, a few pre-processing steps need to be carried out.
First, the dataset of the dogs at the industrial site needs to be uploaded to Cognite Data Fusion. Next, the data has to be labeled. Labeling means marking and describing what a computer should recognize in an image. For instance, if an image of an industrial site contains several distinct features such as an excavator, a person and a dog, it is important to mark the dog in the image so that the computer vision model will recognize the dog in future industrial settings. It could also be useful to mark what objects are not categorized as dogs, and therefore label the person and the excavator as “non-dogs”. Marking an object will in most cases mean marking a rectangular area of the image in which the object is located.
When the data has been labeled, the actual training of the computer vision model can start. Training a model from CDF is simple - just mark the images you want to use, or simply choose an entire dataset, and press the “train”-button.
Training a computer vision model could potentially take some time (up to several days!) depending on the amount of data ingested to the model. Therefore, an opportunity to speed up the training process would be to base the new computer vision model on an existing computer vision model, either previously trained using CDF or from a third party. The benefit of doing this is that the model will gain a higher accuracy with a shorter training time.
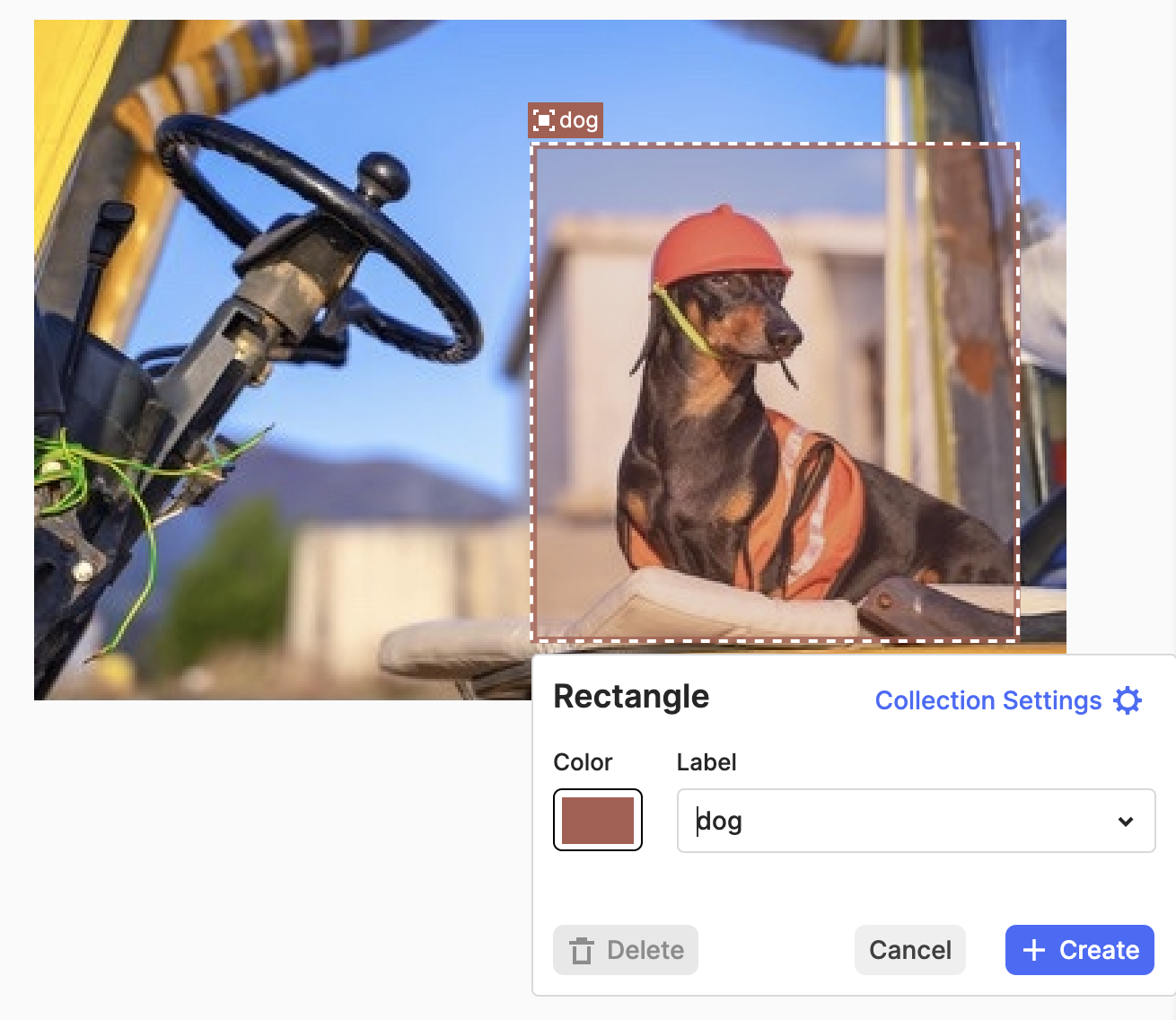
Source: https://www.shutterstock.com and Cognite Data Fusion
4. Test model
Now you have your model and life is great. However, some work still remains. Before deploying your model and putting your full trust into it, you might want to know how it performs. Does it really see the dogs on your site?
In order to test your model, it is important to use realistic data. Following the same concepts as for the training data, there is no use in just testing on close up portraits of dogs from the web, if you in reality expect your model to catch dogs from a distance and from many different angles. Collecting this data with your robot is the best option here.
Furthermore, it is very important to test the model on data that the model has never seen before. Failing to do so might give you false hope and results. The model might have learned that a particular dog in a particular environment in a particular pose is a dog, but might still be completely blind if it sees the dog in a different setting. Hence, separation of the training and test data is very important to get a true idea of the model performance.
5. Continuously improving the model
You might not be satisfied with the accuracy of your very first model; maybe it only sees every second dog or maybe it thinks that all cats and elephants are dogs as well. It can be frustrating, but don’t lose all hope yet. The performance of computer vision models grow along with the quantity and quality of the data they are provided.
Anything the model detects can be automatically saved back to Cognite Data Fusion with annotations. Meaning that you do not have to label this new data like you had to the first time around. Now you are probably wondering, what about all the undetected dogs? And even more importantly, what about all the cats and elephants? We definitely do not want those to mess up our dataset. You are totally right. In Cognite Data Fusion you have the opportunity to click through all new data and approve or decline the automatic labels. Furthermore, you can add labels to the dog images that were not detected by your model. Suddenly, you stand with a whole lot more data and can retrain your model. For every iteration the manual work will also decrease and your model performance will increase. In other words, the model will eventually train itself.
If you have any experience in the field of computer vision that you want to share, or if you have something to add to the topics discussed in this text, please feel free to leave a comment. Also, if you have any questions, do not hesitate to ask.
