

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support
Hello All! As this is my first time writing, I will do a quick introduction. My name is Patrick Mishima, and I am one of the Cognite Product Specialists. My main specialization is data integration and governance. I've worked with data since 2011 with different roles, projects, and job titles all related to data management. I also have experience with various ETL and BI tools, mainly from Microsoft and SAP and a few others.
I lead the Product Specialists team, and we'll soon have more articles to share our knowledge and experience with you.
Today and in my following articles, I will focus on the different options that Microsoft Azure and Cognite offer on data integration between our platforms and tools. But first, let's talk about a few essential and fundamental points when working with cloud providers. Using a cloud provider, most of the time, we think about saving on infrastructure costs. That is indeed true, but it's not the only truth. When you decide to move to a cloud provider, you also need to consider if you should use the flexibility to scale up/down or replace your current infrastructure with something different that better fits your needs. I'm raising those two basic concepts because you have various options to choose from when working with data integration. How you choose one over the other relates to cost analysis and the correct tool for your needs.
The image below illustrates how I would work in a standard architecture for data integration using Azure and CDF. I will explain later why I've chosen each data flow, but, at a high level, I've used the costs and my specific needs to select the Azure resources.
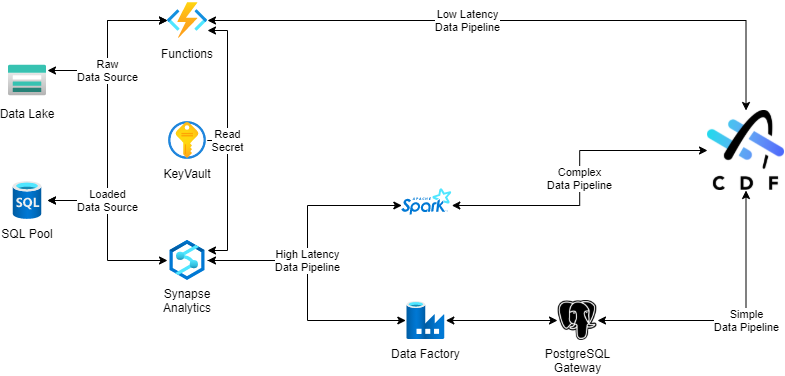
I'll not get into the details about specific challenges you should address case by case, and today I also won't get into the detail about each resource in the diagram. In a simple scenario, the data flow from the source to the destination is what we call ETL, ELT, or ELTL (E - Extract, L - Load, T - Transform). In this scenario, I have chosen a complete and typical flow - ELTL. The data flow diagram doesn't cover the extraction directly as each case requires more detailed and specific information. In a future post, I'll write about the most common sources used by different projects.
In my simple scenario, I've used a standard connection from Azure to different available sources to extract the source data. That data is then loaded into a storage resource in Azure. We call it RAW data as there is no transformation, and the data is an exact copy from the source. The reason to have the RAW data available in Azure is to be able to share the data between different solutions easily. The next step is to transform the data. This step uses a combination of different available RAW data to prepare the data in a format that we can consume. When we have prepared the data, we can load it into CDF, where it can be consumed by different use cases and applications that have CDF as a data source.
The data flow above also illustrates the inverted flow where CDF is the source. The only difference is that the destination is the shared repository in Azure, and in this scenario, it is an ETL data flow. Extract the data from CDF, transform it to fit the need, and load it into a shared repository. This is a common approach for BI use cases. You want the data to be sent to a data warehouse repository, for example, to be consumed by a visualization tool.
That is all I wanted to share today. It is imperative to highlight that this does not fit all the solutions. In my next article, I'll get into more details about my choices and the reasons behind them. Meanwhile, if you have any questions about this or any other questions related to data integration with CDF, do not hesitate to contact me.
Thanks and have a great week!
Patrick Mishima, Product Specialist - Data Integration and Governance
