

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support

Overview
The Contextualization Quality Dashboard module provides a comprehensive solution for measuring, monitoring, and visualizing the contextualization quality of your data in Cognite Data Fusion (CDF). It consists of two main components:
- Contextualization Quality Metrics Function (external_id:
context_quality_handler) - Computes all quality metrics and saves them as a JSON file in CDF - Streamlit Dashboard (
context_quality_dashboard) - Visualizes the pre-computed metrics with interactive gauges, charts, and tables
This module helps data engineers and operations teams understand how well their data is contextualized across seven key dimensions:
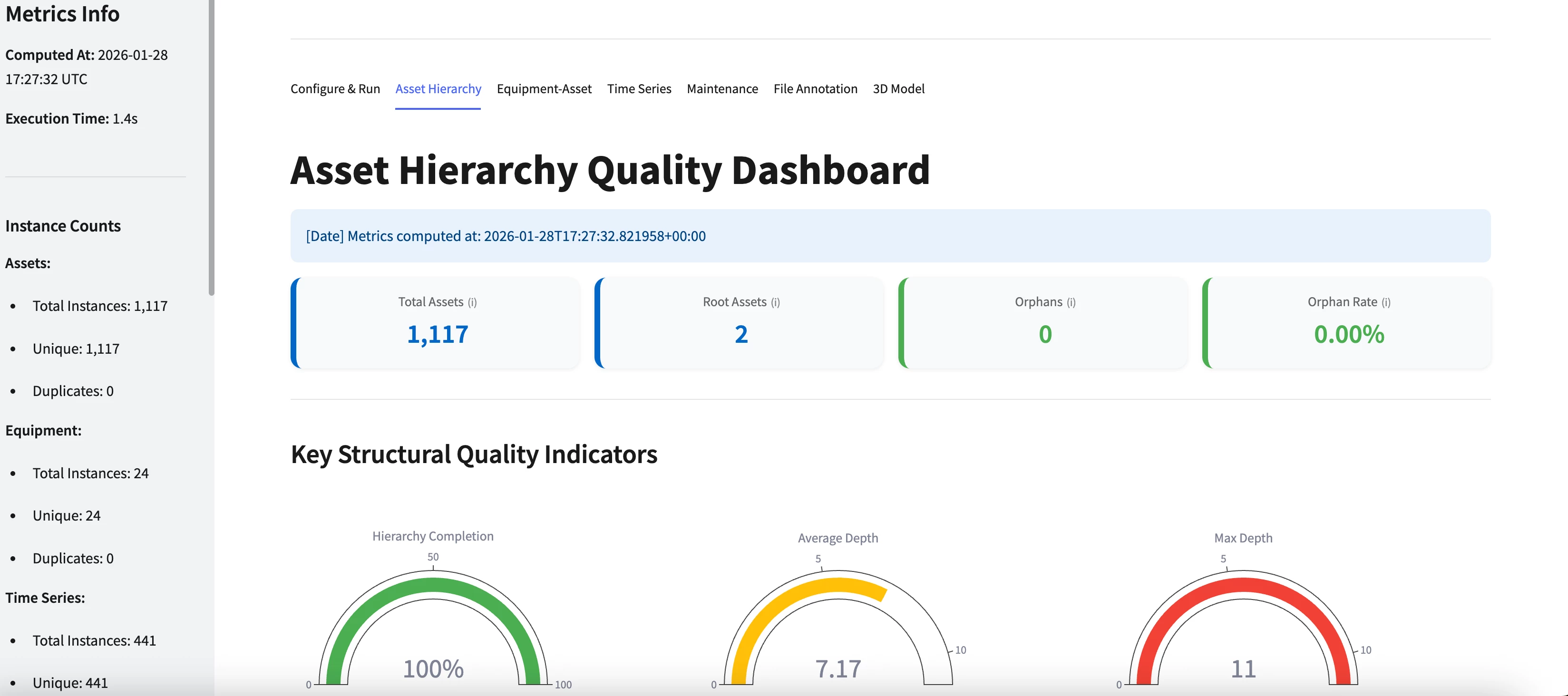
- Asset Hierarchy Quality - Structural integrity of the asset tree
- Equipment-Asset Relationships - Quality of equipment-to-asset mappings
- Time Series Contextualization - How well time series are linked to assets
- Maintenance Workflow Quality - Quality of maintenance data from RMDM v1 (notifications, work orders, failure documentation)
- File Annotation Quality - Quality of P&ID diagram annotations linking files to assets/equipment
- 3D Model Contextualization - Quality of 3D object linking to assets
- File Contextualization - Quality of file-to-asset linking and file metadata completeness
Module Components
context_quality/
├── auth/ # Authentication configurations
├── data_sets/
│ └── context_quality_dashboard.DataSet.yaml # Dataset for storing function code and files
├── functions/
│ ├── context_quality_handler/
│ │ ├── handler.py # Main Cognite Function orchestration
│ │ └── metrics/ # Modular metric computation
│ │ ├── __init__.py # Exports all metric functions
│ │ ├── common.py # Shared utilities and data classes
│ │ ├── asset_hierarchy.py # Asset hierarchy metrics
│ │ ├── equipment.py # Equipment-asset metrics
│ │ ├── timeseries.py # Time series metrics
│ │ ├── maintenance.py # Maintenance workflow metrics (RMDM v1)
│ │ ├── file_annotation.py # File annotation metrics (CDM)
│ │ ├── model_3d.py # 3D model contextualization metrics
│ │ ├── files.py # File contextualization metrics
│ │ └── storage.py # File storage utilities
│ └── context_quality.Function.yaml # Function configuration
├── streamlit/
│ ├── context_quality_dashboard/
│ │ ├── main.py # Streamlit dashboard entry point
│ │ ├── requirements.txt # Python dependencies
│ │ └── dashboards/ # Modular dashboard components
│ │ ├── __init__.py # Exports all dashboard functions
│ │ ├── common.py # Shared UI components & color functions
│ │ ├── sidebar.py # Sidebar with metadata
│ │ ├── configuration.py # Configuration & Run tab
│ │ ├── asset_hierarchy.py # Asset Hierarchy tab
│ │ ├── equipment.py # Equipment-Asset tab
│ │ ├── timeseries.py # Time Series tab
│ │ ├── maintenance.py # Maintenance Workflow tab (RMDM v1)
│ │ ├── file_annotation.py # File Annotation tab (CDM)
│ │ ├── model_3d.py # 3D Model Contextualization tab
│ │ ├── files.py # File Contextualization tab
│ │ ├── reports.py # PDF report generation
│ │ └── ai_summary.py # AI-powered insights generator
│ └── context_quality_dashboard.Streamlit.yaml # Streamlit app configuration
├── scripts/ # Local script execution (alternative to Cognite Functions)
│ ├── client.py # CDF authentication for local runs
│ ├── run_metrics.py # Main local execution script
│ ├── requirements.txt # Python dependencies for local script
│ └── README.md # Local script documentation
├── module.toml # Module metadata
└── README.md # This file
Deployment
Prerequisites
Before you start, ensure you have:
- A Cognite Toolkit project set up locally
- Your project contains the standard
cdf.tomlfile - Valid authentication to your target CDF environment
Step 1: Enable External Libraries
Edit your project's cdf.toml and add:
[alpha_flags]
external-libraries = true
[library.cognite]
url = "https://github.com/cognitedata/library/releases/download/latest/packages.zip"
checksum = "sha256:795a1d303af6994cff10656057238e7634ebbe1cac1a5962a5c654038a88b078"
This allows the Toolkit to retrieve official library packages.
Note: Replacing the Default Library
By default, a Cognite Toolkit project contains a
[library.toolkit-data]section pointing tohttps://github.com/cognitedata/toolkit-data/.... This provides core modules like Quickstart, SourceSystem, Common, etc.These two library sections cannot coexist. To use this Deployment Pack, you must replace the
toolkit-datasection withlibrary.cognite:
Replace This With This [library.toolkit-data][library.cognite]github.com/cognitedata/toolkit-data/...github.com/cognitedata/library/...The
library.cognitepackage includes all Deployment Packs developed by the Value Delivery Accelerator team (RMDM, RCA agents, Context Quality Dashboard, etc.).
Checksum Warning
When running
cdf modules add, you may see a warning like:WARNING [HIGH]: The provided checksum sha256:... does not match downloaded file hash sha256:...
Please verify the checksum with the source and update cdf.toml if needed.
This may indicate that the package content has changed.This is expected behavior. The checksum in this documentation may be outdated because it gets updated with every release. The package will still download successfully despite the warning.
To resolve the warning: Copy the new checksum value shown in the warning message and update your
cdf.tomlwith it. For example, if the warning showssha256:da2b33d60c66700f..., update your config to:[library.cognite]
url = "https://github.com/cognitedata/library/releases/download/latest/packages.zip"
checksum = "sha256:da2b33d60c66700f..."
Step 2: Add the Module
Run:
cdf modules init .
Disclaimer: This command will overwrite existing modules. Commit changes before running, or use a fresh directory.
Step 3: Select the Dashboards Package
From the menu, select:
Dashboards: Streamlit dashboards and visualization modules
Then select Contextualization Quality Dashboard.
Step 4: Verify Folder Structure
After installation, your project should contain:
modules/
└── dashboards/
└── context_quality/
Step 5: Deploy to CDF
Build and deploy:
cdf build
cdf deploy --dry-run
cdf deploy
Note: Function Deployment Time
After running
cdf deploy, the Cognite Function (context_quality_handler) may take 2-5 minutes to fully deploy. The Streamlit dashboard will be available immediately, but the function needs time to initialize before you can run it.If you see "Function not available" when running a batch in the dashboard, wait a few minutes and try again. You can verify deployment status in CDF:
- Navigate to Data management → Build solutions → Functions
- Look for
context_quality_handlerand check its status
Running the Dashboard
- Configuring data model views
- Running batch processing
- Using the local script for large datasets
- Troubleshooting common issues
- Metrics reference
See the full documentation: Context Quality README on GitHub
Support
For troubleshooting or deployment issues:
- Refer to the Cognite Documentation
- Contact your Cognite support team
- Join the Slack channel #topic-deployment-packs for community support and discussions