Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support

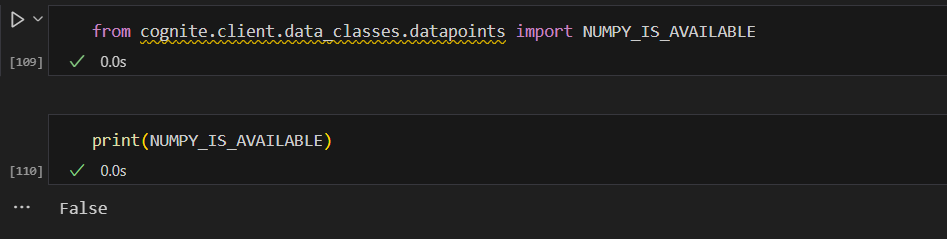
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[97], line 1
----> 1 c.time_series.data.retrieve_dataframe(id=239507005016003,
2 end='1000w-ago',
3 aggregates=["average","sum"],
4 granularity="1h")
File c:\Users\Sudil\OneDrive - Creative Technology Solutions (Pvt) Ltd\Desktop\DataEngBasics\using-cognite-python-sdk\.venv\lib\site-packages\cognite\client\_api\datapoints.py:975, in DatapointsAPI.retrieve_dataframe(self, id, external_id, start, end, aggregates, granularity, limit, include_outside_points, ignore_unknown_ids, uniform_index, include_aggregate_name, include_granularity_name, column_names)
973 fetcher = select_dps_fetch_strategy(self, user_query=query)
974 if not uniform_index:
--> 975 return fetcher.fetch_all_datapoints_numpy().to_pandas(
976 column_names, include_aggregate_name, include_granularity_name
977 )
978 # Uniform index requires extra validation and processing:
979 grans_given = {q.granularity for q in fetcher.all_queries}
File c:\Users\Sudil\OneDrive - Creative Technology Solutions (Pvt) Ltd\Desktop\DataEngBasics\using-cognite-python-sdk\.venv\lib\site-packages\cognite\client\_api\datapoints.py:175, in DpsFetchStrategy.fetch_all_datapoints_numpy(self)
173 def fetch_all_datapoints_numpy(self) -> DatapointsArrayList:
174 with get_priority_executor(max_workers=self.max_workers) as pool:
--> 175 ordered_results = self._fetch_all(pool, use_numpy=True)
176 return self._finalize_tasks(ordered_results, resource_lst=DatapointsArrayList)
File c:\Users\Sudil\OneDrive - Creative Technology Solutions (Pvt) Ltd\Desktop\DataEngBasics\using-cognite-python-sdk\.venv\lib\site-packages\cognite\client\_api\datapoints.py:228, in EagerDpsFetcher._fetch_all(self, pool, use_numpy)
227 def _fetch_all(self, pool: PriorityThreadPoolExecutor, use_numpy: bool) -> List[BaseConcurrentTask]:
--> 228 futures_dct, ts_task_lookup = self._create_initial_tasks(pool, use_numpy)
230 # Run until all top level tasks are complete:
231 while futures_dct:
File c:\Users\Sudil\OneDrive - Creative Technology Solutions (Pvt) Ltd\Desktop\DataEngBasics\using-cognite-python-sdk\.venv\lib\site-packages\cognite\client\_api\datapoints.py:262, in EagerDpsFetcher._create_initial_tasks(self, pool, use_numpy)
260 ts_task_lookup, payload = {}, {"ignoreUnknownIds": False}
261 for query in self.all_queries:
--> 262 ts_task = ts_task_lookup[query] = query.ts_task_type(query=query, eager_mode=True, use_numpy=use_numpy)
263 for subtask in ts_task.split_into_subtasks(self.max_workers, self.n_queries):
264 future = pool.submit(self.__request_datapoints_jit, subtask, payload, priority=subtask.priority)
File c:\Users\Sudil\OneDrive - Creative Technology Solutions (Pvt) Ltd\Desktop\DataEngBasics\using-cognite-python-sdk\.venv\lib\site-packages\cognite\client\_api\datapoint_tasks.py:1286, in ParallelUnlimitedAggTask.__init__(self, **kwargs)
1285 def __init__(self, **kwargs: Any) -> None:
-> 1286 super().__init__(**kwargs)
1287 # This entire method just to tell mypy:
1288 assert isinstance(self.query, _SingleTSQueryAggUnlimited)
File c:\Users\Sudil\OneDrive - Creative Technology Solutions (Pvt) Ltd\Desktop\DataEngBasics\using-cognite-python-sdk\.venv\lib\site-packages\cognite\client\_api\datapoint_tasks.py:1140, in BaseConcurrentAggTask.__init__(self, query, use_numpy, **kwargs)
1138 def __init__(self, *, query: _SingleTSQueryAgg, use_numpy: bool, **kwargs: Any) -> None:
1139 aggregates_cc = query.aggregates_cc
-> 1140 self._set_aggregate_vars(aggregates_cc, use_numpy)
1141 super().__init__(query=query, use_numpy=use_numpy, **kwargs)
File c:\Users\Sudil\OneDrive - Creative Technology Solutions (Pvt) Ltd\Desktop\DataEngBasics\using-cognite-python-sdk\.venv\lib\site-packages\cognite\client\_api\datapoint_tasks.py:1169, in BaseConcurrentAggTask._set_aggregate_vars(self, aggregates_cc, use_numpy)
1167 self.dtype_aggs: np.dtype[Any] = np.dtype(np.float64)
1168 else: # (.., 1) is deprecated for some reason
-> 1169 self.dtype_aggs = np.dtype((np.float64, len(self.float_aggs)))
NameError: name 'np' is not definedThe packages in virtual environment.