Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support

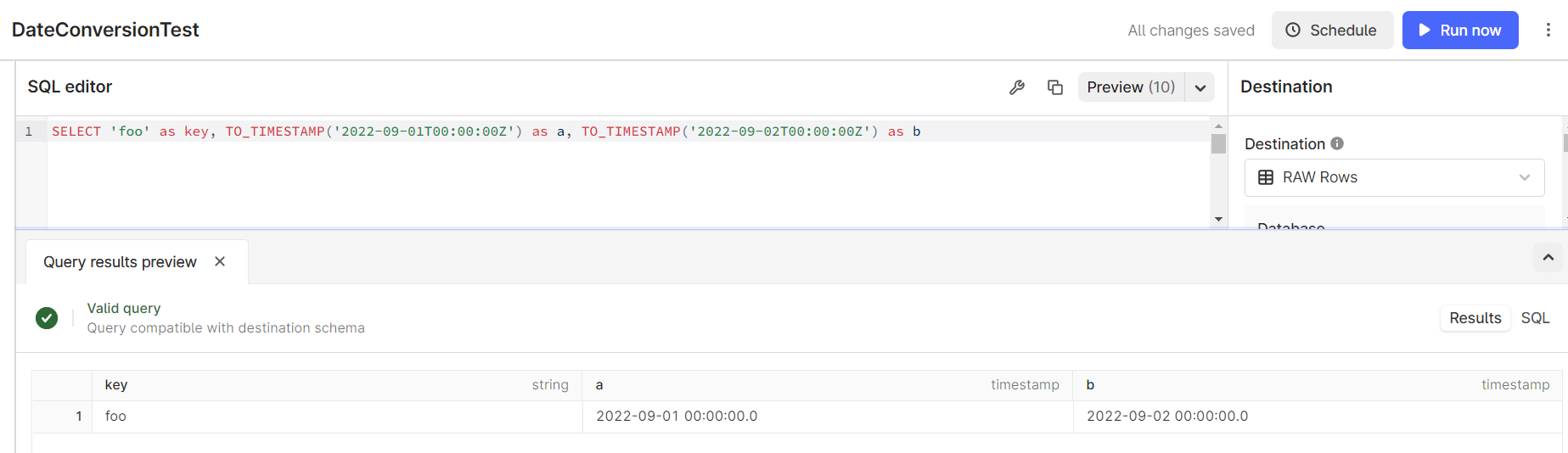
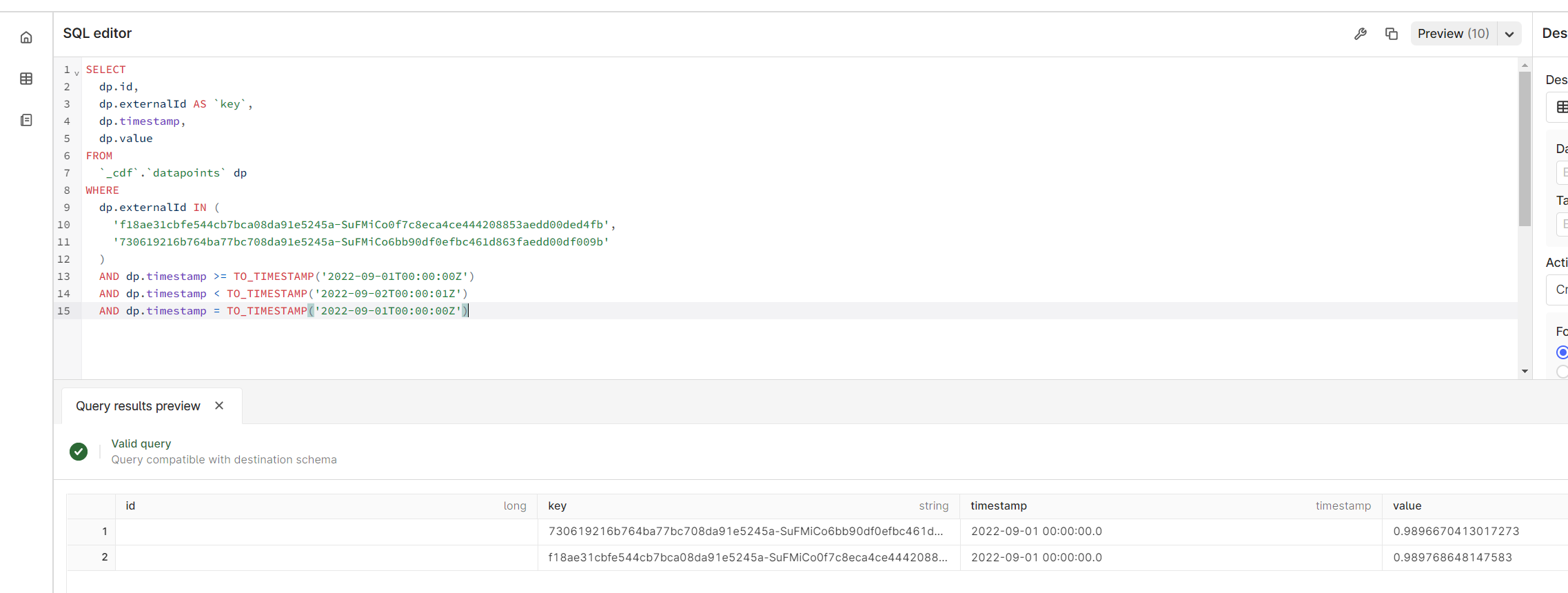
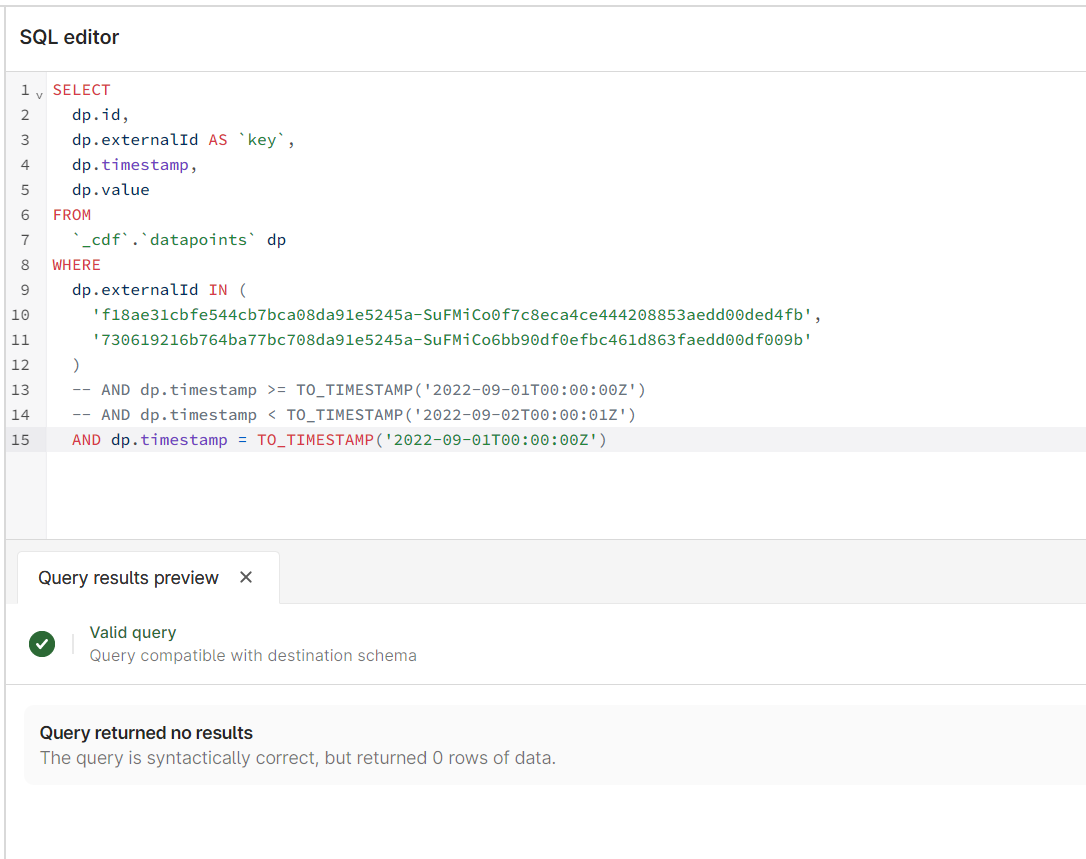
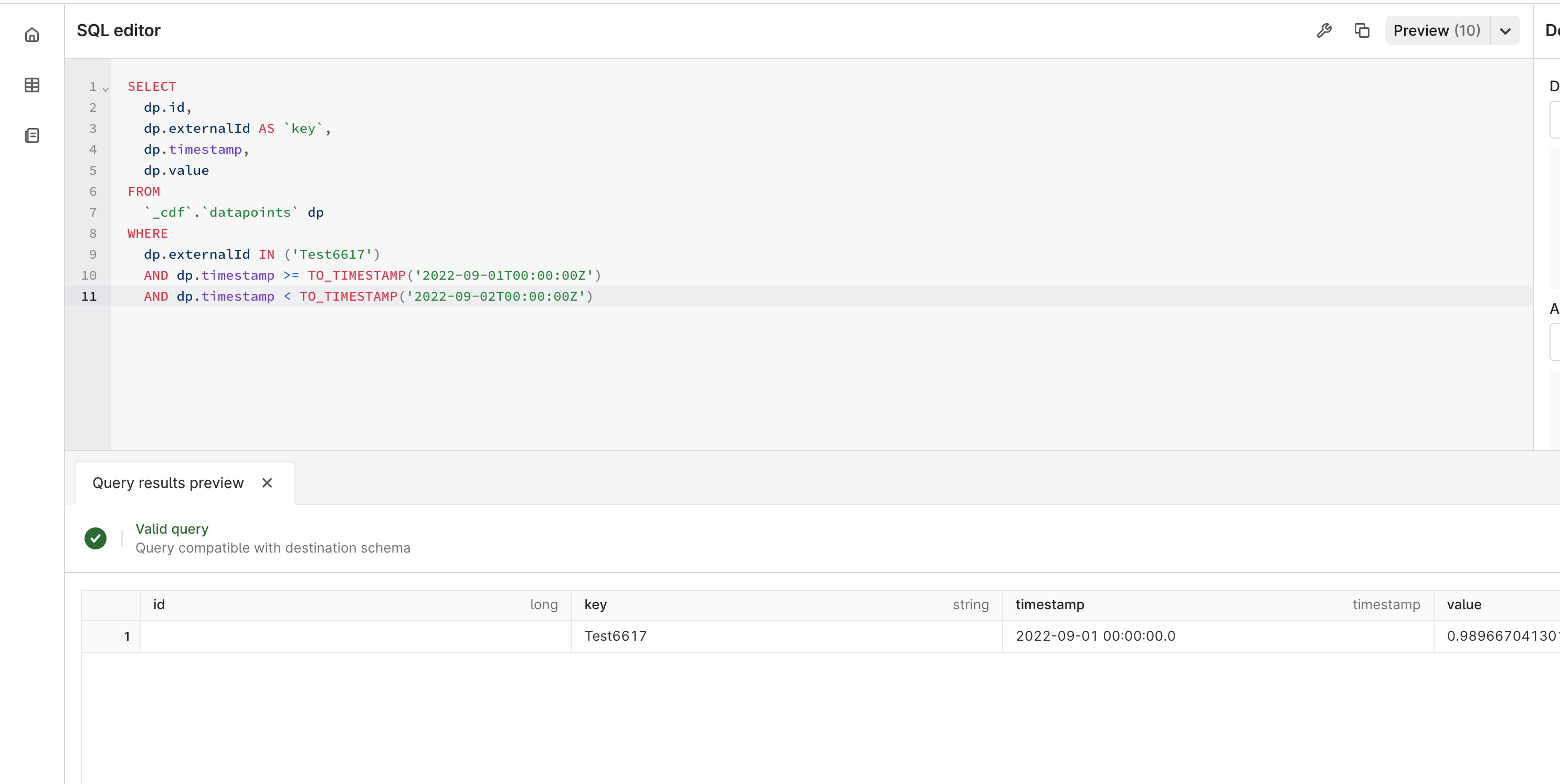
When I run the query below, I am getting an error. If I increase the end time by 1 second I can get a result, but it gives me 2 days and I only want 1. All my data is consistently daily at midnight, UTC. Any ideas how to get past this?
SELECT
dp.id,
dp.externalId AS `key`,
dp.timestamp,
dp.value
FROM
`_cdf`.`datapoints` dp
WHERE
dp.externalId IN (
'f18ae31cbfe544cb7bca08da91e5245a-SuFMiCo0f7c8eca4ce444208853aedd00ded4fb',
'730619216b764ba77bc708da91e5245a-SuFMiCo6bb90df0efbc461d863faedd00df009b'
)
AND dp.timestamp >= TO_TIMESTAMP('2022-09-01T00:00:00Z')
AND dp.timestamp < TO_TIMESTAMP('2022-09-02T00:00:00Z')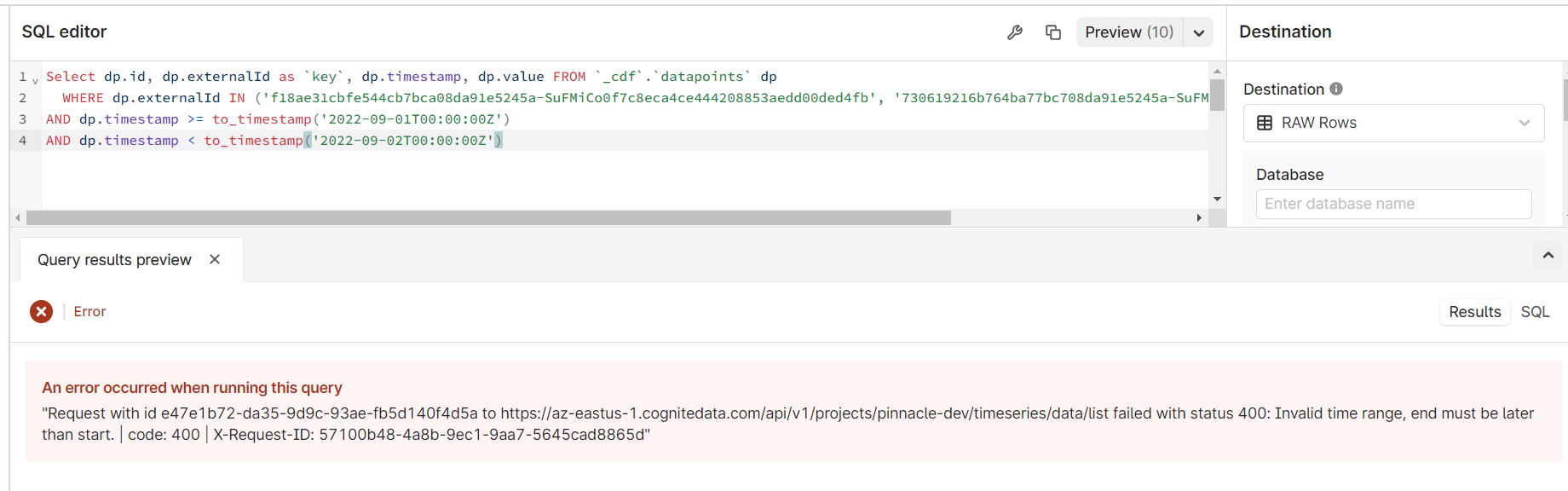
Gives me a result, but not what I want:
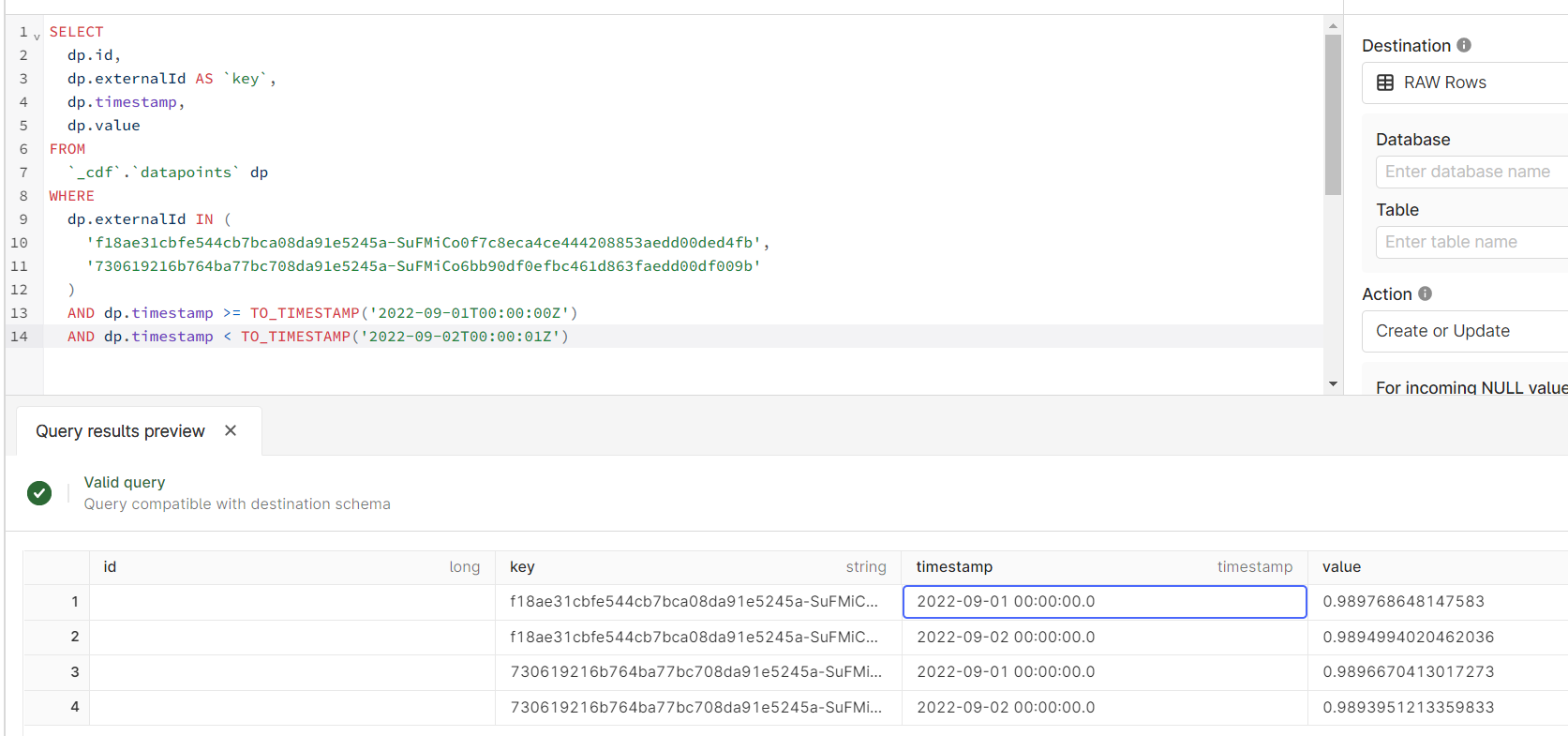
cc