Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support

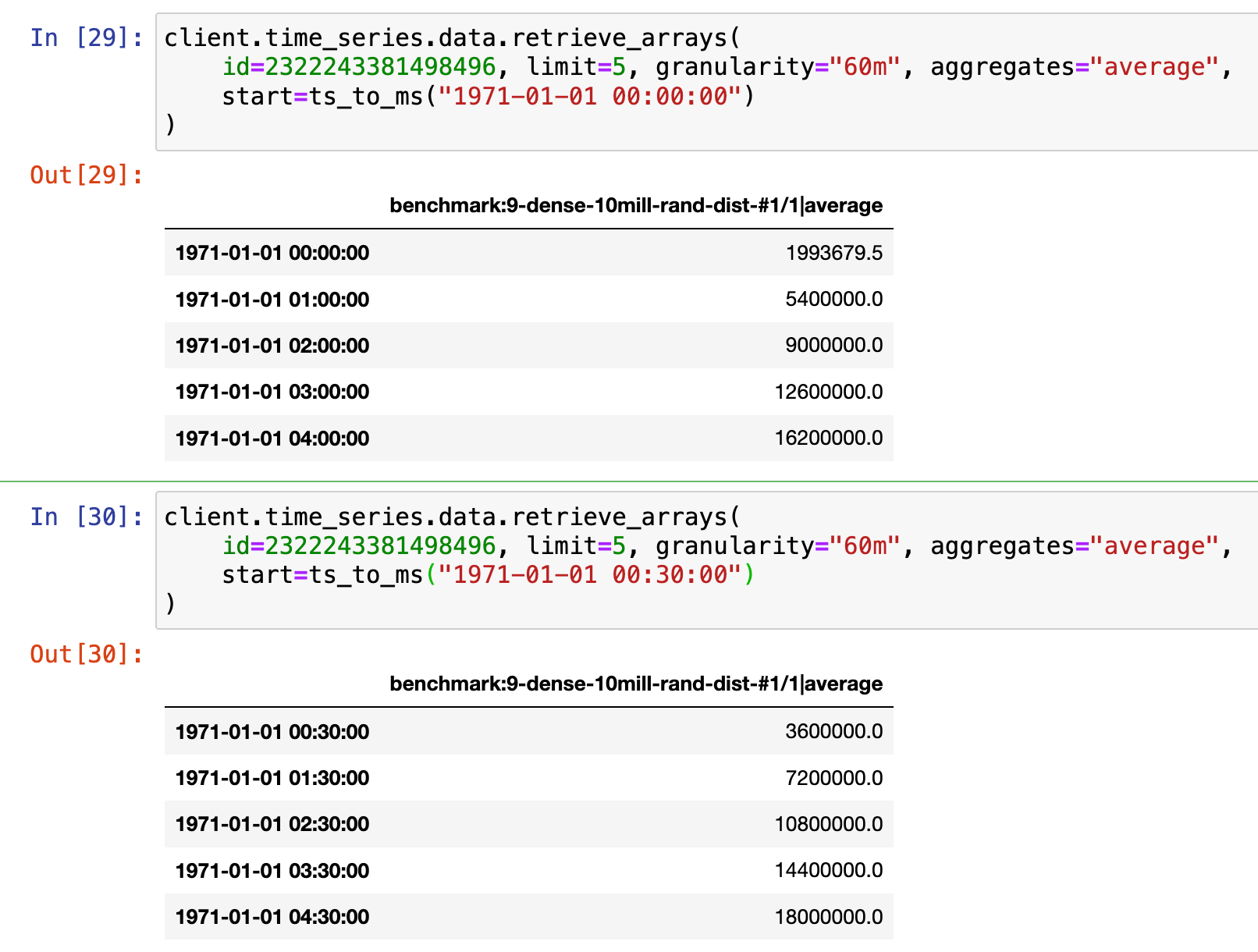
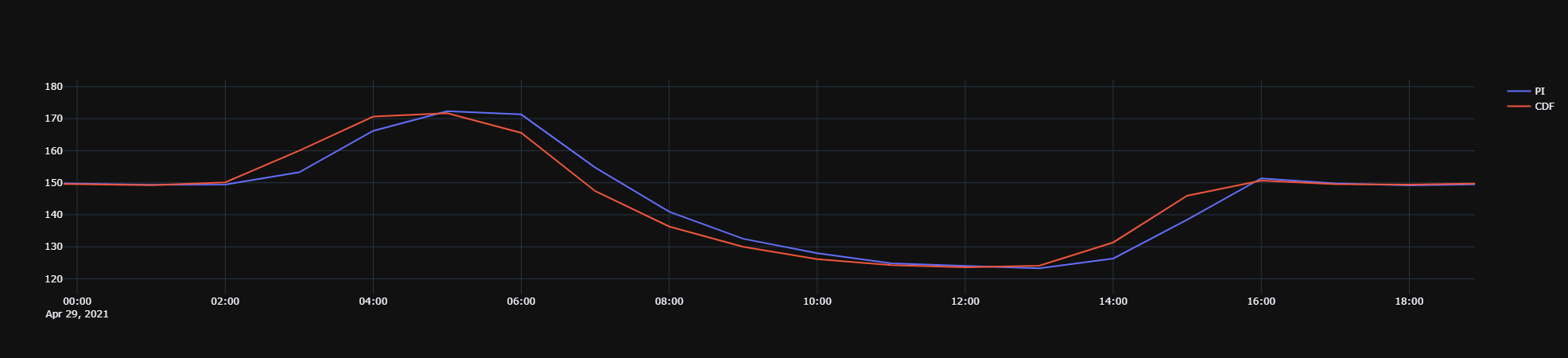
I am making comparisons between time series data in CDF and PI. The reason is that in our tenants the CDF data is not 100% accurate compared to PI.
However, from my testing I think that PI performs its aggregations with the timestamps “centered” at the aggregated time periods, while CDF puts the timestamps at the start of each aggregated period. Is it possible to specify how this is done with the Python API? From my study of the docs it appears not to be the case. The same applies to the PI Web API as well: I cannot specify how the timestamps are placed. The agreement with PI becomes significantly better if I place the CDF timestamps at the center of the aggregated time periods.
My current workaround is the following:
- Fetch RAW data from CDF
- Shift the timestamps by 0.5x of the granularity
- Resample to the desired granularity
- Compute mean
- Interplate any missing values
The issue is that fetching raw data is a lot more time consuming than fetching aggregates. I have been playing with fetching aggregates from CDF and performing the shift after the fact, but this does not lead to as good agreement. I have also played around with speeding up the raw data ferch by chunking the time periods and fetching with multiple threads or processes, but the speedup is not significant.
Here is an example of how I do the CDF raw data fetch in order to get good agreement.
ts = self.cdf_client.time_series.data.retrieve_dataframe(
external_id=get_ts_external_id_from_name(name=self.ts_name, client=self.cdf_client),
start=self.start_time,
end=end_time,
aggregates=None,
granularity=None,
limit=None
).tz_localize("UTC").tz_convert("CET").shift(0.5, self.sampling_interval).resample(self.sampling_interval).mean().interpolate()