

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support

It's been a while, but as promised, here is the follow-up post to my previous article. If you haven't read the previous article, you can find it here.
In the first part, I shared the basic concepts about data integration. Today I will continue on the same theme, but the focus will be on latency and frequency. They are related concepts, but not necessarily the same. Why latency and frequency? They are crucial to defining your data pipeline, and they influence which Azure resources you use to cover your needs.
What is data latency and frequency? Data latency is how fast/slow data can be retrieved or stored. Low latency means that the data is available in real-time or close to real-time and is vital in use cases where you need to respond quickly to information. Examples are alerts for critical events on machinery and equipment and online games based on real-time experiences. This leads us to the data frequency concept. Data frequency is how many times in a specific period the data should be retrieved or stored.
The different Azure resources available for data integration can work on high/low latency and high/low frequency. The main difference is how they are designed and the associated cost. The main design difference between Azure Functions and Azure Databricks, Azure Data Factory, and Azure Synapse Analytics is that Functions does not require a warm-up to execute the data pipeline. The other options require a warm-up phase. So, if you plan to have a low latency data pipeline, that's one of the things you need to consider when you design your solution. With Functions, the pricing is based on execution, so that does not affect the cost. For the other options, the pricing is based on a combination of execution and run time or on run time only. For example, suppose your choice is to use Apache Spark (Databricks and Synapse Analytics) to support low latency. In that case, you will need to keep the Apache Spark Clusters running for the duration that your data is being retrieved.
You should also consider the pricing model for data frequency. If you only need low frequency, pricing does not affect your choice, and it comes down to your preferences and other needs. You may consider the execution time, but most of the time, that is not a concern. If you need high frequency, you need to do a cost analysis, especially if you're considering Data Factory, as the pricing is based on execution + run time. One option is to integrate the high-frequency data with Functions instead. Apache Spark can also be an alternative, but as always, it's essential to do a cost analysis before choosing the best approach.
In general, I use the following guidelines based on Azure costs, but if you add other criteria, the decision can be different:
- Low latency and low/high frequency: Azure Functions
- High latency and high frequency: Azure Functions
- High latency and low frequency: Any
In the image below, I also considered the development and maintenance costs for the scenarios I was working on. The frequency of the data was low as I was not working with live data.
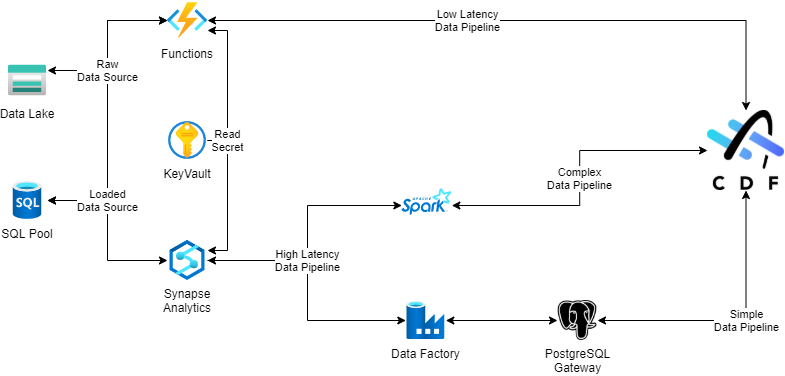
Also, I did not need low latency, but I added it in case I'd need it later. Azure Functions pricing accepts consumption mode, so I only pay per usage and not to provision my resource. If and when I require low latency, I'll review my design to define how to approach high/low frequency. You can notice that I use complexity on development and have added it to decide when to use Apache Spark or Data Factory in my Synapse Analytics environment. I will detail it later, but Data Factory offers a low code platform that allows you to easily create a data pipeline. The platform has low flexibility to solve more complex needs. It is not impossible to implement complex use cases, but it will require a lot of effort, and you will lose the best part of the tool. For complex needs, it is better to use an Apache Spark notebook.
That is all that I have to share today. Next time, I will discuss other data integration concepts that you need to consider to choose the right resource. Meanwhile, do not hesitate to contact me with any questions. And if you have ideas on how to solve your different needs to integrate with Cognite Data Fusion using Azure, please share your thoughts with our Developer Community.
Thanks and have a great week!
Patrick Mishima, Product Specialist - Data Integration and Governance