

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support

Hi everyone,
I'm loading sequences from a file that has 11 million rows, and I would like to load it in batches, where each batch is a dataframe. As I load by batch, the rows that the sequence already had are being deleted, leaving only the last batch. How can I load each batch without deleting the previous one?
This is the code I use to read the file in batches and load rows into the sequence. It is assumed that the sequence is already created.
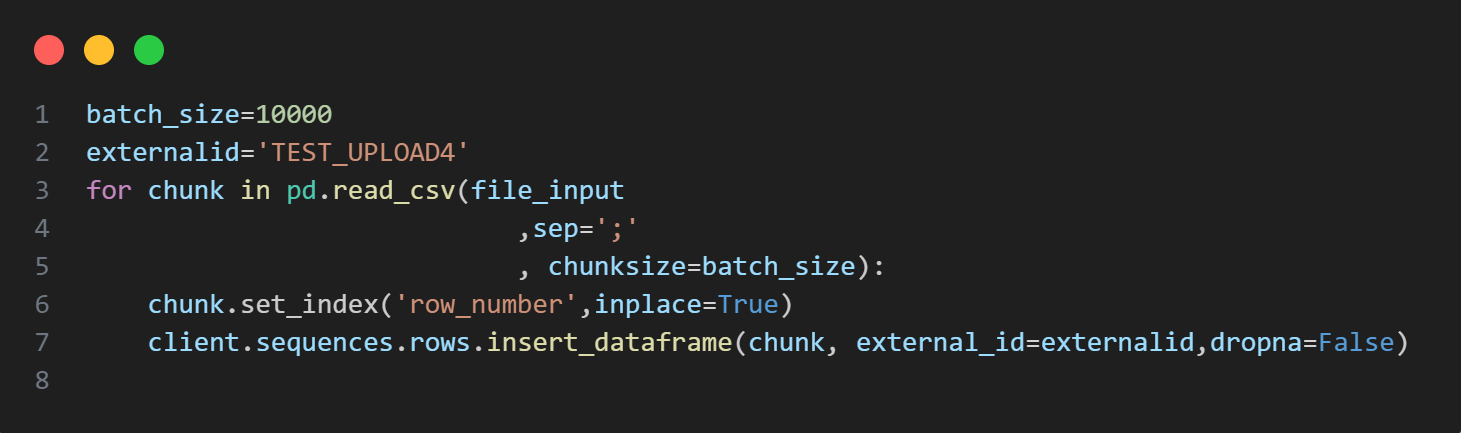
Regards,
Karina Saylema



