

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


“Data has no value unless the business trusts and uses it”

There is no shortage of data in any industrial company, but there is a general lack of understanding on how to extract it, bring it together, and use it in an actionable way.
There are two discomforting truths within digital transformation across our key industries; energy, utilities, and manufacturing:
-
Digitalization PoCs are commonplace. Real ROI isn’t.
-
Billions are invested in cloud data warehouses and data lakes. Most data ends there, unused by anyone for anything.
At the heart of this data-driven value dilemma lies a confluence of challenges, ranging from the technical (How can we best organize our diverse and fluid data universe?) to the operational (How can we create new information products and services?), to the financial (How can we treat data as an asset?), to the human (How can we improve data literacy and ensure digital solution adoption in the field?).
With more and more of our industrial operations data readily in the clouds, Chief Data Officers (CDO) are confronted with the hard reality that moving data to the cloud is not even a third of the journey to value. As Forrester (2021) put it elegantly, “data has no value unless the business trusts it and uses it.”
Solving the data quality challenge is however not as straightforward as filling cloud data warehouses and data lakes have been. Investing millions into another doomed MDM project — only this time for the cloud — is equally erroneous. Instead, adopting a data product-centric mindset, along with a DataOps practice to create and manage data products, is needed.
The convergence of data and analytics has made Industrial DataOps an operational necessity. The focus of DataOps is the delivery of business-ready, trusted, actionable, high-quality data, available to all “smart engineers” or “data consumers.”
The shift from data availability to data products as a service is what will transform our data swamps into operational data lakes of real business value. Implementing Industrial DataOps to collaboratively develop, manage, and operationalise data products is how you get there.
To guide you, we've summarized the journey from data fabric to DataOps to data products:
Data productization creates data that speaks human. DataOps is how you get there. Breaking down monolithic enterprise architecture thinking is where you start
| Data Fabric | DataOps | Data Product |
| “Dynamically orchestrating disparate data sources intelligently and securely in a self-service manner and leveraging various data platforms to deliver integrated and trusted data to support various applications, analytics, and use cases.” | “People, process and technology that aims at making data available quickly, securely and in a timely manner to support multiple roles in an organization. DataOps focuses on end-to-end automation, self-service, integration and trusted data in close alignment with business objectives.” |
"A component that ingests and delivers data used by an insight solution for decisions and actions. Data products are analogous to an app product for developers.” |
Drowning in data, starving for context
It is not the data alone that holds the keys to value, but our ability to understand and operationalize the data. The key to creating value from data lies in data context and interpretability by data consumers in business operations.
“Data needs to become self-explanatory to data consumers without needing subject matter expert support. A company is digitally mature when they can enable citizen data scientist and citizen developers to do more with advanced data and analytics.” - Forrester
For data to be operationally used at scale, especially for critical operations, it needs to be trusted. For data to be trusted, it needs to be productized.
Common data product challenges:
- No easy way to find which data assets are available
- No ownership model for existing data assets
- No documentation of existing data
- Many current data sets are not directly available
- Difficult to compile data across
- Data is exported to external parties ad-hoc
Cost to business:
- Poor data utilization
- Slow innovation
- Delayed and poor decision making Loss of business confidence towards IT Information management risks
Think beyond data lakes
Adopting a data product-centric mindset, along with a DataOps practice to create and manage data products, is needed. To successfully implement Industrial DataOps, it is essential to move from a conventional centralized data architecture into a domain data architecture (also referred to as data mesh).
For domain data architecture to work, the data product owner teams need to ensure their data is discoverable, trustworthy, selfdescribing, interoperable, secure, and governed by global access control. In other words, they need to manage their data products as a service, not as data.
| Data Fabric delivers a modern data architecture | Data Fabric and data platforms enable DataOps | DataOps enables data products |
| As the volume, velocity and variety of data and data consumers keep exploding, data semantics (metadata, context) become the focal point, with graph data structures the obvious solution. | DataOps offers a workbench for data quality, transformation, and enrichment, as well as intelligent tools to apply industry knowledge, hierarchies, and interdependencies to contextualize and model data. | To avoid MDM dead-end, data management is decentralizing into data domains producing data products ("tradeables"). Data products represent your data itself being “packaged” into a true self-service product experience for the data products’ customers. |
Use DataOps to deliver contextualized data to both SMEs and professional data scientists
Industrial DataOps is about breaking down silos and optimizing the broad availability and usability of industrial data generated in asset-heavy industries. Automating the data process is the only way to make sure that live data triumphs over static documentation and reports in the decision-making process.
Here is a convenient guide to understanding the key characteristics of horizontal DataOps, as well as which features to look out for that will significantly catalyze success with DataOps adoption for heavy-asset organisations confronted with a somewhat different data source, data type, data quality as well as data consumer landscape.
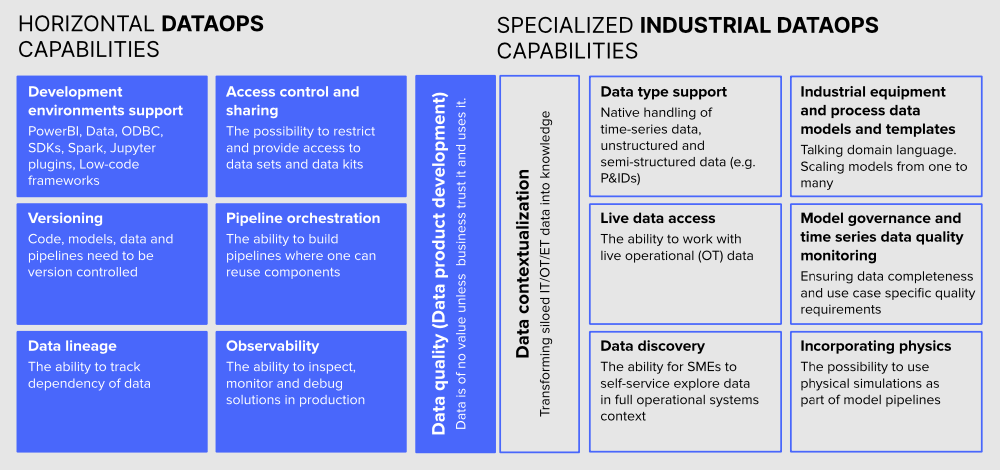
DataOps enables efficient development, operationalization and scaling of digital solutions through supporting both data owners and consumers with a common toolset.
Think in data products, execute in data domains
The shift from data availability to data products as a service is what will allow us to transform our data swamps into operational data architectures of real business value.
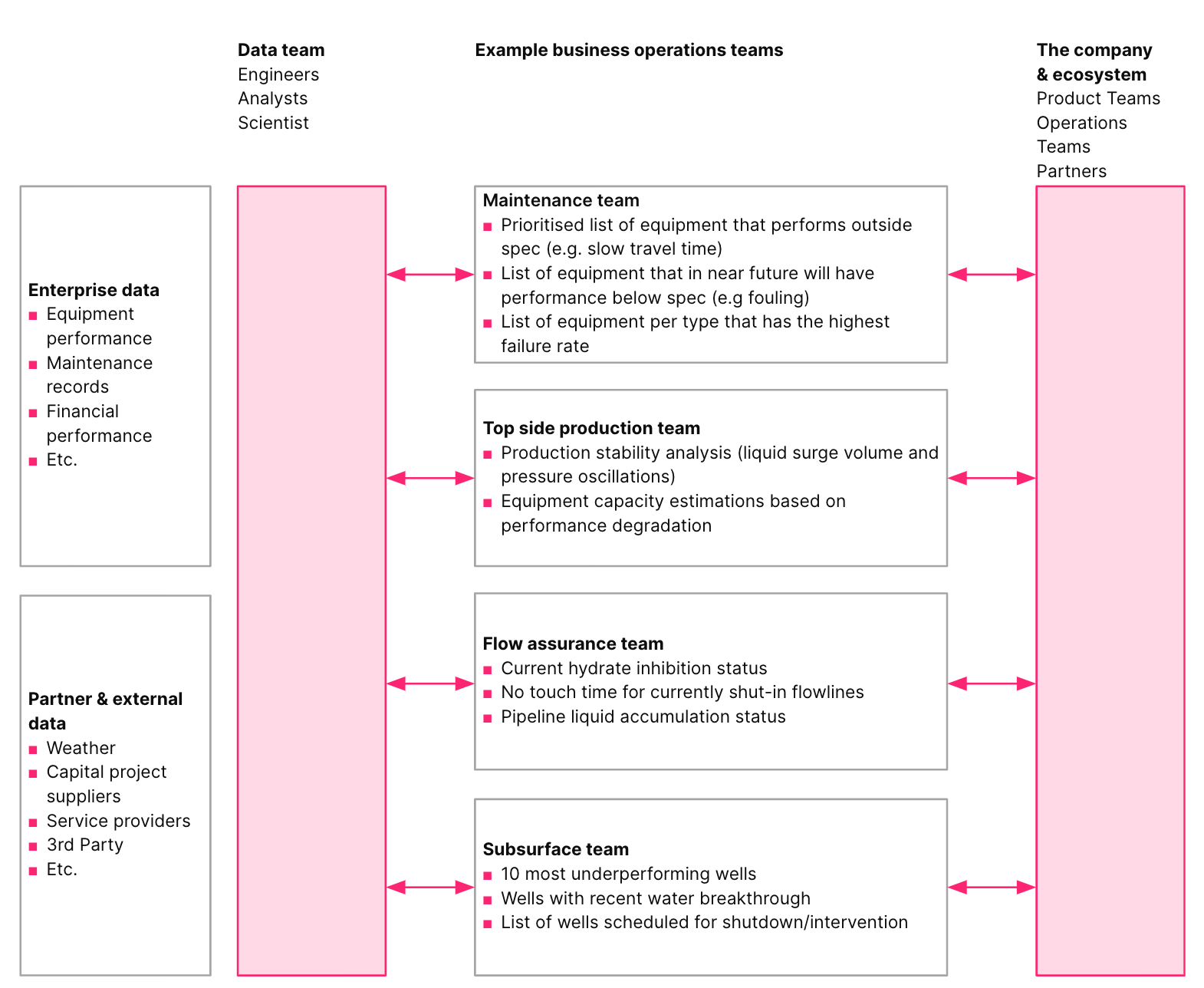
To productize your data, focus on the most valuable operational data domains first, not on the enterprise-wide master data landscape all at once. The necessary move is from a centralized data team, such as digital or data center of excellence, into a collaborative setup, where each data domain is co-owned by the respective business function producing the data in their primary business tools.
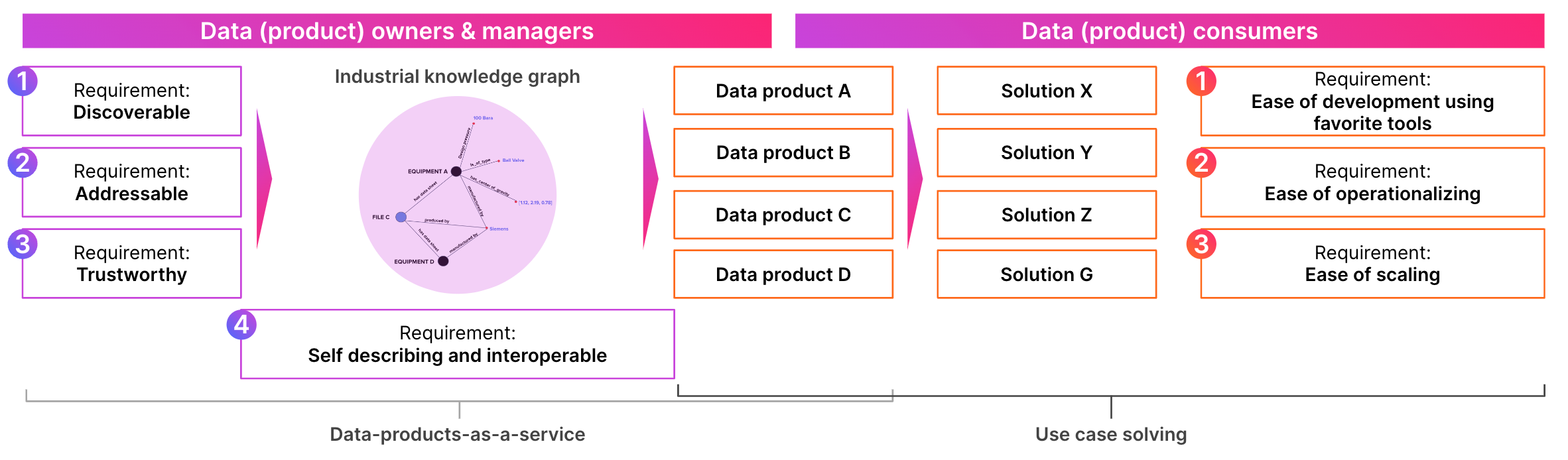
Data products usage shows where true data value lies. As you are measuring data product use and not raw table queries, you obtain valuable insights into how your data landscape needs to be refined further, to be even more purposeful and valuable for business.
Empower the smart engineer
As industrial organizations will increasingly rely on the work of smart engineers, individuals and interactions (far more than processes and tools) are essential to make data valuable and useful for data consumers across an organization. Not traditional data professionals, but subject matter experts empowered with the right capabilities and practices to harness data effectively.
View “The journey from data fabric do DataOps to data products” infographic as a PDF
Industrial DataOps, or data operations for industry, is the clear frontrunner to become a driving force for transformation in the industry.
- This happens first by making your data available, by identifying where it is, how to get at it—and how to store it for later use
- The next step is then making your data useful—freeing it from silos and making it speak “human”, so that its value can be released across operations. Contextualize it and design homes for it such that all of the minds and functions in your organization can actually understand it, use it, and innovate on top of it.
- And finally, making data valuable. Extracting the maximum value depends on being able to obtain insights that inform better decisions, and enabling all business users to become solution creators. Scaling these benefits brings data value to the whole organization.
To learn more about Cognite Data Fusion, we recommend this post.
Did this article cause some reflections? We’d love to hear from you and your experience.
Published originally at: https://www.cognite.com/en/blog/the-journey-from-data-fabric-to-dataops-to-data-products