

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


Anatomy of a contextualization engine for AI use case scaling in industry
If there is one thing we at Cognite get a lot of questions on, it’s contextualization. Not so much what is contextualization (luckily we are getting past that phase now), but specifically on two subsequent topics:
- How does your contextualization engine actually work?
- How does contextualization make use case scaling order of magnitude (or two!) more efficient?
In this article, we will address both the above questions. We will also offer an ‘executive summary’ on data contextualization and its role in modern data management towards the end for completeness. Let’s dive in!
Read also: The data liberation paradox: drowning in data, starving for context
How does Cognite Data Fusion contextualization engine work?
First, it is paramount to set some foundations:
- There is no such thing as the ideal universal data model. Having some pre-defined reference data model (can be based on industry-standard where applicable, or only using an asset hierarchy as reference) is useful, as such supports more efficient mapping towards application/use case-specific data models from the reference model. The step of building a reference data model should be a standard part of moving data from sources to applications within your data architecture, as it will represent the beginning of a reusable data asset.
- Contextualization — even with AI/ML — is not magic. For different data sets to be successfully matched and appended into the reference and application data models, matching signals need to be present. Even in the case of weaker matching signals, there remains robust benefit from a data contextualization engine to structure and govern more SME intensive data contextualization work. Excel worksheets simply don’t make sense in any scenario.
- Your data is alive. Your contextualization solution needs to reflect this. Simply put, you just don’t want to do data contextualization manually.
In Cognite Data Fusion, contextualization happens at two complementary levels:
- Horizontal contextualization to connect source system data sets to the reference data model and thus to each other; and
- Vertical contextualization through auto-completion of templates targeting particular use case data schemas
Horizontal contextualization deals with resource matching, P&ID conversion and unstructured document contextualization as part of the data integration process. Vertical contextualization uses templates to auto-complete use case data schemas at scale, using pattern recognition and reinforcement learning in addition to already performed underlying horizontal data set contextualization.
Cognite Data Fusion uses a combination of pre-trained ML-based models, custom ML-based models, rules engine, and manual/expert-sourced mappings with built-in continuous learning for horizontal contextualization. Automatic models are applied to handle changing data.
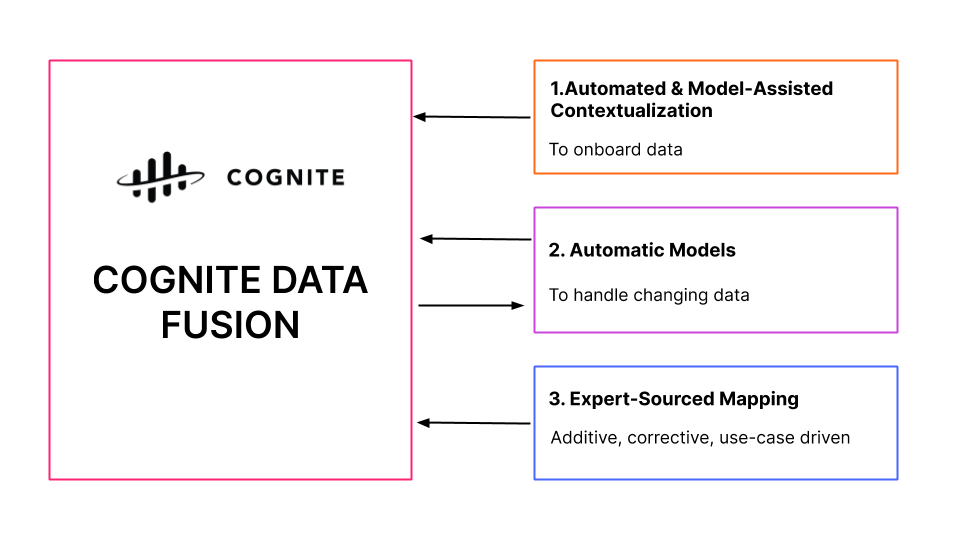
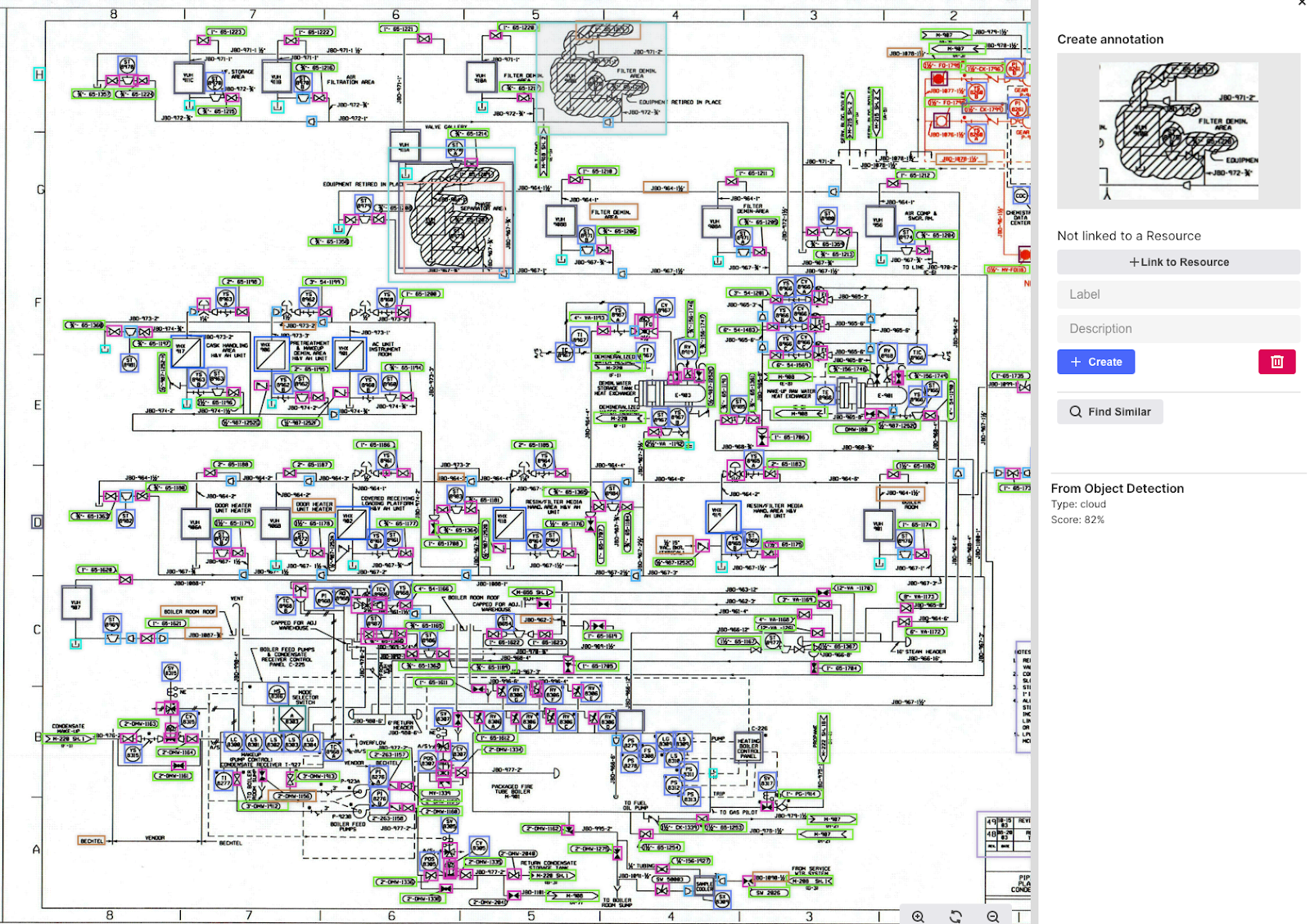
Without going into extensive details on well-understood computer vision and NLP application areas for P&ID contextualization (see screenshot below), or unstructured document contextualization, converting unstructured documents into structured documents with rich metadata is embedded into Cognite Data Fusion’s horizontal contextualization capabilities. As for metadata, both the resulting structured data labels and data relationships all constitute rich, powerful metadata — the key for almost all forms of automation and augmentation in modern data utilization scenarios.
Read more: Metadata is the new data
How does contextualization make use case scaling order of magnitude (and more!) more efficient?
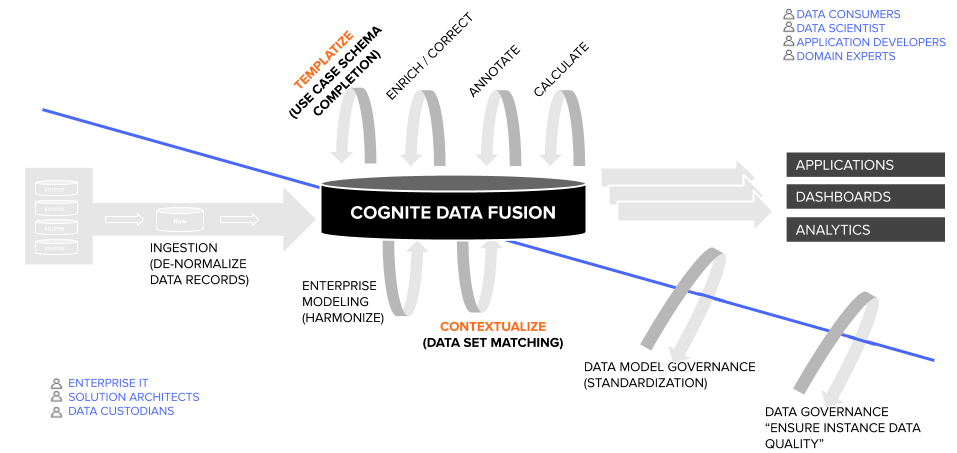
Once a reference data model has been defined — though this step is not strictly required to address individual use case development or scaling (however, we do advise you follow this step as it represents the beginning of a reusable data asset creation) — we can move to use case execution and scaling.
The below illustration depicts how the two ‘realms’ of the data engagement process are interdependent. Below the diagonal line is where horizontal contextualization happens. This is the realm of data management professionals. Above the diagonal line is where use-case solving happens. This is where vertical contextualization takes place. Vertical contextualization refers to the auto-completion of templates targeting particular use case data schemas.
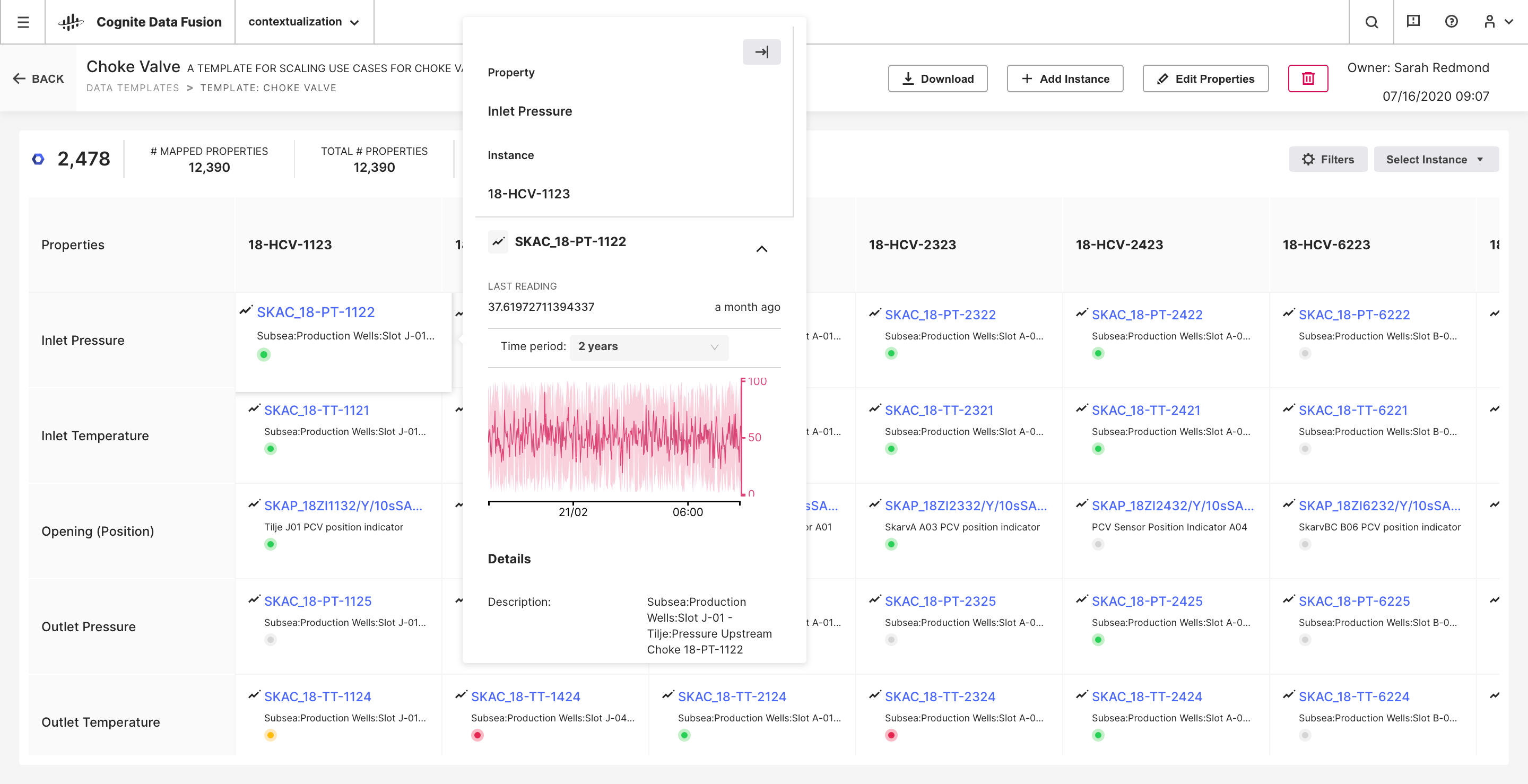
Again, without going into full-fidelity (for which you are more than welcome to request an in-person Cognite Data Fusion product demo), use case schema completion happens through one of Cognite Data Fusion’s customizable templates or a custom template entirely. Data templates and associated AI-driven completion suggestions can be seen in the below screenshot.
Through templates, e.g. each time series sensor data stream, it can have its own data quality monitoring, thus connecting possibly bespoke data quality requirement onto the use case itself, versus the sensor data at large as per classical MDM approaches.
Use case templatization is equally powerful. It encapsulates much of the application complexity — including all data logic —directly at the data layer, making, for example, data visualization scaling from one onto a thousand dashboards a matter of hours. All data templates are, of course, accessible also via Notebook experiences for programmatic use.
Data contextualization is at the core of modern data management
We hope you have learned a thing or two about how an industrially specialized contextualization engine actually works and how contextualization makes industrial use case scaling order of magnitude (or two!) more efficient.

To conclude, we’d like to leave you with an ‘executive summary’ on the role and value of augmented data management delivered through data contextualization.
- Data and analytics leaders responsible for data management are under pressure to deliver projects faster and at a lower cost, driving the need for more automation across the data journey from source to applications at scale.
- Through AI and ML augmentation, multiple diverse structures and insights emerge from the data, creating active metadata, rather than a single structure manually imposed on the data as in traditional MDM. Active, dynamically inferred, and trusted metadata is a common thread and key enabler in making data understandable and useful
- Data contextualization is not only for the IT department (cf. a data platform backend capability). Data contextualization is equally vital for using case solving and scaling and is critical for citizen data science programs to succeed.
Did this article cause some reflections? We’d love to hear from you and your experiences.
Author: Petteri Vainikka. Published originally at: https://www.cognite.com/blog/how-to-scale-use-cases-with-data-contextualization