

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


I have been looking into many work-orders looking for failures or anomalies, but at this point I’m not sure to take the most of the shared information, as example I’ll take the two following events:
The work order 6516382362467974 has the following details available:
-
Description: Exterior leakage - liquid for the main process
-
Shutdown: Revision (full shutdown)
-
Planned Start: 2014-09-11
I also plotted some of the signals from near the planned start, as shown in the below image:
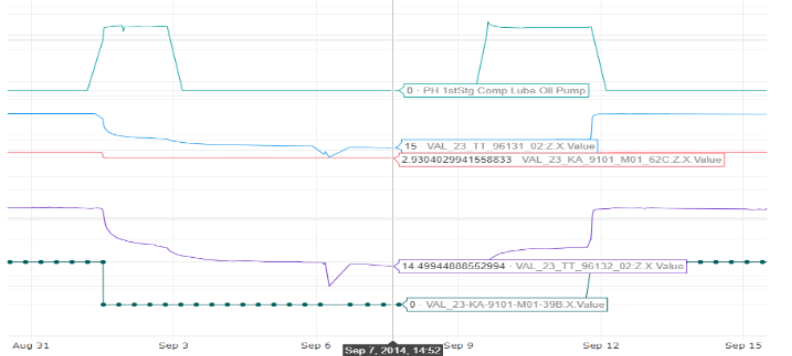
I have a few questions about the first work order:
-
It seems that the compressor turned off about two weeks before the planned start time (As the green dotted line shows) is it safe to assume that is discrepancy is because the two-week delay in sharing the data?
-
Is there a set of signals that I can look into for this work-order, I’m assuming that since there is a leakage, the time series related to lube oil could be affected, or maybe the pressure of the compressor.
The second work order is 5486503211601545, which has the following details available:
-
Description: There is *** too much vibration *** *** to electricity. Engine for *** step ***. Pipes must ***. Ref *** ***.
-
Shutdown: During operation
-
Planned Start: 2013-10-03
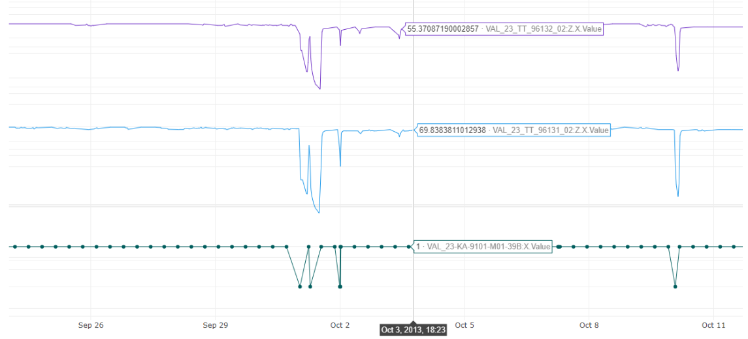
As for this one, there are a few work-orders more that mention high vibration values, my question is, does it make sense to look into the vibration time series like 1stStg Journ BRG DE? Or is this referring to a different source of vibrations?
Besides these two events, I also have a more general doubt regarding the feasibility of doing predictive maintenance from the dataset. The reason for this is that although there is a large volume of data shared, the failure events (if any) are very scarce (which is expected from this sort of process) I mean, is not like the motor bearings have broke down 10 or 20 times and I can make a classification model detect the problem on an early stage. Is this approach of training a classification model feasible for this sort of data or is it a naïve approach?
It seems that the best approach for this dataset is to work on condition monitoring: estimate the wearing of the assets as mentioned in one of the courses shared by Cognite. Now the tricky part is that it even linking some of the assets with maintenance events to reset the wearing counter, I'm not sure what to do with those, since I don't have a reference for the expected lifespan of the asset.
Best answer by Stig Harald Gustavsen
View original
