

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


I'm working on identifying the falling and rising edges of the VAL_23-KA-9101-M01:HSI.StatusMotorOn signal. For that and shifting the TS and rest the values, if I get -1 is a falling edge and for 1 it is a rising edge. For the first row it works fine:
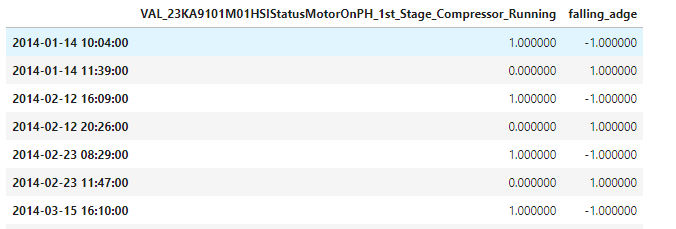
But I’m also getting a lot of values different than 1 or -1. Especially for more recent years. I guess that the problem is at the aggregating step, since I downloaded the data at a 1m frequency I get not int values for some records. Now, I was trying to download this TS at a 1s frequency, but I get a different number of records depending on the year. E.G. for 2014 I get 34 records for a 10 days time windows with a granularity 1m.
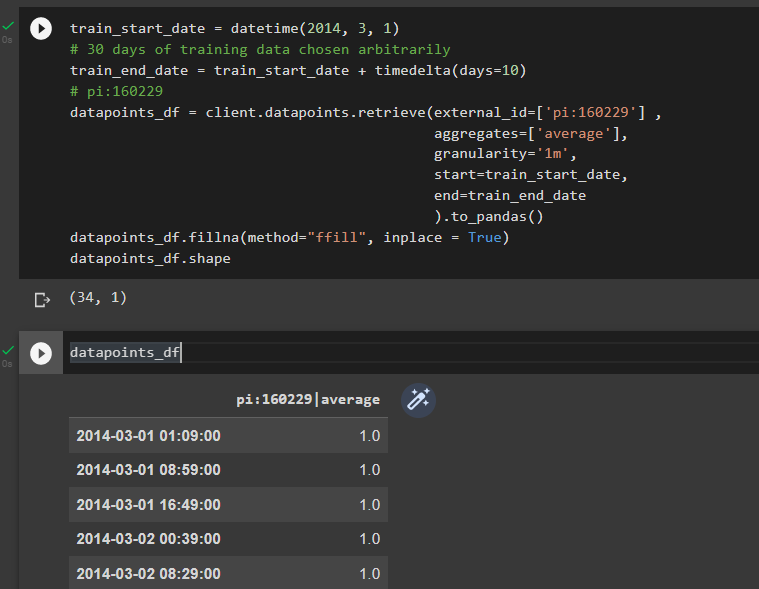
If I do the same but for 2020 I get 1411, much more than for 2014, but still a tenth of the expected count.
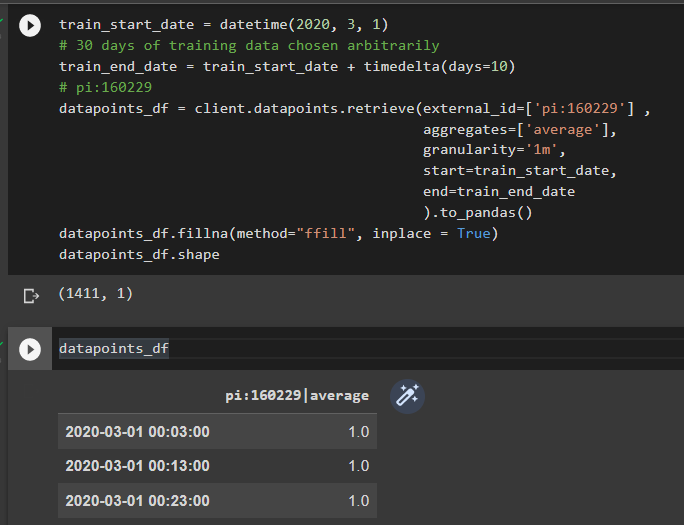
If I change the granularity to 1s, I still get the same number of records, but with more precision in the time stamp:
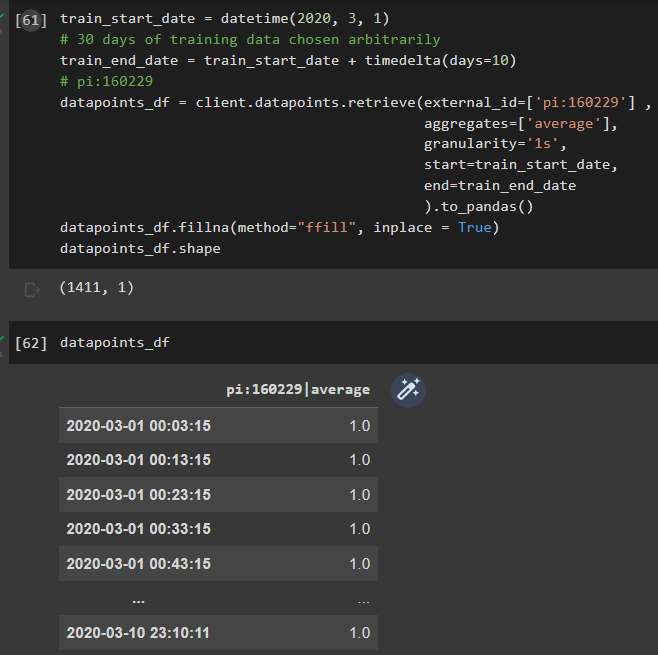
Considering this, is there a recommended granularity to download the data and minimize the distortions in the digital signals?
Best answer by matiasholte
View original
