OPC UA is an open source data standard for communication. It is one of the most used in the industry. OPC UA can for example be used to send data from a machine and its sensors to a computer (or to a cloud service such as Cognite Data Fusion).
In this article, we’ll see how to extract data from an OPC UA data source to Cognite Data Fusion (CDF). For this purpose, we have an off-the-shelf extractor that we simply need to configure and deploy. This extractor is maintained by Cognite. You can find it in CDF under Integrate > Extract data (where you can also find our other extractors: DB, PI etc., you can also create custom extractors).
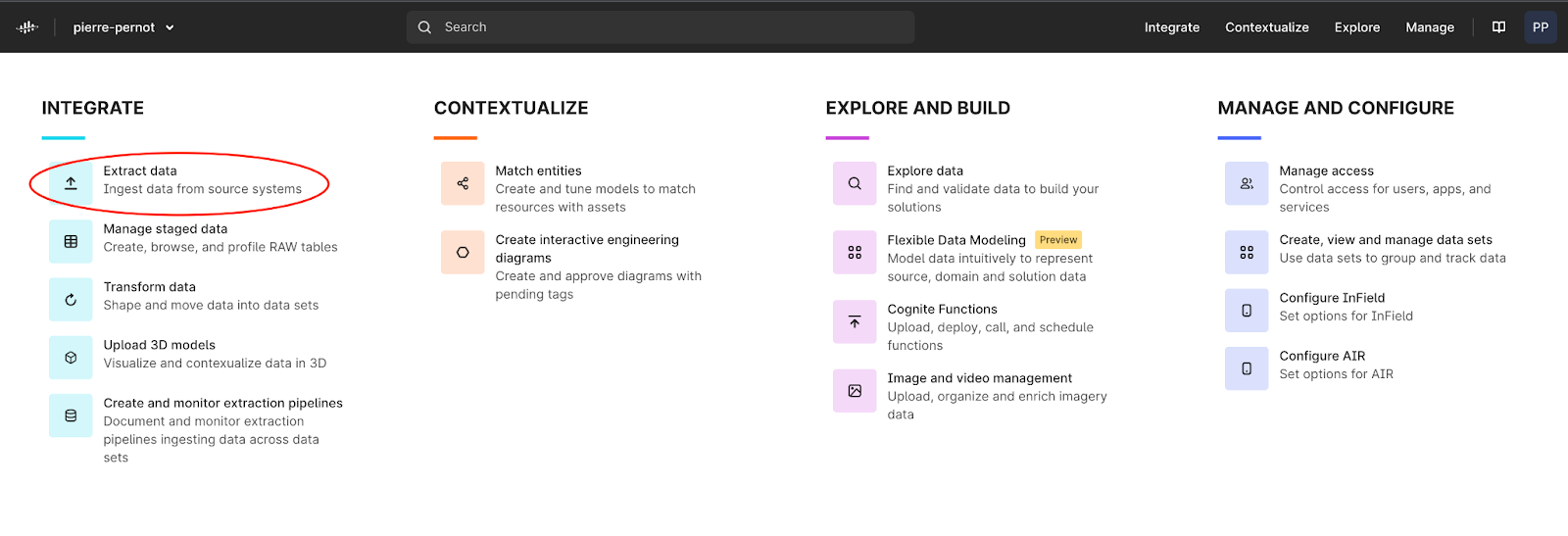
One of the most common and easiest ways to deploy such an extractor is via a Docker image. The fact that it is platform agnostic makes it pretty easy to deploy: you just need docker installed to make it run. Also, everything you need is packaged in the image, you do not need to install or build anything. The Docker images are available on Docker Hub (https://hub.docker.com/r/cognite/opcua-extractor-net/tags).
In this article, we’ll take a look at version 2.9.1. This version introduces the ability to edit the config file remotely from CDF. If you prefer not to use this feature, you can still follow along this article: you’ll simply need to have everything in the same config file and delete the “type: remote” parameter, the rest will be the same.
There are many configuration items available with our OPC UA extractor. In this article, we’ll cover only a few of them, since most of them are use-case specific. If you are interested in knowing more about all of the extractor’s capabilities, please check the documentation (https://docs.cognite.com/cdf/integration/guides/extraction/opc_ua/).
If you do not have any OPC UA datasource to use, you can use Prosys OPC UA Simulation Server for training purposes.
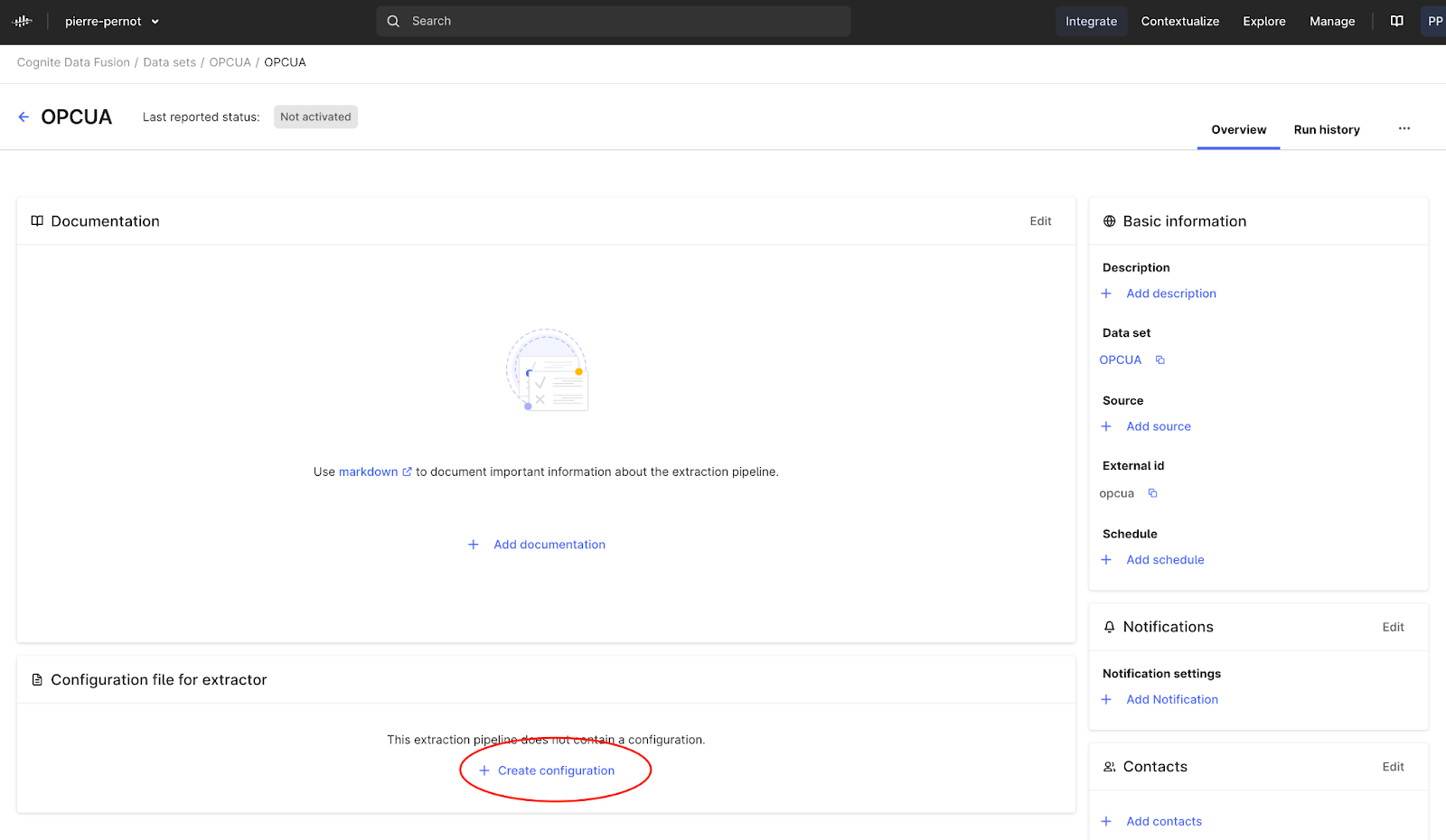
The first step consists in creating an extraction pipeline in CDF.


Fill in the information you need and keep the extraction pipeline’s external ID for the next steps. Once it is created, the second step consists in creating a “config.yml” file in a “config” folder inside of your working directory (the naming convention is important here, it won’t work if you don't respect it).This “config.yml” file will contain all the information related to CDF. It should look like this :
version: 1
type: remote
cognite:
host: ${BASE_URL}
project: ${PROJECT}
idp-authentication:
tenant: ${TENANT_ID}
client-id: ${CLIENT_ID}
secret: ${CLIENT_SECRET}
token-url: ${TOKEN_URL}
scopes:
- ${BASE_URL}/.default
extraction-pipeline:
external-id: “<<YOUR_PIPELINE_EXTERNAL_ID>>”
As a comment, config files support variable substitution, you can refer to an environment variable named MY_ENV_VAR with the following syntax: ${MY_ENV_VAR} (as in the code sample above).
At startup, the extractor attempts to read the configuration files from the extraction pipeline with the mentioned external ID. The extractor continues to check for updates every few minutes.
If you are not using the remote configuration (beta feature), the rest of the configuration will also be in the “config.yml” file mentioned above.
Thanks to the remote configuration feature, every configuration item (except the “cognite” information) can be defined in CDF as follows:
Inside that remote configuration, enter the following:
version: 1
source:
endpoint-url: “<<YOUR_OPC_UA_ENDPOINT>>”
This is the very minimal configuration you need to get your extractor running. If you need to authenticate thanks to a user or certificates, please have a look at the documentation.
Now you can run the following command, in your working directory:
docker run cognite/opcua-extractor-net:2.9.1 -v "$(pwd)/config:/config" –rm Or, if you need certificates:
docker run cognite/opcua-extractor-net:2.9.1 -v "$(pwd)/config:/config" -v "$(pwd)/certificates:/certificates" –rm
If you run that command, you’ll get data extracted and stored as CDF objects.
The data that is now in CDF is probably not the way you would like it to be. The next step of this article consists in fitting the data to our data model. For this, we will make use of the extraction/transformations parameter (not to be confused with Transformations in CDF) which basically allows you to choose how to model (or to ignore) data based on filters.
The sample data I’m using looks like that:
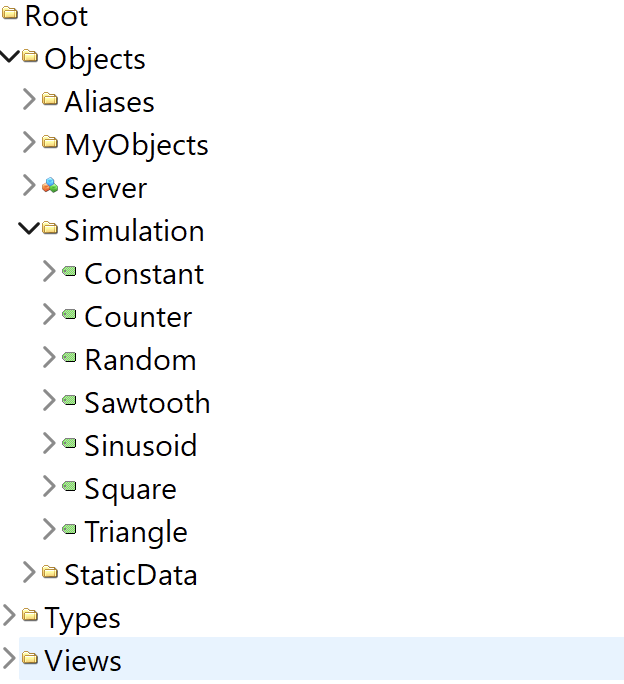
From those nodes, we will keep only the Simulation Object and the Variables under it. The default behavior of the extractor will create an asset for the Simulation object, and timeseries attached to this asset for the Variables. Also, the transformation (type: Property) makes the constant Variable a metadata for the Simulation asset.
First, you’ll have to delete the data you’ve just extracted (to be able to see the changes with the new configuration). Also, stop the running container.
Then, in CDF, in your extraction pipeline configuration, you can edit the configuration itself. Click “Edit”, replace the current config by the one below (adapt to your endpoint URL), and publish the changes. The filter arguments are actually regex that apply here on the display name of the node (check the documentation for all the transformation capabilities). We are also able to select the node that will be the root node (Simulation here) by its node id and its namespace URI (we got those values in UA Expert, which helps a lot for visualizing data). Those values might change in your case, pay attention to put the correct ones.
version: 1
source:
endpoint-url: “<<YOUR_OPC_UA_ENDPOINT>>”
logger:
# Writes log events at this level to the Console. One of verbose, debug, information, warning, error, fatal.
# If not present, or if the level is invalid, Console is not used.
console:
level: debug
extraction:
root-node:
namespace-uri: http://www.prosysopc.com/OPCUA/SimulationNodes/
node-id: 85/0:Simulation
transformations:
- type: Property
filter:
name: "Constant"(in production, you might set the logger console level to something else than debug)
Now run again your docker command :
docker run cognite/opcua-extractor-net:2.9.1 -v "$(pwd)/config:/config" –rm Or, if you need certificates:
docker run cognite/opcua-extractor-net:2.9.1 -v "$(pwd)/config:/config" -v "$(pwd)/certificates:/certificates" –rm
The extractor will now feed data again inside of CDF, in the wanted format.
The Cognite OPC UA Extractor has many configuration settings available, I strongly recommend to have a look at the documentation: https://docs.cognite.com/cdf/integration/guides/extraction/opc_ua/opc_ua_configuration
If you have any questions or remarks about the extractor and its capabilities, feel free to ask :)