This post is a hands-on introduction to the features supported in the Transformations Python SDK.
Prerequisites
Knowledge:
-
Basic knowledge of Azure Functions and Azure Data Factory
-
Basic knowledge of Cognite Data Fusion RAW and SQL Transformations
-
Prior experience with Python, Postgres and SQL
Required Datasets:
Download and Unzip the attached hub.zip file, you should find the below structure
-
Use Case 1 :
-
asset-hierarchy.csv
-
-
UseCase 2:
-
OID-Asset-hirerachy.csv
-
OID-Timeseries.csv
-
OID-Datapoints.csv
-
Use Case 1: Triggering Transformations
Data is extracted from source systems and ingested to RAW. Once the data is ingested, we trigger Transformations so that the data is processed and immediately available for consumption.
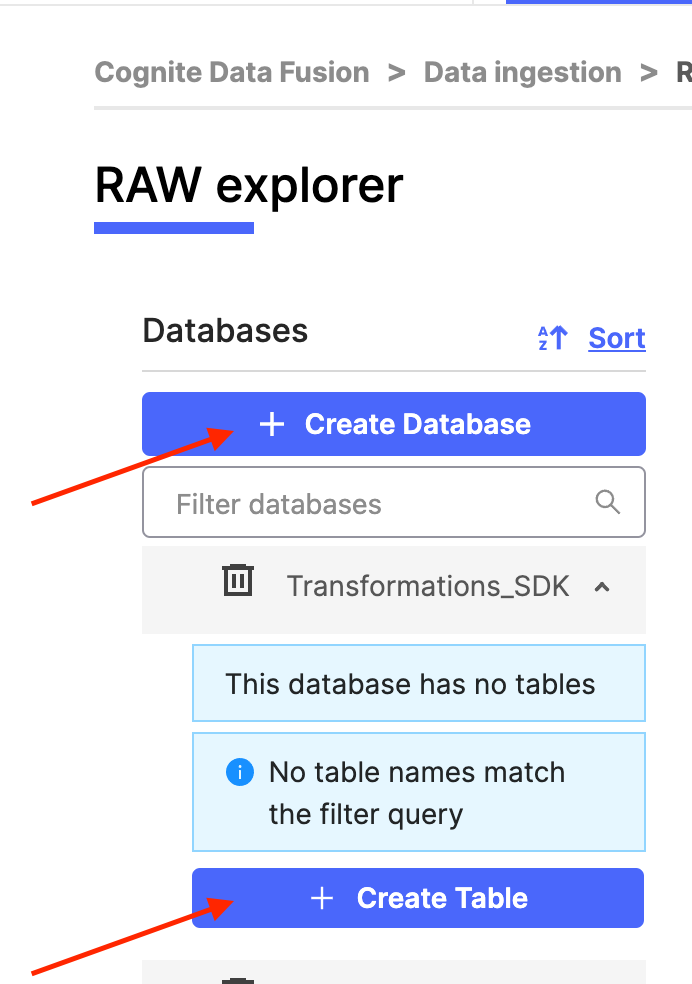
Step 1 - Create RAW Tables
Log in to your project in Cognite Data Fusion and click on "Browse staged data".

Create a Database "Transformations_SDK" and create a table "Asset_Hierarchy"
Step 2 - Uploading data to RAW using Postgres Gateway
2a. Upload the asset-hierarchy.csv file to azure blob storage

2b. If you have not used Postgres Gateway, follow the Postgres Gateway documentation for setup. Next, create a RAW foreign table called "asset_hierarchy" by following this documentation. I have attached below the screenshot of how the columns in your RAW foreign table should look.
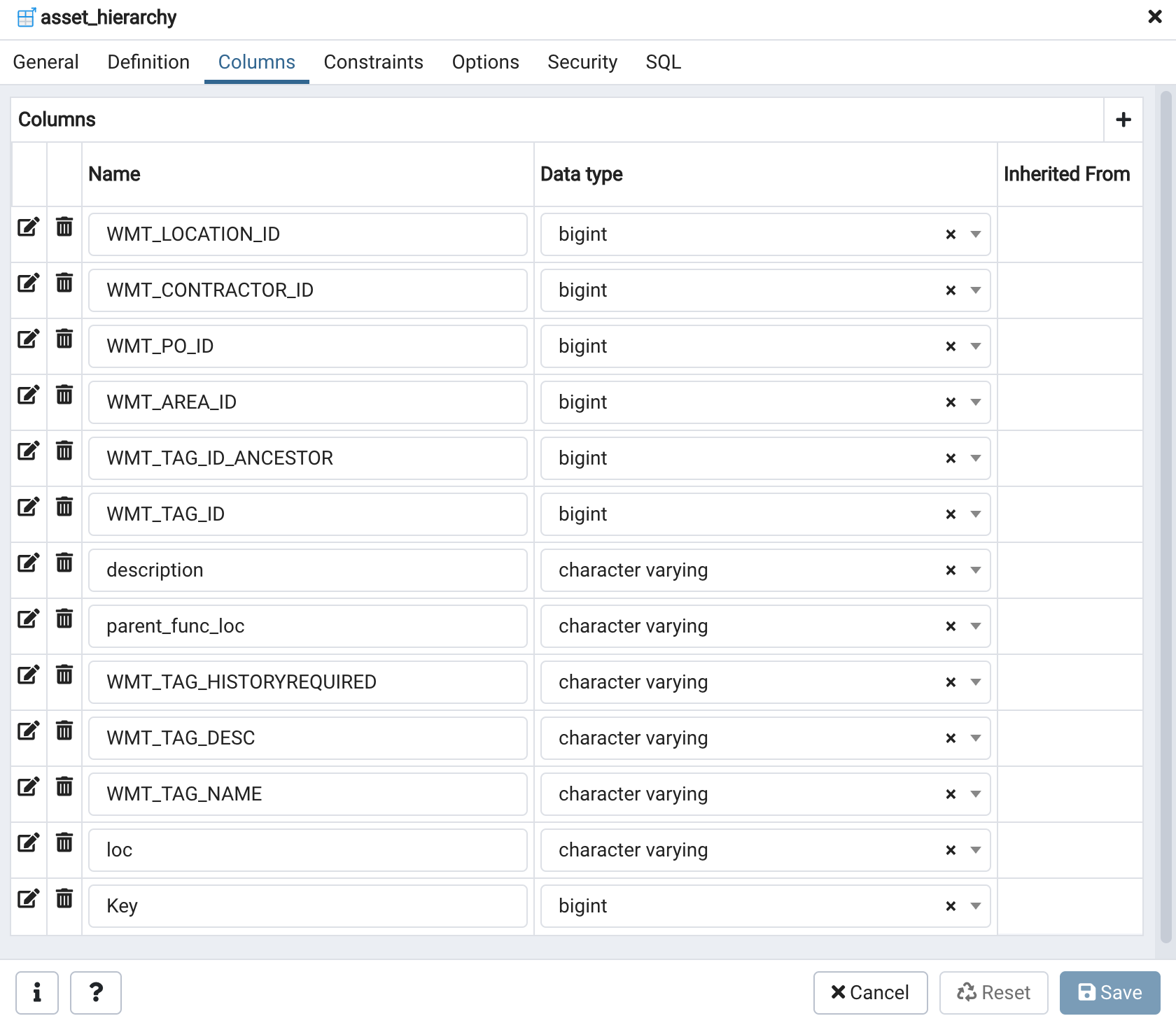
SQL for creating your RAW foreign table (in case you don’t want to create it manually):
CREATE FOREIGN TABLE public.asset_hierarchy(
description character varying NULL,
parent_func_loc character varying NULL,
"WMT_LOCATION_ID" bigint NULL,
"WMT_TAG_HISTORYREQUIRED" character varying NULL,
"WMT_TAG_DESC" character varying NULL,
"WMT_TAG_NAME" character varying NULL,
"WMT_CONTRACTOR_ID" bigint NULL,
"WMT_PO_ID" bigint NULL,
"WMT_AREA_ID" bigint NULL,
"WMT_TAG_ID_ANCESTOR" bigint NULL,
loc character varying NULL,
"WMT_TAG_ID" bigint NULL,
"Key" bigint NULL
)
SERVER raw_server
OPTIONS (database 'Transformations_SDK', table 'Asset-Hierarchy', primary_key 'Key');
ALTER FOREIGN TABLE public.asset_hierarchy
OWNER TO <USERNAME>;2c.Create a simple copy pipeline to ingest the “asset-hierarchy.csv” data from Azure blob storage to the "asset_hierarchy" RAW foreign table you just created. Follow this documentation to create your copy pipeline in Azure Data Factory.
Step 3 - Create new SQL Transformations
Create a new transformation in Cognite Data Fusion using the Python SDK. Download the SDK - pip install cognite-sdk-experimental==0.60.22
from cognite.experimental import CogniteClient
from cognite.experimental.data_classes import Transformation, TransformationDestination, OidcCredentials
c = CogniteClient(
base_url="<base_url>",
client_name="<client_name>",
token_client_id="<token_client_id>",
token_client_secret="<token_client_secret>",
token_url="<token_url>",
token_scopes= "<token_scopes>"],
project="<project_name>",
)
transformations = s
Transformation(
name="SAP asset hierarchy",
external_id = "SAP asset hierarchy",
source_oidc_credentials = OidcCredentials(
base_url="<base_url>",
client_name="<client_name>",
client_id="<token_client_id>",
client_secret="<token_client_secret>",
token_url="<token_url>",
scopes= "<token_scopes>"],
cdf_project_name="<project_name>",
),
destination_oidc_credentials=OidcCredentials(
base_url="<base_url>",
client_name="<client_name>",
client_id="<token_client_id>",
client_secret="<token_client_secret>",
token_url="<token_url>",
scopes= "<token_scopes>"],
cdf_project_name="<project_name>",
),
destination=TransformationDestination.raw(database= "Transformations_SDK", table = "Asset-Hierarchy"),
query = "SELECT concat('CogniteHub', loc) as externalId, IF(parent_func_loc='', '',concat('CogniteHub:',parent_func_loc)) AS parentExternalId,CAST(lastUpdatedTime AS STRING) AS name,to_metadata(*) AS metadata,description AS description FROM `Transformations_SDK`.`Asset-Hierarchy`"
)
]
res = c.transformations.create(transformations)You should now be able to see the "SAP asset hierarchy" transformation created in Cognite Data Fusion.
SELECT
concat('CogniteHub', loc) as externalId,
IF(parent_func_loc='', '',concat('CogniteHub:',parent_func_loc)) AS parentExternalId,CAST(lastUpdatedTime AS STRING) AS name,to_metadata(*) AS metadata,description AS description
FROM `Transformations_SDK`.`Asset-Hierarchy`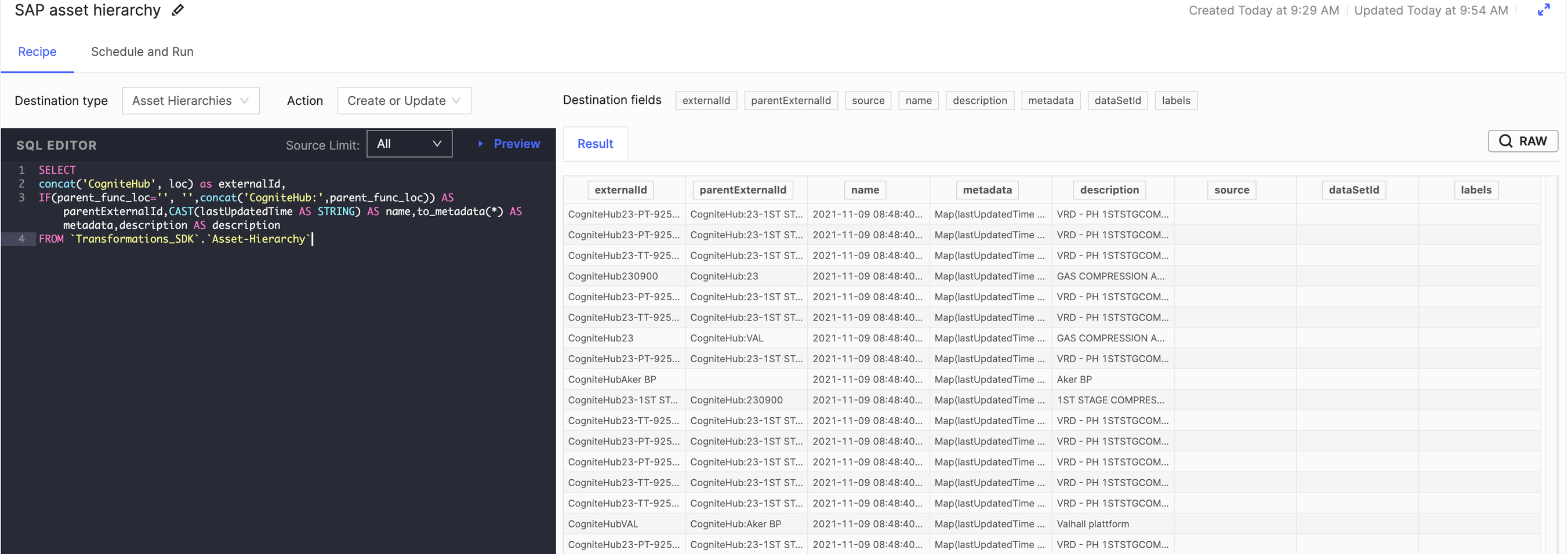
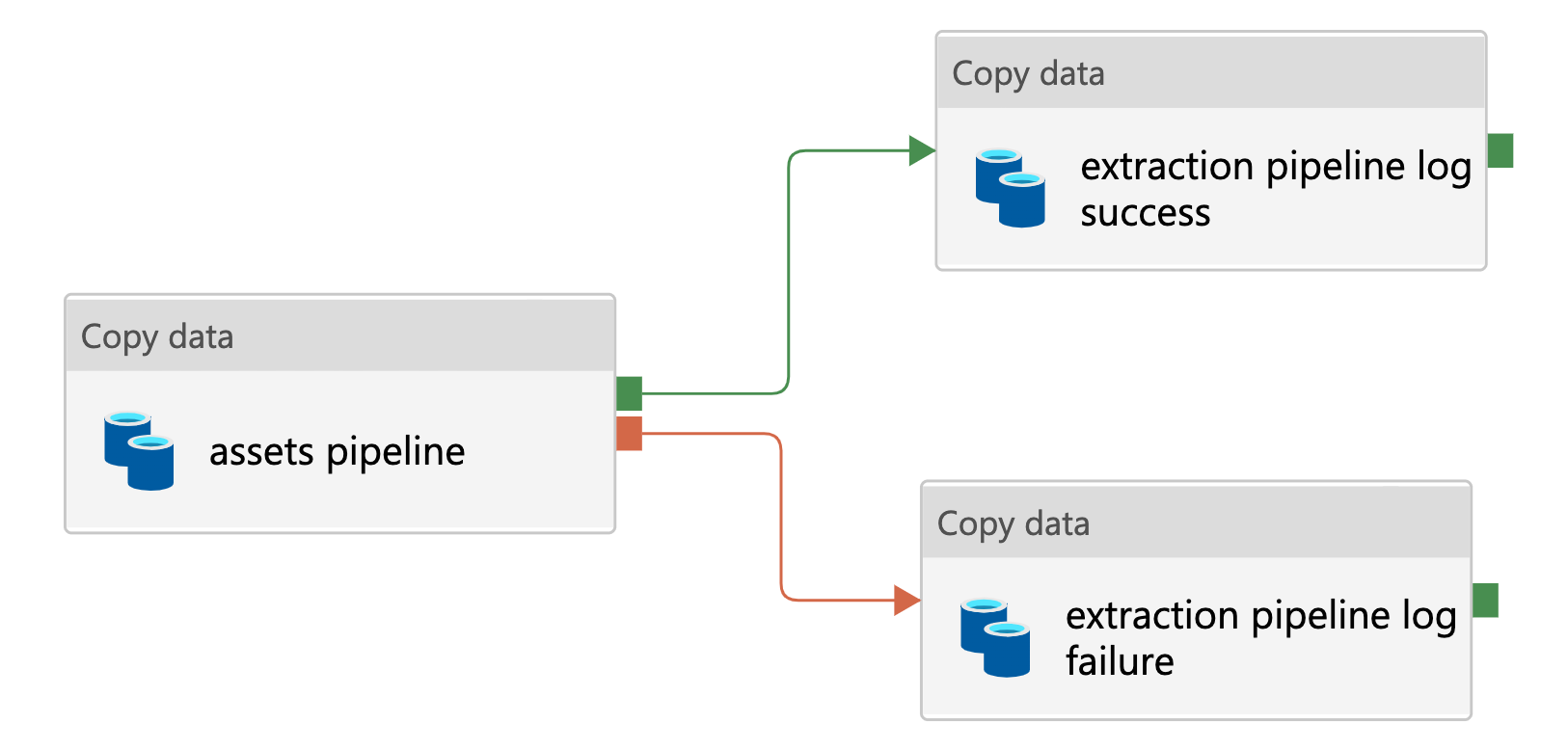
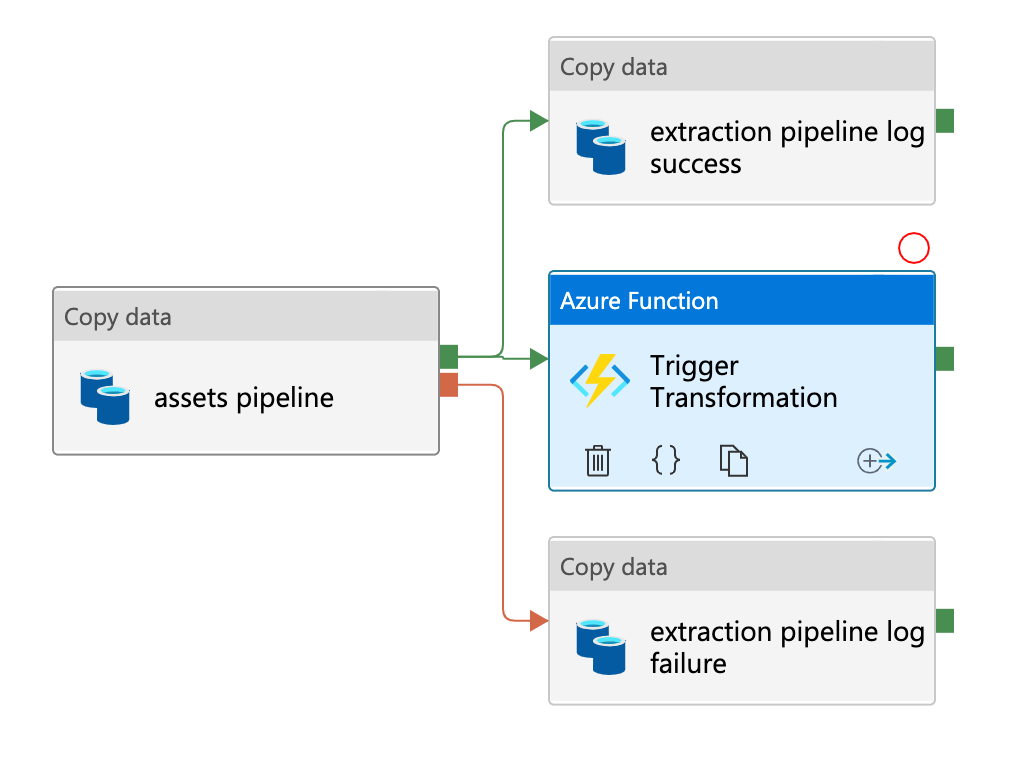
Step 4 - Trigger the transformation from Azure Data Factory
Trigger the SQL Transformation right after the data is ingested to RAW by Azure Data Factory.
requirements.txt for Azure functions
cognite-sdk-experimental==0.60.22
numpy==1.21.0; python_full_version >= "3.7.1" and python_version >= "3.7"
oauthlib==3.1.1; python_version >= "3.6" and python_full_version < "3.0.0" or python_full_version >= "3.4.0" and python_version >= "3.6"
pandas==1.3.0; python_full_version >= "3.7.1" and python_version >= "3.5" and python_full_version < "4.0.0"
openpyxl==3.0.9;python_full_version >= "3.7.1" and python_version >= "3.5" and python_full_version < "4.0.0Azure Functions
import logging
from cognite.experimental import CogniteClient
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
c = CogniteClient(
base_url="<base_url>",
client_name="<client_name>",
token_client_id="<token_client_id>",
token_client_secret="<token_client_secret>",
token_url="<token_url>",
token_scopes= "<token_scopes>"],
project="<project_name>",
)
transformation_job = c.transformations.run(transformation_external_id= "OID_Asset_Hierarchy", wait= True)
if (transformation_job.status == "Completed"):
return func.HttpResponse(f"All success")
else:
return func.HttpResponse(
"OID_Datapoints Failed",
status_code=400
)
Azure Data Factory successfully triggered the SQL Transformations once the data is uploaded to RAW. You can do the same with the extractors that you build using the python extractor utils ( please use cognite-sdk-experimental==0.60.22 ). Once the data is ingested to RAW by the extractor it can subsequently trigger the SQL Transformation.
Use Case 2: Orchestrating Transformations
Using the “wait= True” in transformations.run, Transformations can be run in sequence i.e. after successful completion of a transformation job the next transformation job is triggered.
Step 1 - Create RAW Tables
In the "Transformations_SDK" database:
-
create a table "OID_Asset_Hierarchy" and upload OID-Asset-hirerachy.csv
-
create a table "OID_Timeseries" and upload OID-Timeseries.csv
-
create a table "OID_Datapoints" and upload OID-Datapoints.csv
Step 2 - Create new SQL Transformations
Using the Transformations python SDK create Transformations for "OID_Asset_Hierarchy", "OID_Timeseries" and "OID_Datapoints"
from cognite.experimental import CogniteClient
from cognite.experimental.data_classes import Transformation, TransformationDestination, OidcCredentials
c = CogniteClient(
base_url="<base_url>",
client_name="<client_name>",
token_client_id="<token_client_id>",
token_client_secret="<token_client_secret>",
token_url="<token_url>",
token_scopes= "<token_scopes>"],
project="<project_name>",
)
transformations = b
Transformation(
name="OID_Asset_Hierarchy",
external_id = "OID_Asset_Hierarchy",
source_oidc_credentials = OidcCredentials(
base_url="<base_url>",
client_name="<client_name>",
client_id="<token_client_id>",
client_secret="<token_client_secret>",
token_url="<token_url>",
scopes= "<token_scopes>"],
cdf_project_name="<project_name>",
),
destination_oidc_credentials=OidcCredentials(
base_url="<base_url>",
client_name="<client_name>",
client_id="<token_client_id>",
client_secret="<token_client_secret>",
token_url="<token_url>",
scopes= "<token_scopes>"],
cdf_project_name="<project_name>",
),
destination=TransformationDestination.assets(),
query = "select externalId, parentExternalId, 'open_industrial_data' as source, name, description,map(\"source_internal_id\", get_json_object(metadata, '$._replicatedInternalId'),\"datadump\", \"1\") as metadata,null as dataSetId, null as labels,bigint(id),bigint(parentId)from Transformations_SDK.OID_Asset_Hierarchy where is_new(\"datadump\", lastUpdatedTime)"
),
Transformation(
name="OID_Timeseries",
external_id = "OID_Timeseries",
source_oidc_credentials = OidcCredentials(
base_url="<base_url>",
client_name="<client_name>",
client_id="<token_client_id>",
client_secret="<token_client_secret>",
token_url="<token_url>",
scopes= "<token_scopes>"],
cdf_project_name="<project_name>",
),
destination_oidc_credentials=OidcCredentials(
base_url="<base_url>",
client_name="<client_name>",
client_id="<token_client_id>",
client_secret="<token_client_secret>",
token_url="<token_url>",
scopes= "<token_scopes>"],
cdf_project_name="<project_name>",
),
destination=TransformationDestination.timeseries(),
query = "select null as id,ts.name, ts.externalId,to_metadata(ts.metadata) as metadata,ts.unit,a.id as assetId,ts.description,null as securityCategories,false as isStep,false as isString,null as dataSetId from Transformations_SDK.OID_Timeseries ts left join _cdf.assets a on ts.externalId_asset == a.externalId"
),
Transformation(
name="OID_Datapoints",
external_id = "OID_Datapoints",
source_oidc_credentials = OidcCredentials(
base_url="<base_url>",
client_name="<client_name>",
client_id="<token_client_id>",
client_secret="<token_client_secret>",
token_url="<token_url>",
scopes= "<token_scopes>"],
cdf_project_name="<project_name>",
),
destination_oidc_credentials=OidcCredentials(
base_url="<base_url>",
client_name="<client_name>",
client_id="<token_client_id>",
client_secret="<token_client_secret>",
token_url="<token_url>",
scopes= "<token_scopes>"],
cdf_project_name="<project_name>",
),
destination=TransformationDestination.datapoints(),
query = "select externalId,to_timestamp(timestamp) as timestamp,double(value) as value from Transformations_SDK.OID_Datapoints"
)
]
res = c.transformations.create(transformations)Step 3 - Orchestrate Transformations in sequence
requirements.txt for Azure functions
azure-functions
cognite-sdk-experimental==0.60.22
numpy==1.21.0; python_full_version >= "3.7.1" and python_version >= "3.7"
oauthlib==3.1.1; python_version >= "3.6" and python_full_version < "3.0.0" or python_full_version >= "3.4.0" and python_version >= "3.6"
pandas==1.3.0; python_full_version >= "3.7.1" and python_version >= "3.5" and python_full_version < "4.0.0"
openpyxl==3.0.9;python_full_version >= "3.7.1" and python_version >= "3.5" and python_full_version < "4.0.0Azure Functions
import logging
from cognite.experimental import CogniteClient
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
c = CogniteClient(
base_url="<base_url>",
client_name="<client_name>",
token_client_id="<token_client_id>",
token_client_secret="<token_client_secret>",
token_url="<token_url>",
token_scopes= "<token_scopes>"],
project="<project_name>",
)
transformation_job_1 = c.transformations.run(transformation_external_id= "OID_Asset_Hierarchy", wait= True)
if ( transformation_job_1.status == "Completed"):
transformation_job_2 = c.transformations.run(transformation_external_id= "OID_Timeseries", wait= True)
else :
logging.error("OID_Asset_Hierarchy Failed")
if ( transformation_job_1.status == "Completed" and transformation_job_2.status == "Completed"):
transformation_job_3 = c.transformations.run(transformation_external_id= "OID_Datapoints", wait= True)
print("All done")
else:
print("OID_Timeseries Failed")
if (transformation_job_3.status == "Completed"):
return func.HttpResponse(f"All success")
else:
return func.HttpResponse(
"OID_Datapoints Failed",
status_code=400
)Using the Transformations python SDK you have triggered Transformations in sequence. You can Schedule your Azure functions in the “App service plan”.
Unverified - If your Transformations take longer you can increase the duration of your Azure function by updating host.json in App service plan or you can try orchestrating using Azure durable functions.
Congratulations if you made it up here! ![]()
Now that you played around with the SDK, it's feedback time down in the comments! We'd love to know how you are using it in your use cases.
") Cognite functions is similar to Az functions i.e. for a long running Transformations the lifetime of a Cognite function is short. A patch solution for now would be to run the python script on a VM.
Cognite functions is similar to Az functions i.e. for a long running Transformations the lifetime of a Cognite function is short. A patch solution for now would be to run the python script on a VM.