Hi, please read the documentation found here: https://docs.cognite.com/cdf/integration/guides/extraction/opc_ua/opc_ua_configuration. History is read from “start-time” to “end-time”. Your current configuration means that history will be read from time 0 (the beginning of server history) to 30 days ago.
Also, max-read-length does not do what you think it does. It is a workaround for specific server issues. If you do not need it, I highly recommend turning it off.
Hi Einar,
Thank you so much for quick reply.
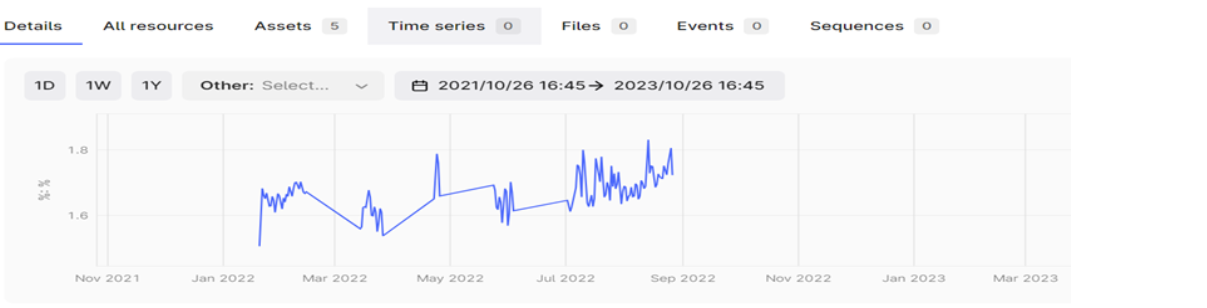
It is so helpful I tried this configuration of start-time :30d-ago and endtime:0 and max-read-length:0.I can history starting from a month ago. Please find the screen shot.
I would appreciate, if you could explain what the significance of max-read-length as documentation doesn’t have this parameter. It is present in the config.example.yml of OPC UA Extractor of version 2.21.1
Is max-read-length similar to max-history-length?
Regards,
Sandhya
max-read-length does appear to be missing from the docs, that’s an oversight. The docs on end-time are also no longer accurate, we will address this.
It is a workaround for servers that do not support ContinuationPoints, it limits the maximum length of each read request to the server. So if you request a year of history, and set max-read-length to 30 days, it will take at least 12 requests to the server to find all the data in that range, even if there are no data points in that timeseries at all.
There is no reason at all to use it on servers that support ContinuationPoints for history, and setting it to 30 days is likely to not work that well even if you had such a server.
Hi Einar,
I can see history ,backfilling ,front filling with metadata working fine for single node.
when I tried similar type of configuration for entire node hierarchy (provided the namespace-uri, node-id) it is not showing datapoints in CDF and only empty time series is created. Even tried leaving the node as empty as it takes entire node hierarchy by default it is just showing the empty time series.
On total I have 5500 tags to be uploaded in CDF. Just wanted to know if their is any restriction in no.of tags that can be uploaded with datapoints in CDF.
Please find the configuration for entire node below.
root-node:
# Full name of the namespace of the root node.
namespace-uri: x:XXXOpcUaServer
# Id of the root node, on the form "i=123" or "s=stringid" etc.
node-id: "s=/ObjectsFolder/xxxServer"
Let me know if any other configuration needs to be done.
Regards,
Sandhya