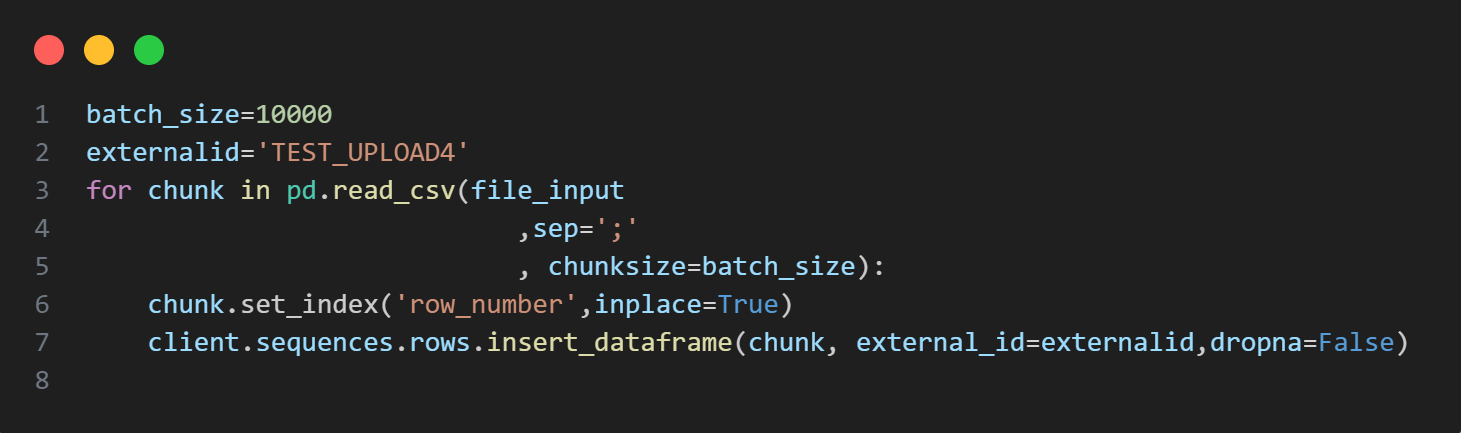
Hi @Karina Saylema
Your code seems correct.
Could you make sure that “row_number” is unique?
If you try the code bellow, are you encountering the same issue?
batch_size = 10000
external_id = 'TEST_UPLOAD4'
start_row = 0 # Initialize a starting row number
for chunk in pd.read_csv(file_input, sep=';', chunksize=batch_size):
chunk.drop(columns=o"row_number"], inplace=True)
chunk.index = range(start_row, start_row + len(chunk))
client.sequences.data.insert_dataframe(chunk, external_id=external_id, dropna=False)
start_row += batch_size
@Karina Saylema
I think what’s happening is that chunk.set_index() is resetting the index for each chunk which is resulting in the sequence rows being overwritten because the row indexes are the same as the prior batch.
I’m not a pandas expert, but something like explicitly setting the index based on your batch size might be what you are looking for: https://pandas.pydata.org/docs/reference/api/pandas.RangeIndex.html
Hope this helps,
Jason
Thanks @Andrian Gasper, @Jason Dressel for your help
@Karina Saylema You can mark this questions as answered, if you believe it is. :)