

 Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


Hello Cognite Community,
I'm currently in the process of deepening my understanding of the Cognite Python SDK, and I've encountered some hurdles that I believe this community could help me overcome. I'm working with a time-series dataset and aiming to use it to make machine learning-based predictions. To facilitate a more comprehensive response, I've provided a snapshot of the data I'm working with and detailed my queries below.
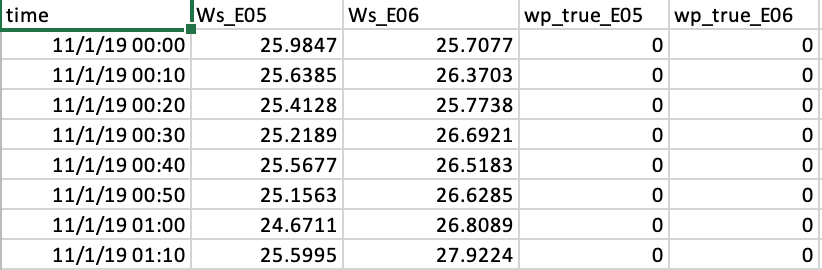
Dataset Structure: The data comprises 5 columns: time, ws_E05, ws_E06, wp_true_E05, wp_true_E06. The 'ws_E05' represents the true wind speed at location E05, and 'wp_true_E06' signifies the true wind power at location E06.
Query 1: I plan to utilize this dataset to forecast the subsequent 10 minutes using Linear Regression in the Python SDK on Cognite. Could you advise me if the present state of this time-series data is sufficient to get started, or are there certain modifications or preprocessing steps I should consider? I'm also interested in visualizing this data using the Python SDK, if possible.
Query 2: Given my data structure, would it be beneficial to use Cognite Data Fusion (CDF) to create a separate dataframe with 'E05' and 'E06' as assets? Should I incorporate this time-series data into CDF before utilizing the Python SDK?
Query 3: I'm exploring the concept of creating a digital twin for importing data, running my algorithms, and exporting data for future predictions. Considering this, why would incorporating this data into CDF or even using Cognite be advantageous compared to purely using Python? In other words, how exactly can CDF or the Cognite Python SDK enhance my project's efficiency or effectiveness?
Please note that I've recently embarked on the Python SDK course, while having already completed the CDF Fundamentals course. However, I'm still uncertain about how to apply these learnings to my current project.
Your guidance on these matters would be immensely beneficial. I apologize if some questions seem elementary; I'm still in the early stages of mastering these technologies. I'm eagerly awaiting any advice or insights that would help me navigate these issues more effectively.
Thank you for your time and consideration.
Best Regards,
Vishnu Iyengar
Best answer by HaydenH
View original