Thanks for this great in depth explanation if your idea. The problem you describe is precisely why we are creating the data modeling capabilities with schema service. To be able to have a contract that an application can trust, and move the customization from the application layer to earlier in the data pipeline.
Your idea here with an Application A contract that is being used by multiple CDF projects is great and is something we are working towards now.
I’ll keep you posted on updates in this area ") Again, thanks a lot!
Again, thanks a lot!
Really great update, @David Liu! I am super impressed with the work that your team has been doing.
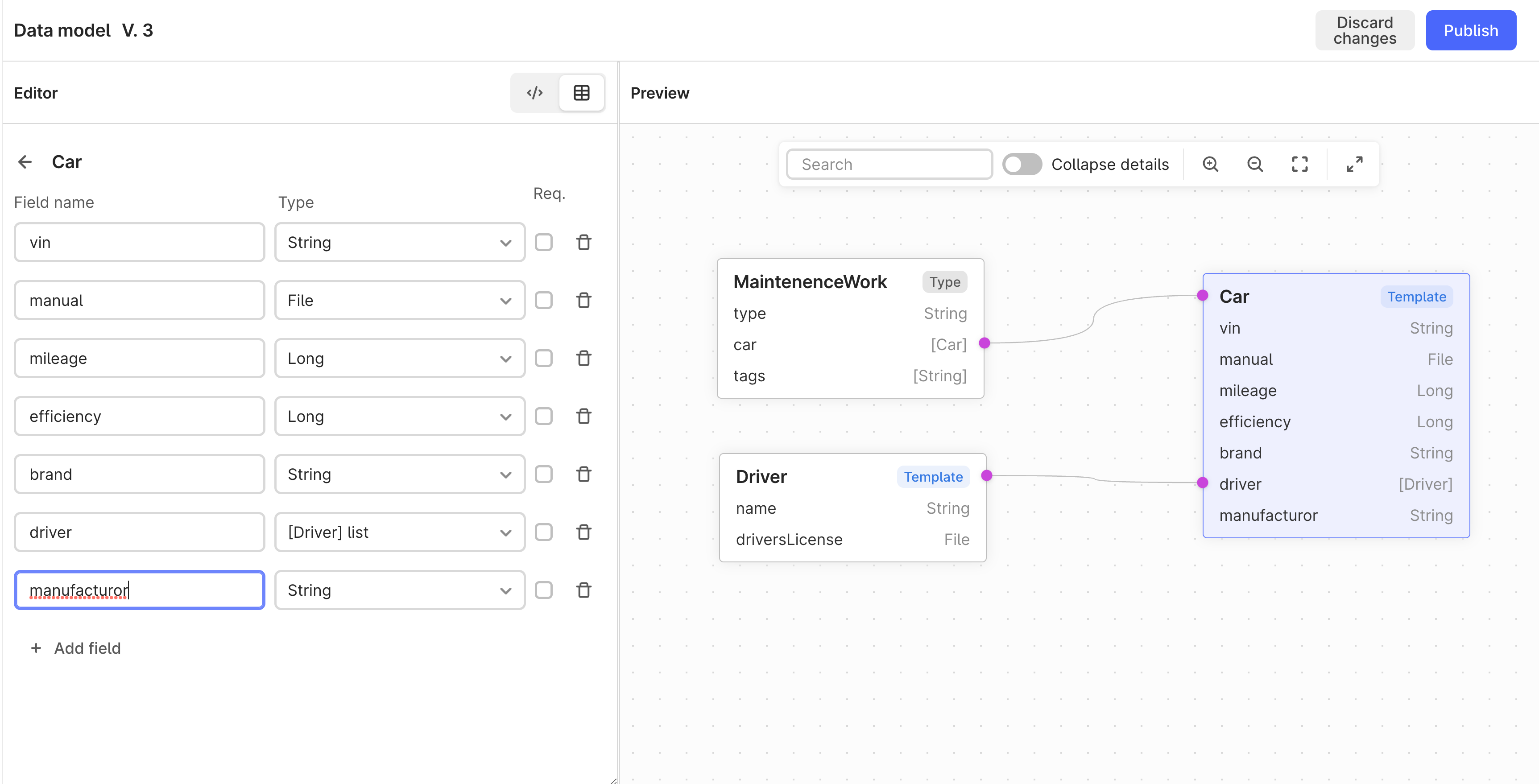
One thing I am still a bit confused about is how the Template functionality stays in sync with existing String, Long, and Double fields that are in the metadata of existing CDF data model types like assets or events. The impedance mismatch I am seeing is that while CDF pulls data together to be able to query in one place, the shape of the data can vary wildly across different CDF projects or sometimes within the same CDF project when it comes to the metadata fields. Much like how the RAW data can be in any shape, the metadata fields on the CDF data model cannot be expected to fulfill any type of contract that an application layer needs as key names are not standardized (Ex: variation in casing, naming. units, and level of nesting of keys: OrificePlateDiameter vs orifice_plate_diameter vs orifice_plate_diameter_inches vs orifice_plate_diameter_centimeters).
That is why I am very hopeful about what is to come with the “Schema Service” that will be replacing Templates.
I would like application vendors to be able to publish their own data model specification/contract to a library with in CDF. Then users of CDF projects could select which application data models that they would like to map to with their unique set of data unfurled from the metadata fields. This would hopefully be a one-time configuration at CDF project setup, not something that takes continual maintenance and manually associated with entities from the CDF data model.
As an example, Application A may specify the following data requirements (simplified):
type OrificeMeter @template {
id: String
orificePlateOuterDiameterIn: Long
orificePlateInnerDiameterIn: Long
isTapUpstream: Bool
differentialPressureKpa: TimeSeries
pressureKpa: TimeSeries
temperatureCelsius: TimeSeries
}
User of CDF Project B says, I’d really like to use Application A. Let me map my CDF Data Model to this contract so that I can start using Application A.
Project B Asset entities have properties which map to Application A contract:
OrificeMeter => CDF Asset
- id = Asset.Id
- orificePlateOuterDiameterIn = Asset.Metadata.OrificePlate.OuterDiameterCm/2.54
- orificePlateOuterDiameterIn = Asset.Metadata.OrificePlate.InnerDiameterCm/2.54
- isTapUpstream = Asset.Metadata.TapLocation == “Upstream”
- differentialPressureKpa = SyntheticTimeSeries(convert Psi to Kpa) with some selection criteria
WHERE Asset.Metadata.AssetType == “orifice_meter”
After this initial mapping is setup Application A can read it’s native data model directly from CDF Project B. All new OrificeMeters that appear are available as they fit the “WHERE” clause.
Next, CDF Project C user says… I heard Project B is using Application A. We should use it too… but we prefer to have single letter abbreviations for all our properties in our CDF data model metadata so less bits have to be transmitted on an HTTP request.
Project C Asset entities have properties which map to Application A contract:
OrificeMeter => CDF Asset
- id = Asset.Id
- orificePlateOuterDiameterIn = Asset.Metadata.opOdIn
- orificePlateOuterDiameterIn = Asset.Metadata.opIdIn
- isTapUpstream = Asset.Metadata.tl == 1
- differentialPressureKpa = SyntheticTimeSeries(convert Psi to Kpa) with some more obscure selection criteria
WHERE Asset.Metadata.mt == 27 (of course 27 stands for orifice meter. Project C users think this is obvious.)
Now, even though Project B and Project C both have unique data model shapes in their CDF instances, they are both able to utilize Application A. All it took was some initial mapping setup.
That is my vision of what is possible. I’m really hopeful of what’s to come. Thanks!