Dashboard Query: Top 10 from Aggregate Sum of ~1000 Tim Series
I need to add a dashboard query that is simple to write with SQL but seems to be complex to write with the CDF API.
Input parameters:
start and end timestamp range
List of time series to query
Query steps:
For each time series in the list, sum all values that are in the user provided range
Order time series by the sum
Return metadata from the top 10 of this ordered list
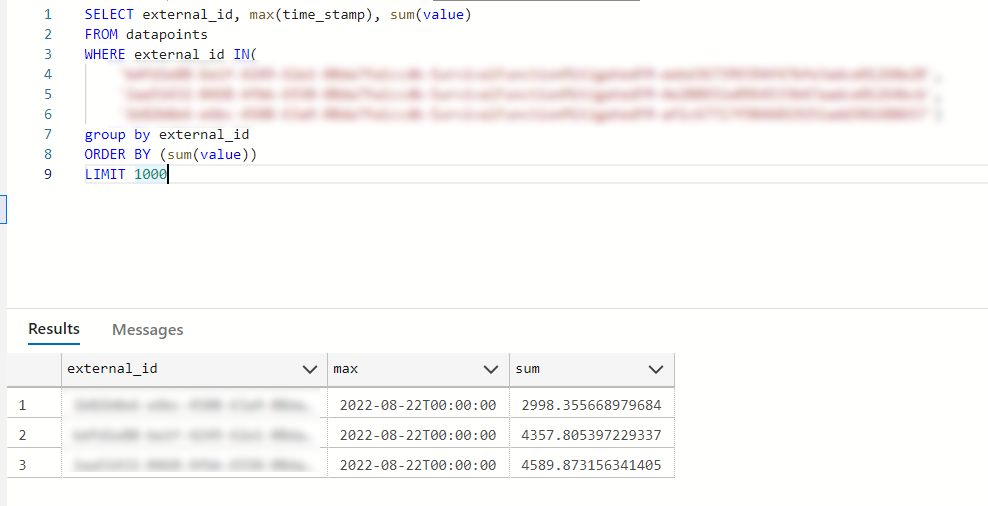
Maybe something equivalent to this:
-- Likely SLOW in a SQL DB with many datapoints -- This is a conceptual example, so simplifying by combining Time Series and -- Data Points to single entity. Select TOP 10 TimeSeries.Name, SUM(TimeSeries.Value) FROM TimeSeries WHERE TimeSeries.Id IN (@ListOfTimeSeries) AND TimeSeries.Timestamp >= @StartTimestamp AND TimeSeries.Timestamp < @EndTimestamp GROUP BY TimeSeries.Id, TimeSeries.Name ORDER BY SUM(TimeSeries.Value)
What’s the simplest way to get to this data with the tools provided to a software developer interacting with CDF?
Page 1 / 1
Clarification, this is being developed in a SaaS application running in Azure not within Power BI.
This SQL seems to run perfectly fine on the PostgreSQL gateway from Azure Data Studio on my local dev machine against my CDF project.
The reason why we don’t explicitly support querying using the postgres gateway is that it behaves somewhat unpredictably. Normally, when writing a SQL query you can assume that the database you are querying will optimize and improve the query. The postgres gateway accesses CDF through limited APIs, and can only optimize a small subset of queries.
This query is actually one of those I think it will optimize. It will fetch every datapoint for the given time series, between the given time stamps, then postgres will calculate the aggregates. If there are millions of datapoints, it will take a long time. If you changed the condition slightly, adding an “OR”, for example, the query would either fail or fetch every single datapoint in each time series.
It could in theory be translated better, but I’m not entirely sure whether aggregate pushdown is possible at all in postgres foreign data wrappers.
All that said. If this works and performs well for you, you are free to use it, we won’t be explicitly disabling the ability to query the gateway any time soon.
As for how you could do this using the API directly, I think I would split it into three queries:
One for latest datapoint
One for first datapoint
One for some reasonable choice of sum aggregates, then you would have to sum the resulting aggregates locally.
Since aggregate granularity means that the start and end points are rounded, the third one might be a little tricky to get right, especially if you are interested in sums between arbitrary time stamps.
@Einar Omang Can you give more detail on this?
Since aggregate granularity means that the start and end points are rounded, the third one might be a little tricky to get right, especially if you are interested in sums between arbitrary time stamps.
If my data is always certain to be daily resolution and I am querying the API or the PostgreSQL gateway for daily resolution, will I hit this issue you are describing?
If my data is always certain to be daily resolution and I am querying the API or the PostgreSQL gateway for daily resolution, will I hit this issue you are describing?
I don’t think so, no. The issue is for example that if you are querying from 7 AM 01/06/2022 to 7 AM 01/07/2022 with daily granularity, the sum would include data all the way from 0:00 on 01/06, and all the way to 0:00 on 02/07. If your start and end points are exactly on 0:00 then it works fine, or you could use hourly aggregates.
It doesn’t seem like you can query aggregates from multiple time series for data points, unfortunately, so if you wanted to do it that way you would have to use the API directly, or create separate tables for each time series:
CREATE FOREIGN TABLE daily_myts ( time_stamp TIMESTAMP, sum FLOAT ) SERVER datapoints_server OPTIONS ( external_id 'my_ts_external_id', granularity '1d' );
All that said, if you only have a few datapoints in your interval, then just running the query you have is no problem at all. This is just if you need this over intervals with lots of datapoints.