Hi,
We use CDF workflow to process the data present in data model. Based on the inputs, we trigger multiple workflow instances to take the advantage of scalability. We observed that, the workflow execution time is increasing after we trigger more workflow instances.
Here is the simple diagram to show how we use workflow:
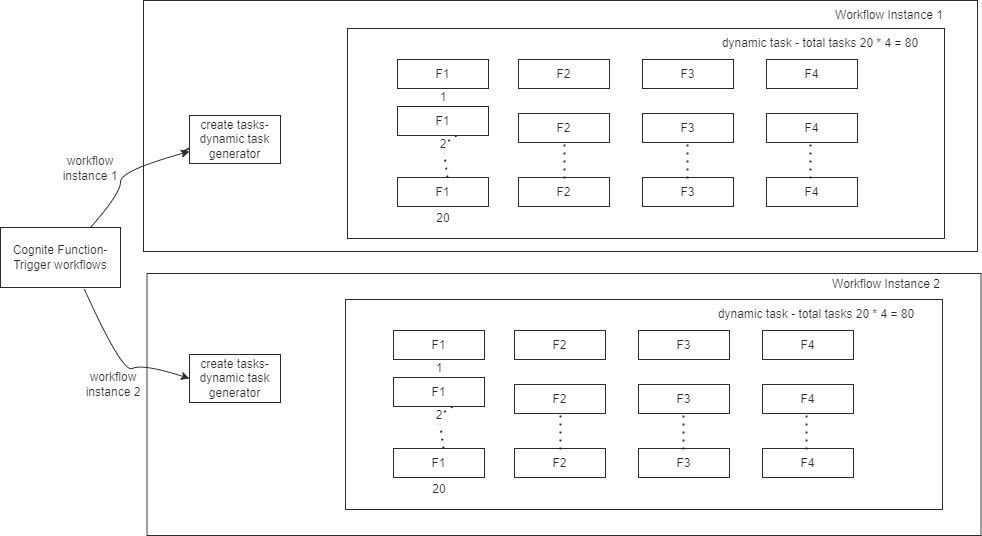
For example:
If we run 1 workflow instance to process 20 wellbores (assume some processing logic divided between F1 to F4) with 20 concurrent tasks, the execution time of that workflow instance is 5 mins.
Now if we want to process more wellbores say 40, we trigger 2 workflow instances , 1st workflow instance to process 20 wellbores and 2nd workflow instance to process other 20 wellbores and we expect the execution time for all workflows to be approximately same but the total time is increasing if we compare with only 1 workflow instance with 20 tasks.
Can you please help me to understand if anything is missing?


