Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support

Hi everyone! 👋
The next major Cognite Data Fusion product release is soon approaching on June 4th. We’re excited to announce lots of new upcoming features across our Industrial Tools and Data Operations capabilities. This post will walk you through selected highlights from the release, including:
These, and much more, can be found in our latest release notes. Check out all the additional features and improvements which will enable your teams to drive even more value from Cognite Data Fusion.
We also recommend watching the June Spotlight video:
These new capabilities will be available to you on June 4th 2024. We would love to hear your feedback here on Cognite Hub over the coming weeks. We also want to thank all our community members for your contributions so far. We're eager to continue this collaborative process with you, seeking your valuable input on both existing and upcoming product features. We encourage you to continue to submit your Product Ideas here in the community, to help us understand how we can continue to evolve Cognite Data Fusion to fit your needs. Let's keep this momentum going!
INDUSTRIAL TOOLS
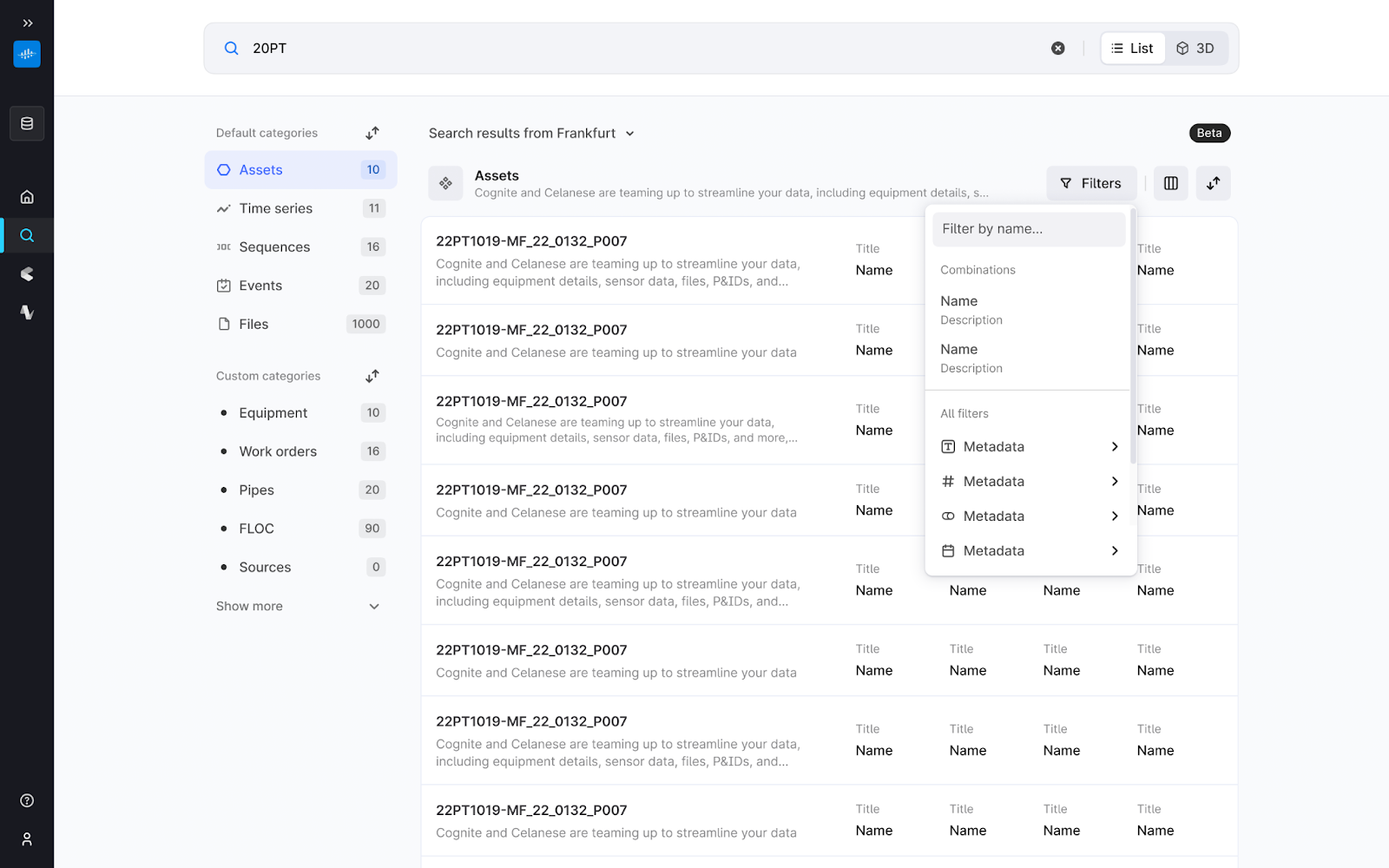
Cognite Search | comprehensive data exploration for industrial users
Official launch of Cognite Search. A streamlined search and data exploration for industrial users. This first major release includes sorting search results by properties, adjusting visible columns in search results, and allowing admins to set default filter combinations for all users. Additionally, the Location (Site) configuration now supports subtree and external ID prefix filtering. These updates simplify data exploration across the portfolio, making it more accessible for industrial users.
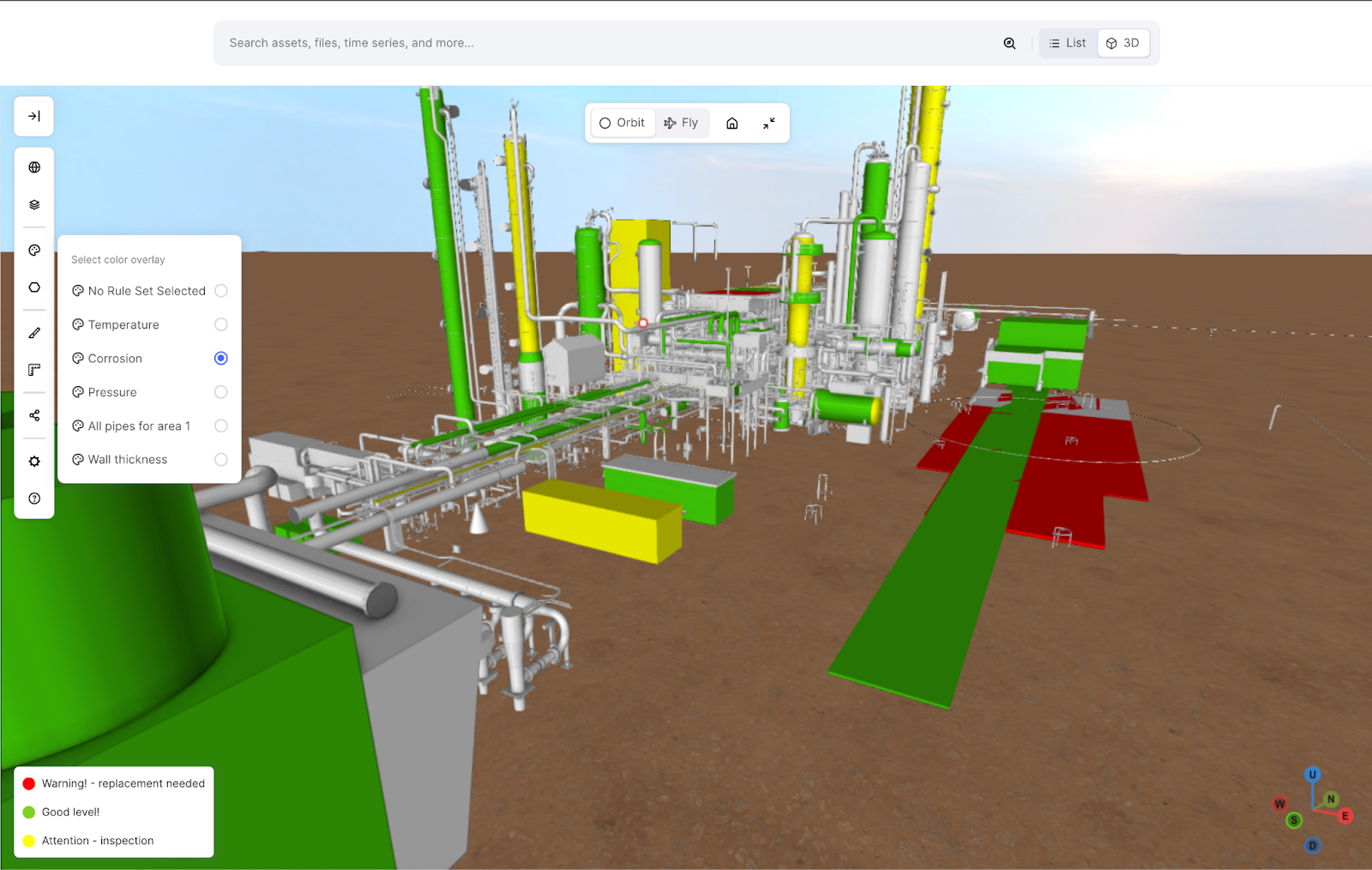
In the 3D search experience, we’ve also released tools for measuring multipoints, areas, and volumes, as well as rules that trigger color changes on contextualized objects when specific criteria are met. These improvements offer better spatial awareness through advanced measurements and real-time visual alerts, significantly boosting operational efficiency and decision-making.
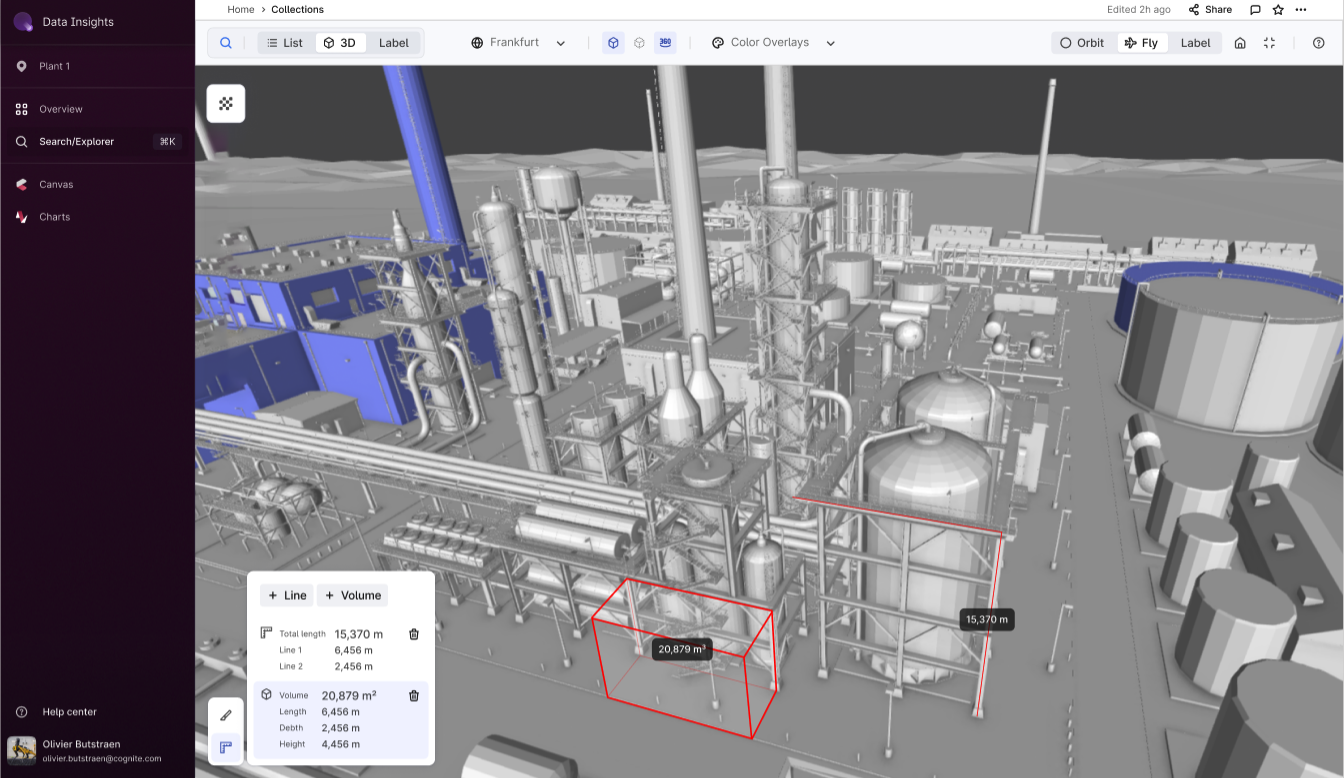
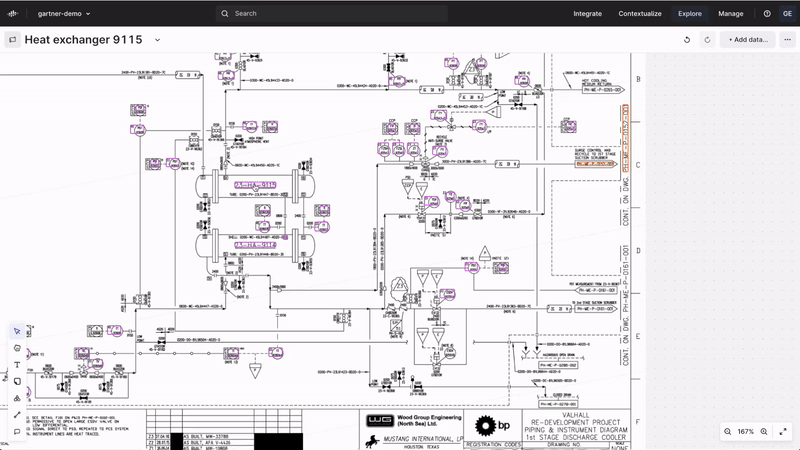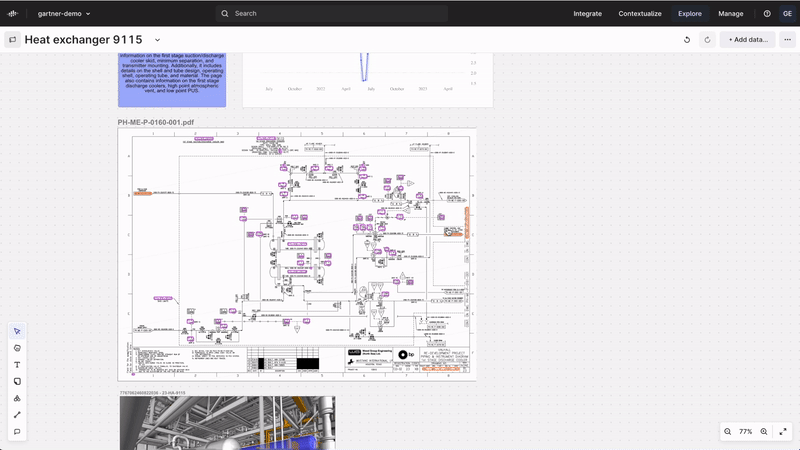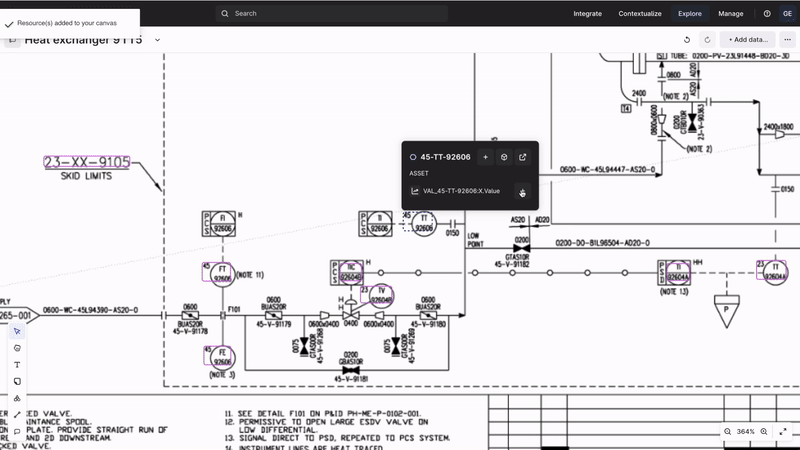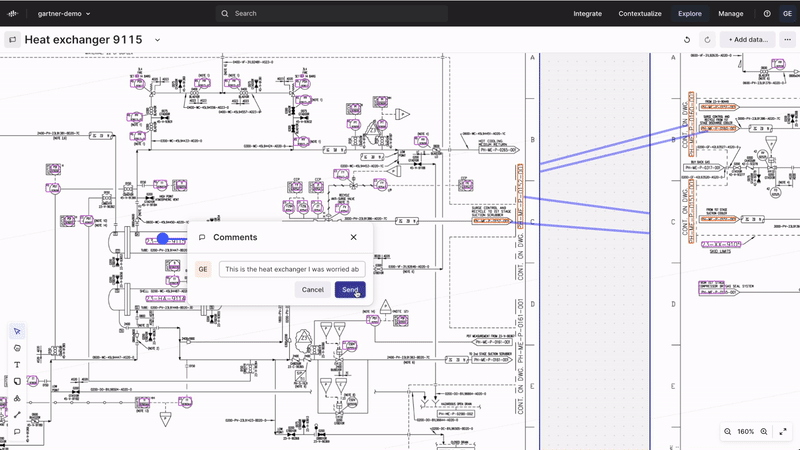
Industrial Canvas | collaborative troubleshooting and analysis
Official launch of Industrial Canvas, a powerful tool designed to streamline collaboration on industrial data, allows users to integrate assets, time series, 3D models, and more into an infinite canvas. It includes markups, shapes, lines, versioning, canvas locking, commenting, and sharing capabilities, all with enhanced performance and interactivity. By enabling direct collaboration on contextual OT, IT, and ET data, Industrial Canvas facilitates quicker, higher-quality decisions and reduces the time spent on data collaboration, allowing more focus on production improvements.
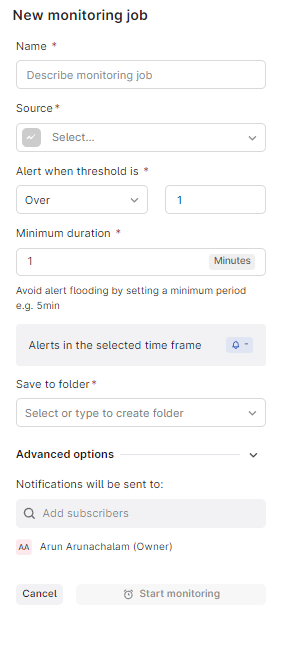
Charts | no-code time series monitoring
Official launch of monitoring in Cognite Charts, replacing traditionally a time-consuming task for automation engineers. Users can now easily create thresholds on time series and set up alerts to get notified when these thresholds are breached. These enhancements reduce the burden of setting up monitoring, allowing anyone to monitor time series data. The alert system ensures proactive investigation when key equipment indicators deviate, improving overall efficiency and responsiveness.
Charts | data quality indicators (beta)
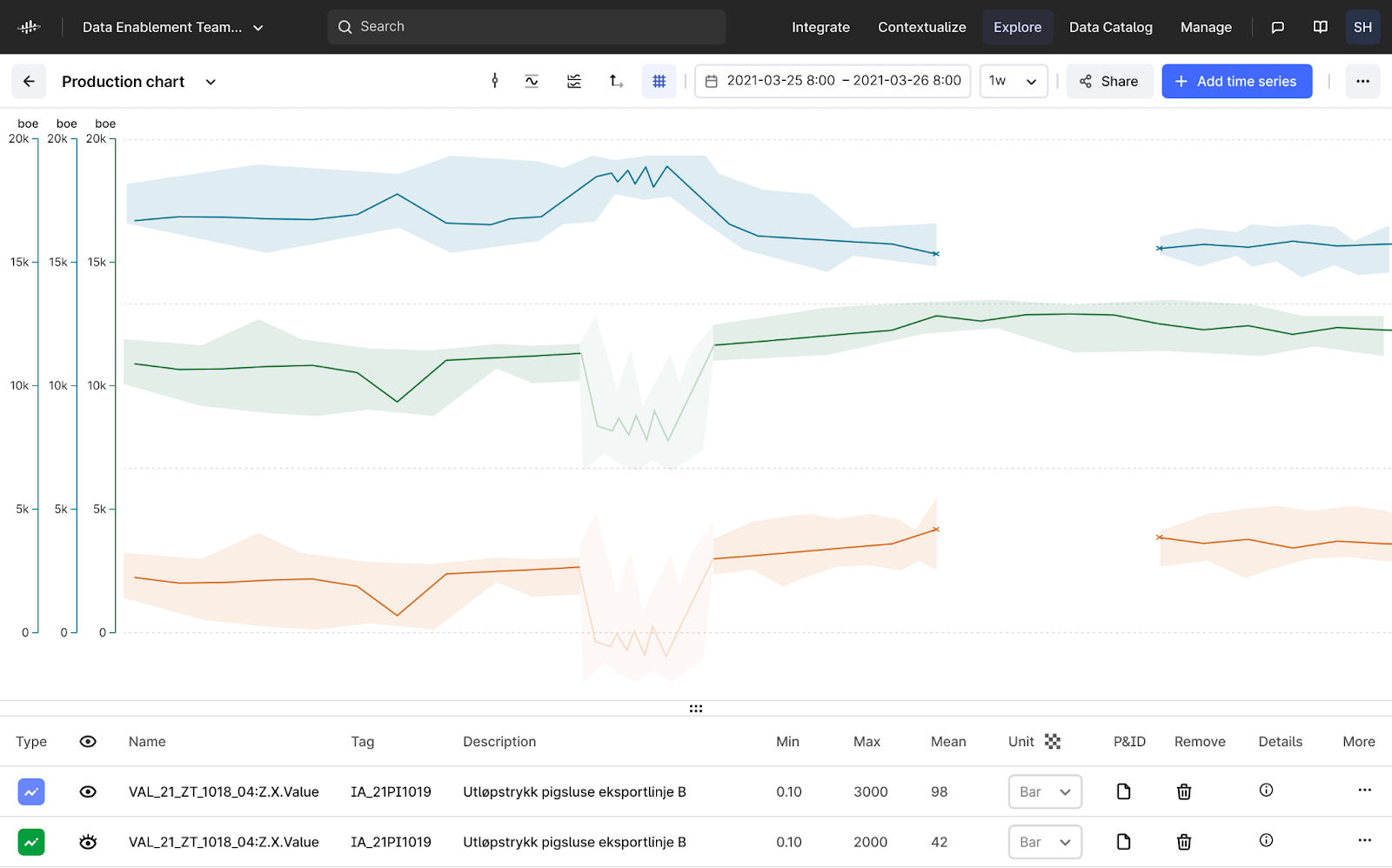
View time series data quality codes in Cognite Charts, such as “Bad” and “Uncertain”, on both raw and aggregated data points. Additionally, the raw data point limit has been increased to 100,000, and there is improved indication of gaps in calculations when dealing with bad or uncertain data. These updates enable users to trust the data they see, enhancing confidence in their decision-making processes and reducing the need to revert to source systems.
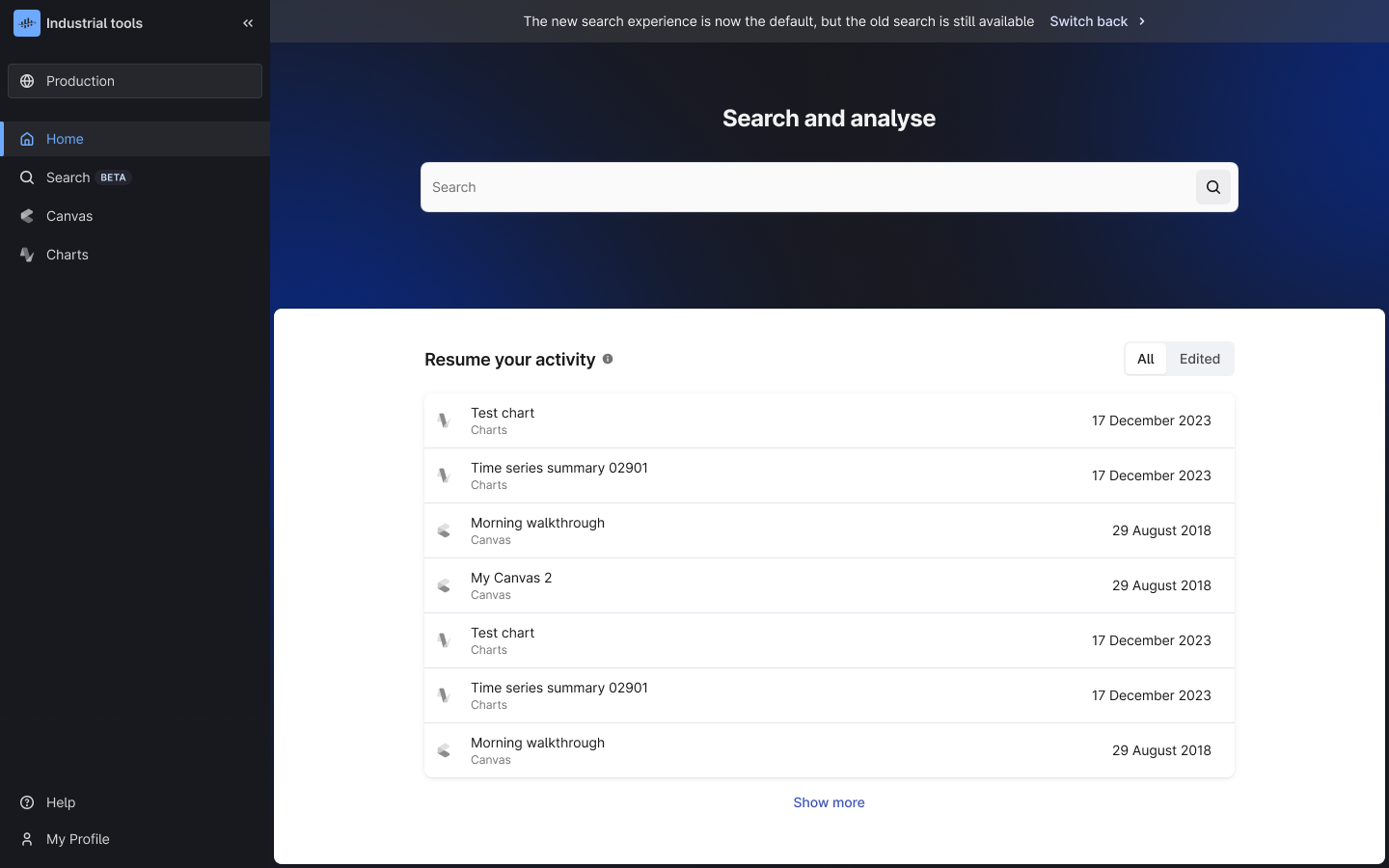
Fusion Landing Page | workspaces
Persona-based workspaces tailored specifically for Industrial Users and Data Managers address the previous challenge of a mixed interface. This update includes a revamped sidebar and home page, making it easier for users to find the tools and information they need right from the start. The new design simplifies onboarding for both Industrial and Data Expert users and lays the groundwork for future more personalized landing pages.
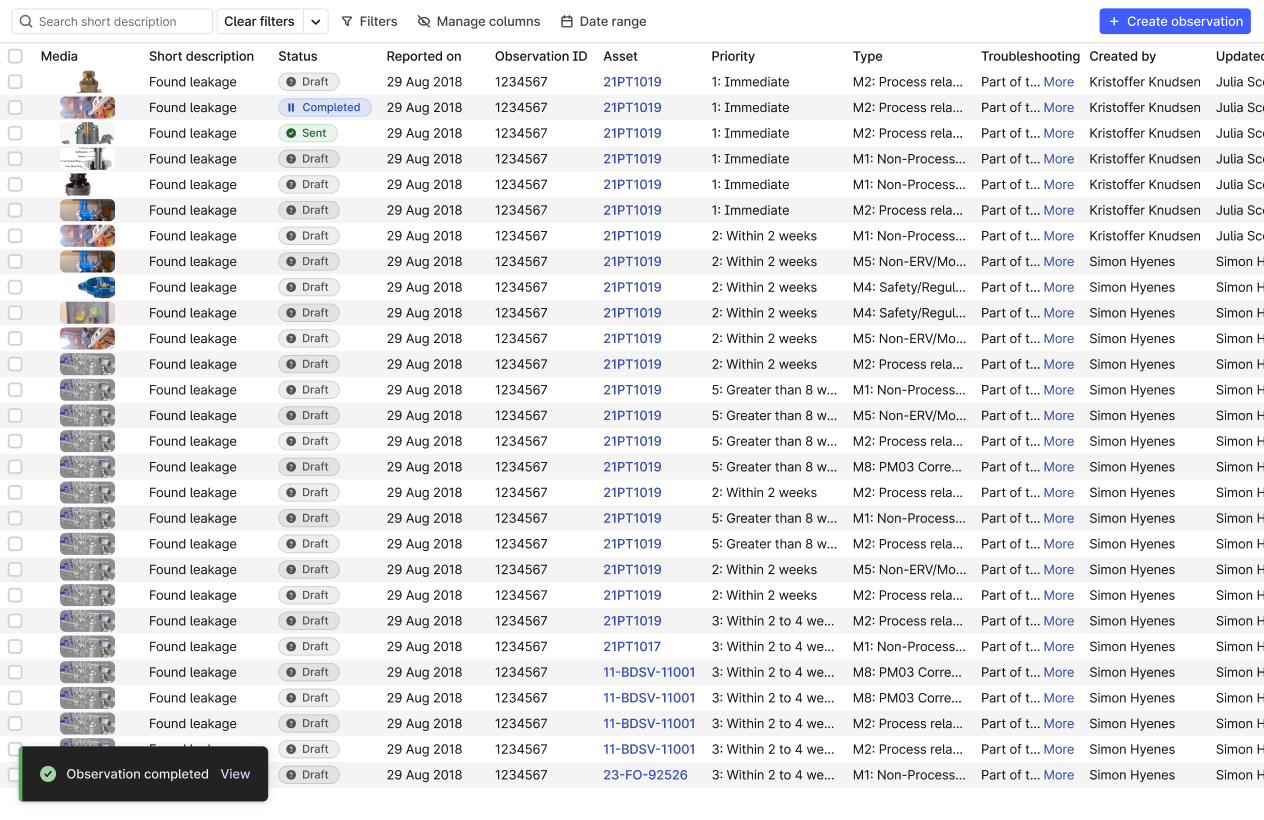
InField | customizable field observations (beta)
Configurable observations fit into field workers specific workflows. Ability to create Observations directly from their desktops, and use improved filtering and search capabilities. These enhancements make it easier to review media and discover high-critical findings. By customizing Observations to field workflows, users can ensure better actions and quickly address important issues, improving quality of data from the field, increase overall efficiency and reduce response times.
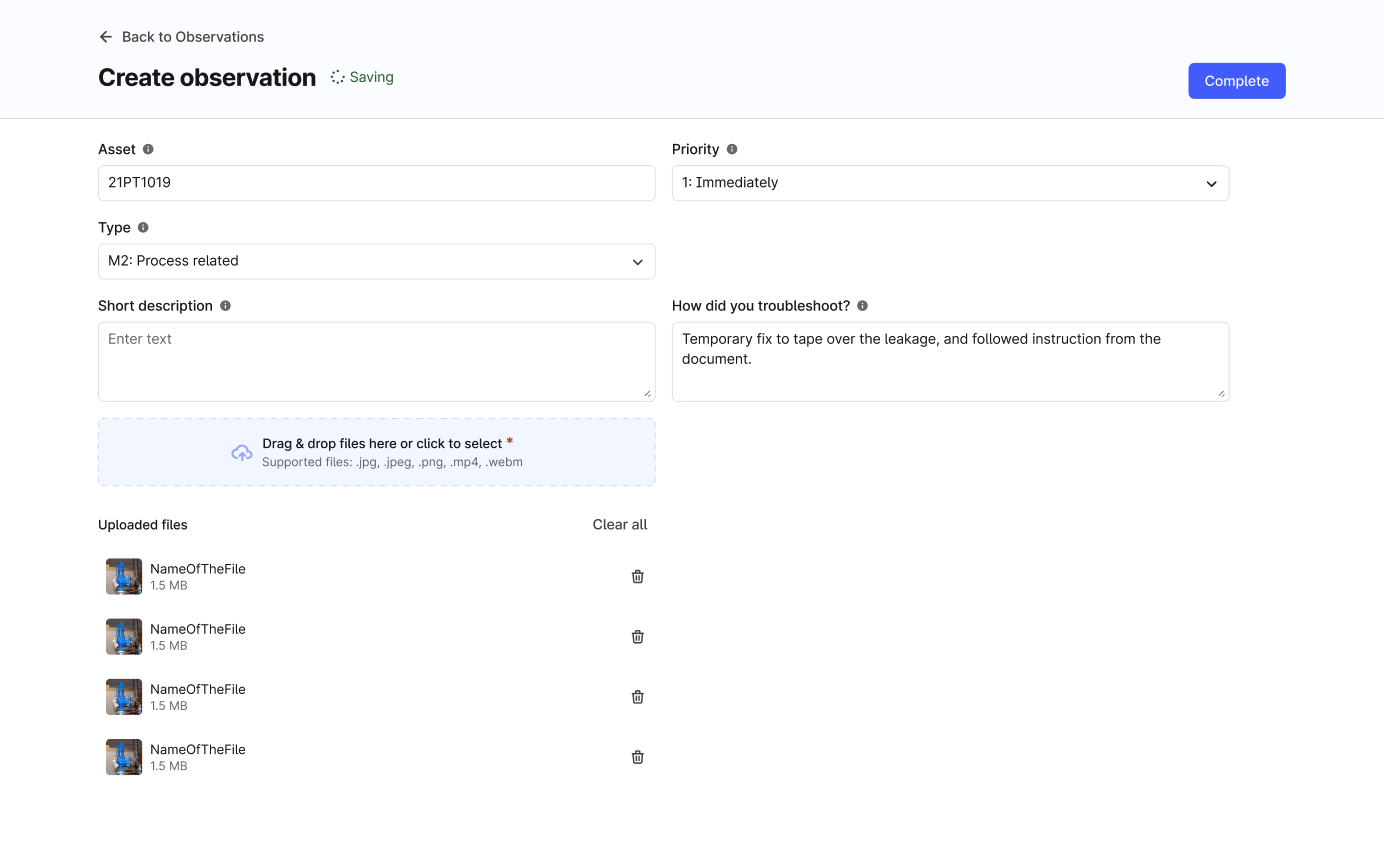
InField | mobile data explorer
Official launch of a mobile-only "Search" landing page improves access to relevant data in the field, addressing the issue of siloed information across different source systems. Field workers can now configure various InField workflows, such as observations and checklists, enabling or disabling them as needed. This update provides instant access to crucial data, offering a simple yet scalable solution for field workers. It simplifies deployment and can be expanded to accommodate additional workflows over time, enhancing overall efficiency and troubleshooting capabilities.
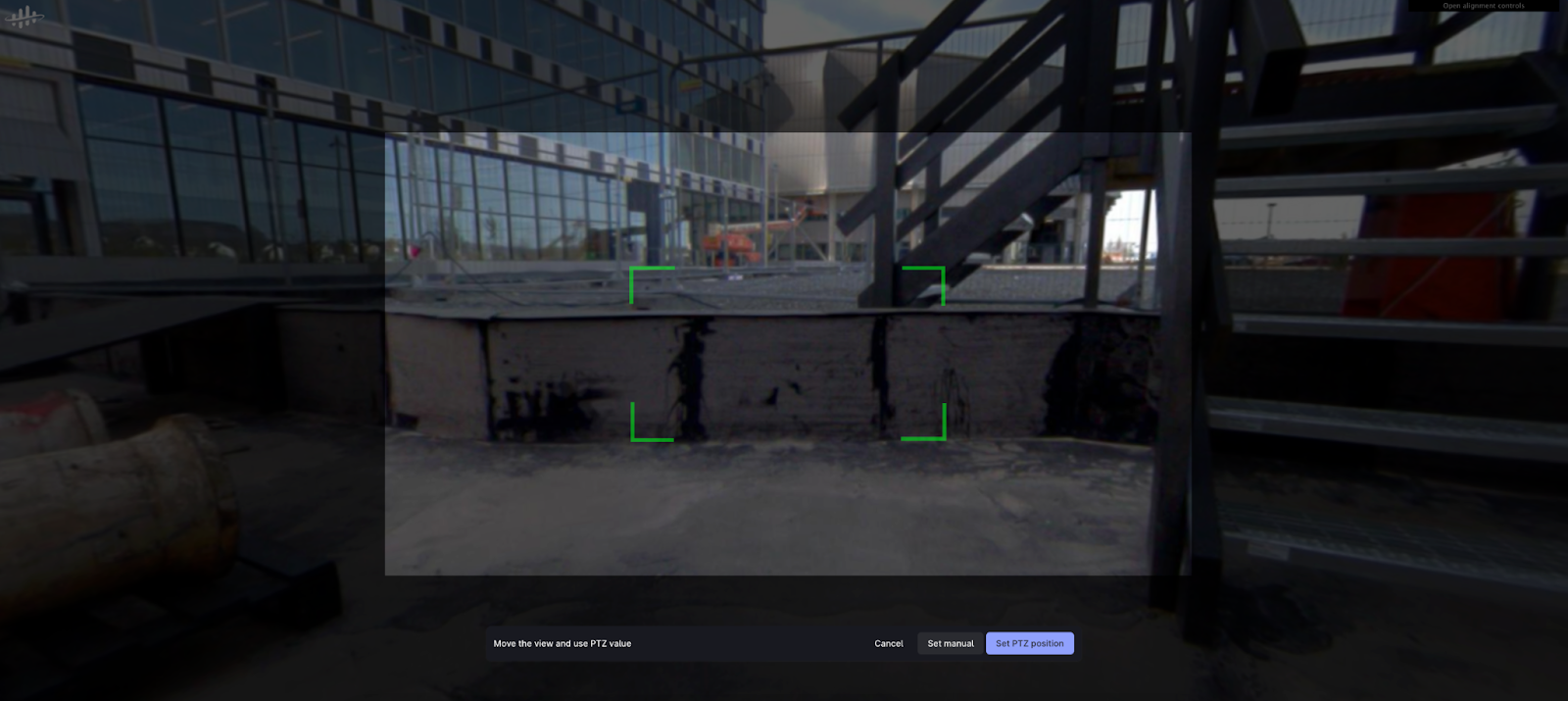
InRobot | offline robotic mission planning (beta)
Plan and create robotic missions offline using digital twins and contextualized 360 images, addressing the high costs and deployment delays associated with manual operator rounds. This feature enables users to define tasks and camera positions based on visual data, allowing the entire robotic mission to be prepared in advance. Once the robot is onsite, it can execute recurrent missions without any additional configuration, streamlining operations and reducing setup time.

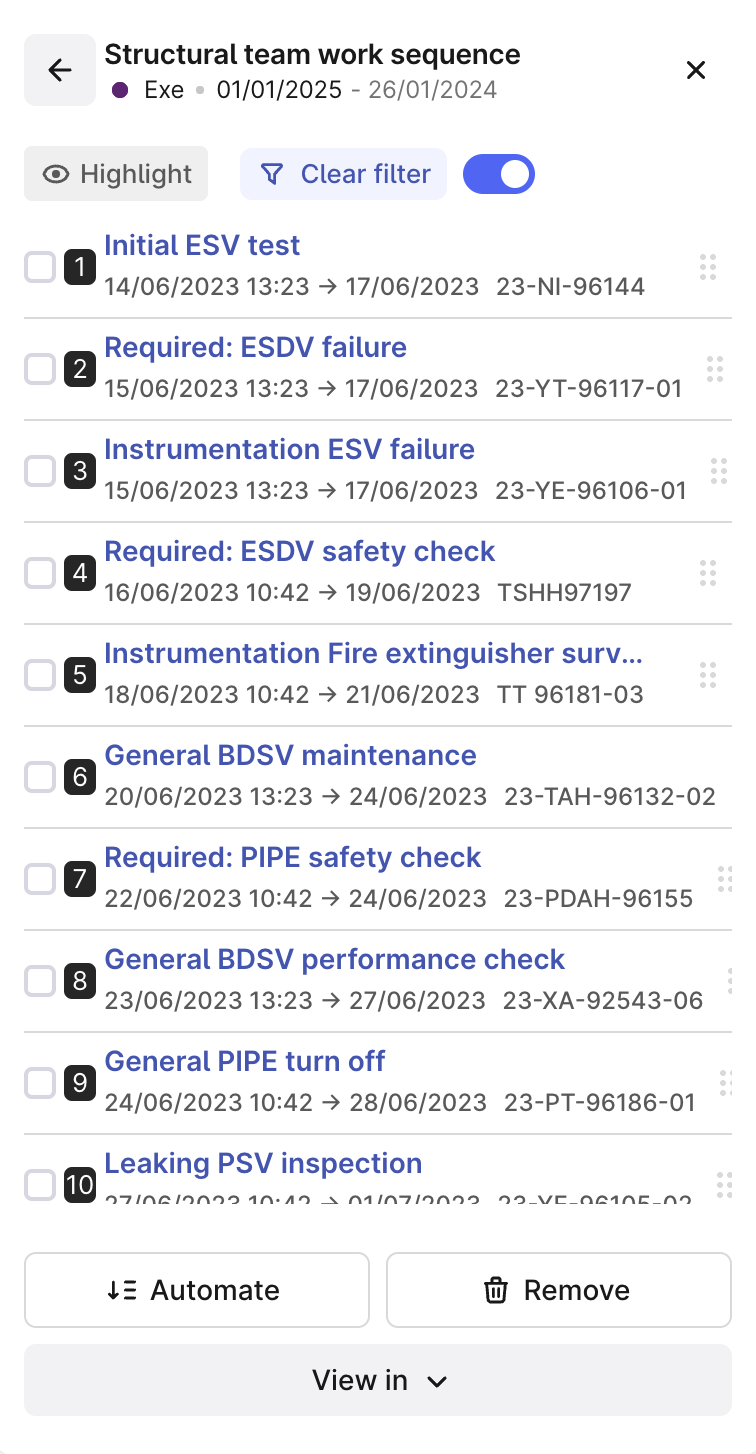
Maintain | enhanced activity sequencing (beta)
Automated sequencing for activities based on defined dependencies and constraints, such as shift duration, day or night work, and overlapping activities, addresses the inefficiencies of manual and Excel-based resource estimation for shutdowns or maintenance campaigns. Users can now gather sets of work orders into multiple sequences and toggle them on and off to observe their impact on the tradematrix. These features improve resource planning, reduce execution delays, and eliminate the cumbersome manual work of creating work order sequences and corresponding tradematrixes.
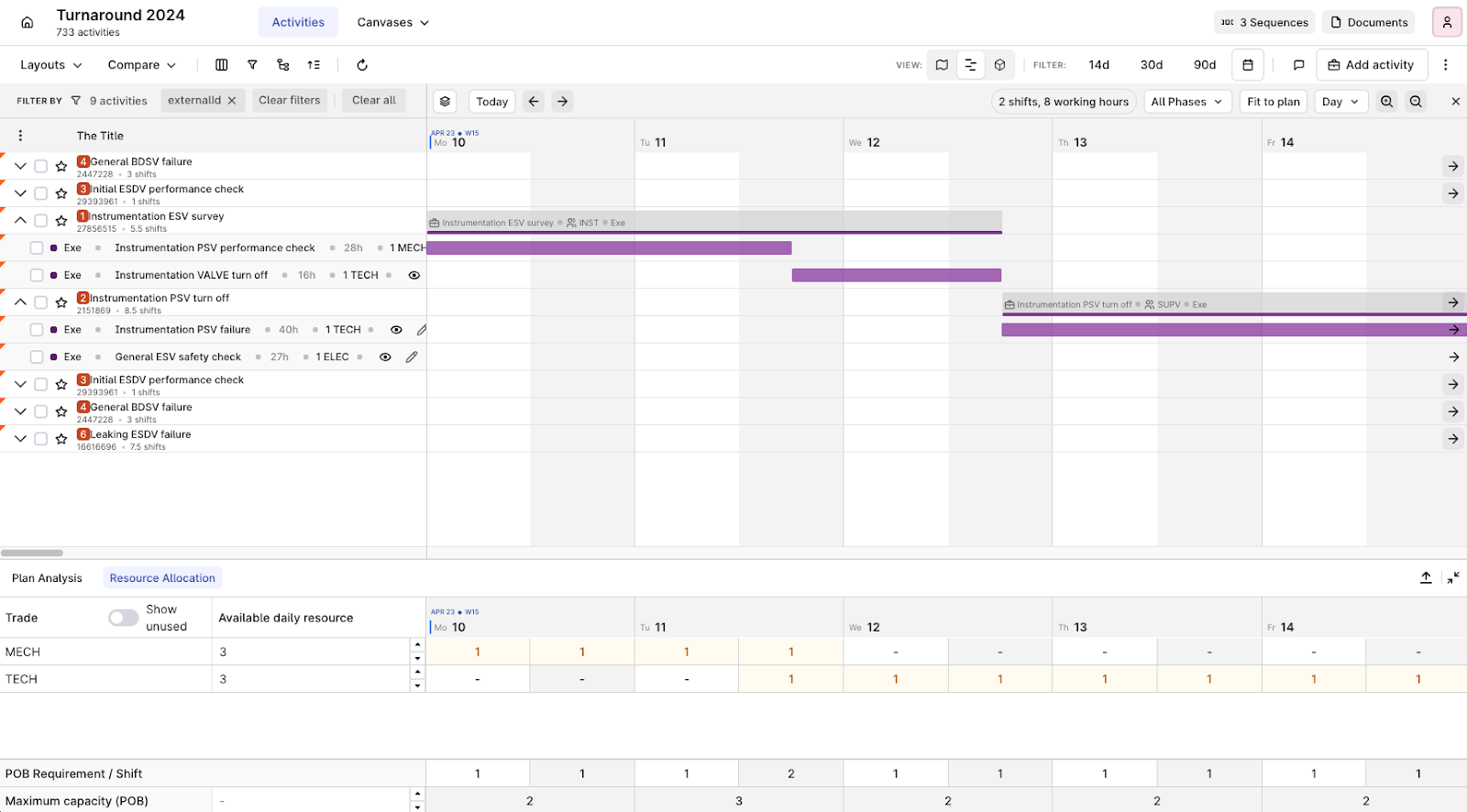
Maintain | shift support (beta)
Enhanced Gantt functionality displays both day and night shifts within a single day, along with the corresponding tradematrix for each shift. This update addresses the previous limitation in Maintain, which made it difficult to assess plans involving multiple shifts within the same day. By providing a clear view of resourcing needs for both shifts, this feature improves resource planning, reduces execution delays, and eliminates the need for manual Excel work to create work order sequences and corresponding tradematrixes.
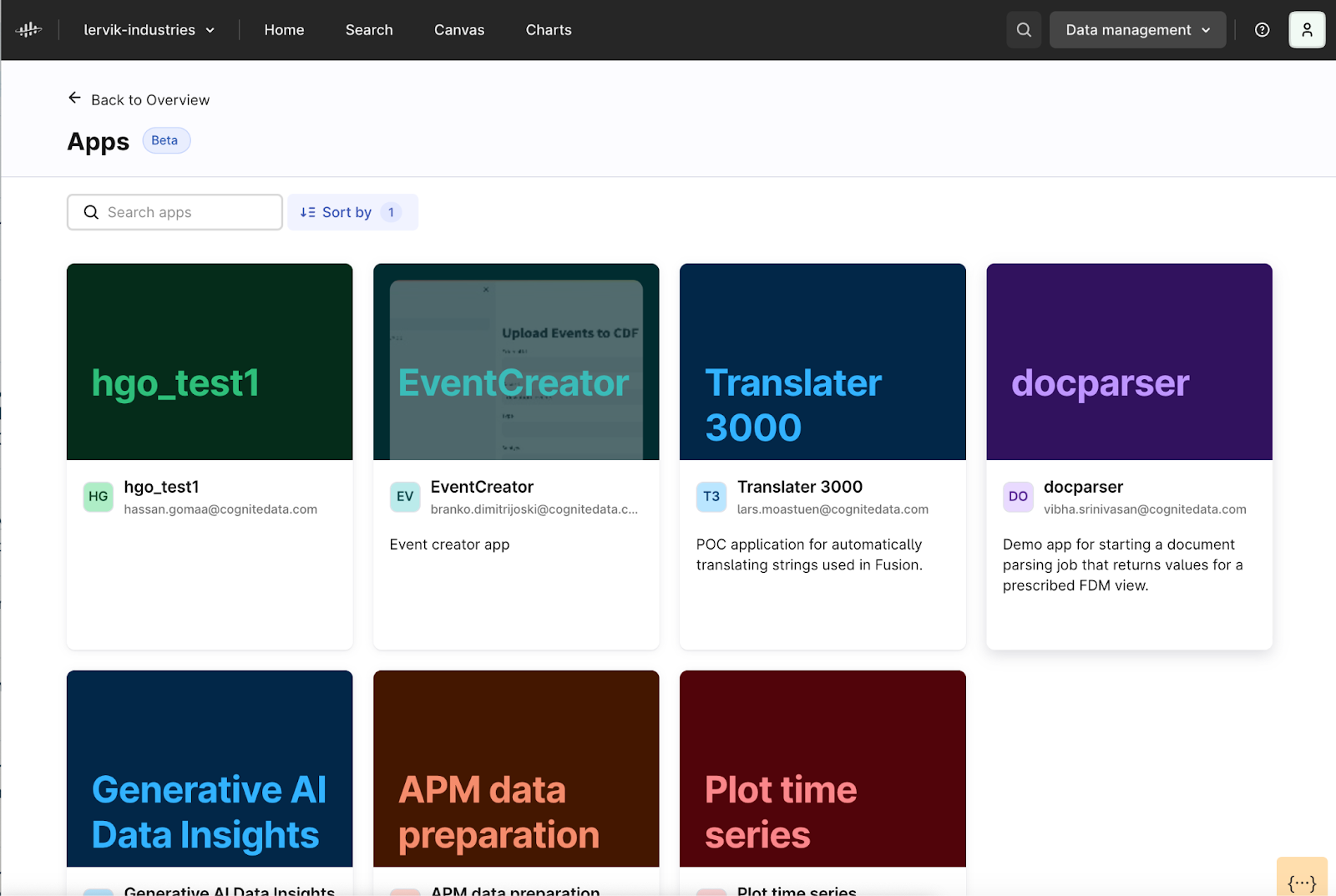
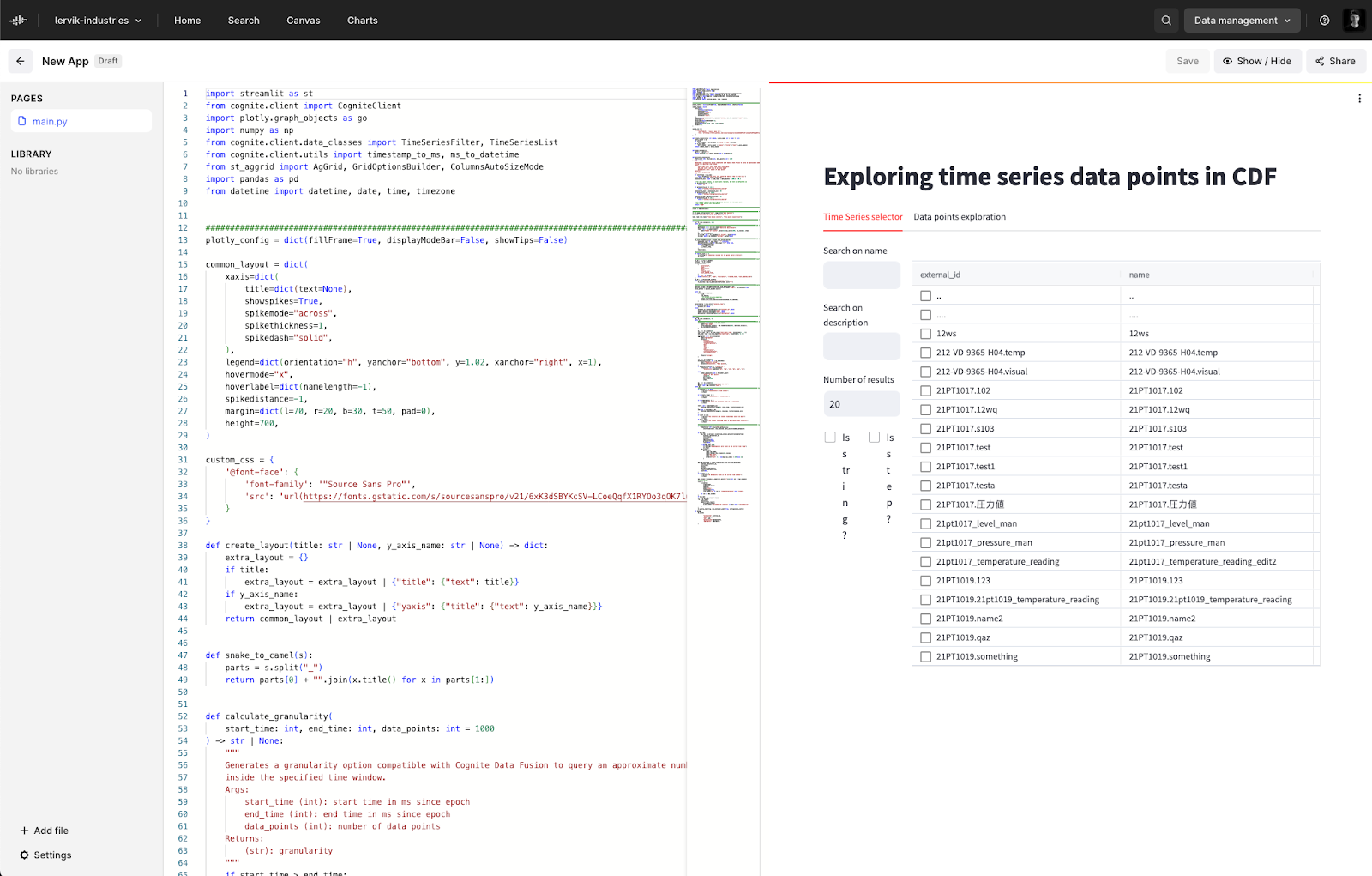
Streamlit | low-code applications (beta)
Users can now build low-code applications in Python using the Streamlit framework, simplifying the process of deploying applications. This capability addresses the time-consuming need for IT approval and hosting infrastructure. Users can now instantly deploy applications, making them accessible to non-coders. By lowering the burden of app development for citizen developers, this accelerates innovation and decreases the time required to share new solutions within their organization.
DATA OPERATIONS
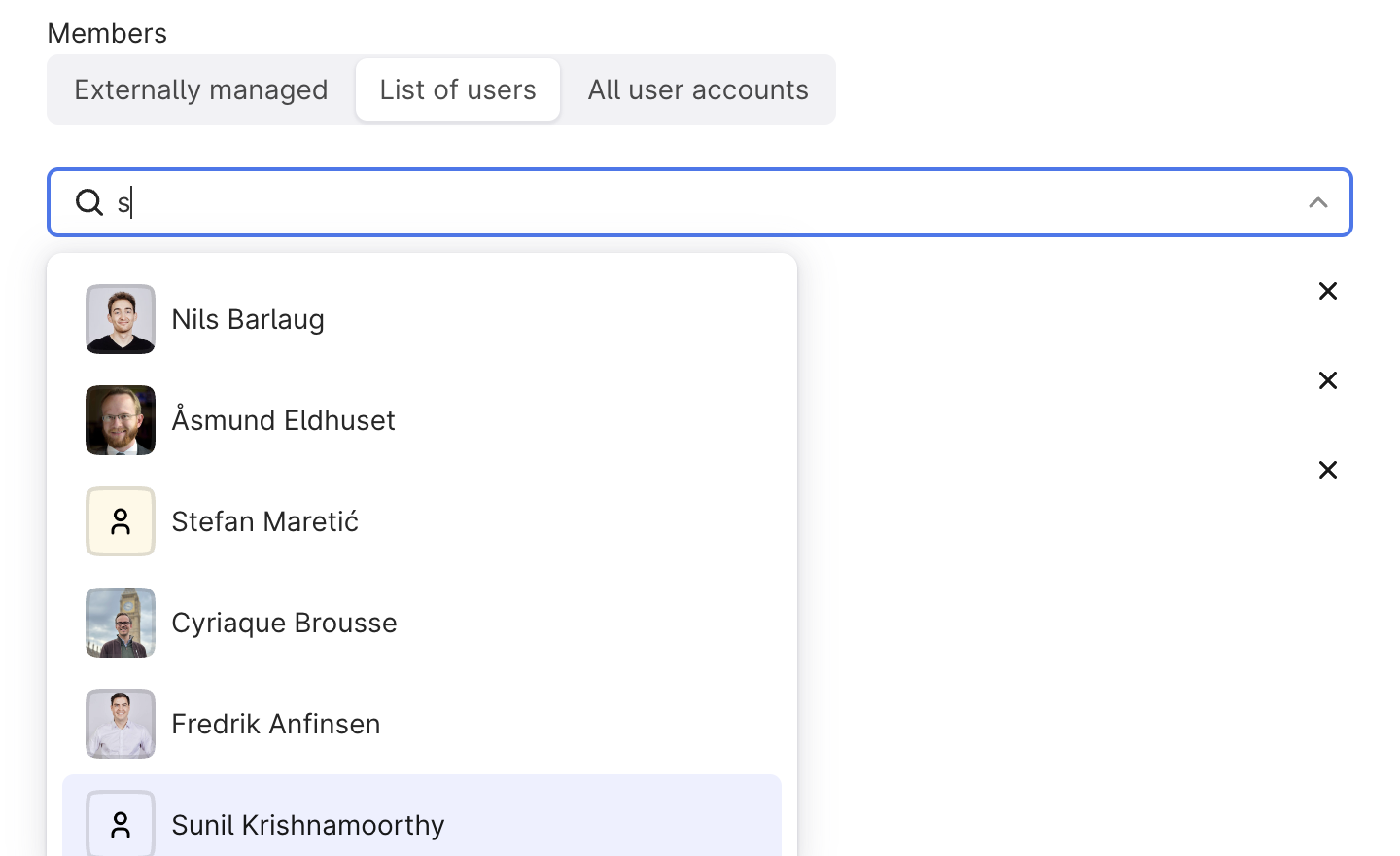
Auth & Access Management | simplified user management
CDF admins can now manage user access by adding users directly to groups within CDF, bypassing the need for often time-consuming approval processes . Additionally, admins can create a "default" access group for new users. This update eliminates delays, minimizes errors, and reduces the burden on internal approval processes, ensuring a smoother and more efficient onboarding process. As a result, new users experience a better first-time use of the product.
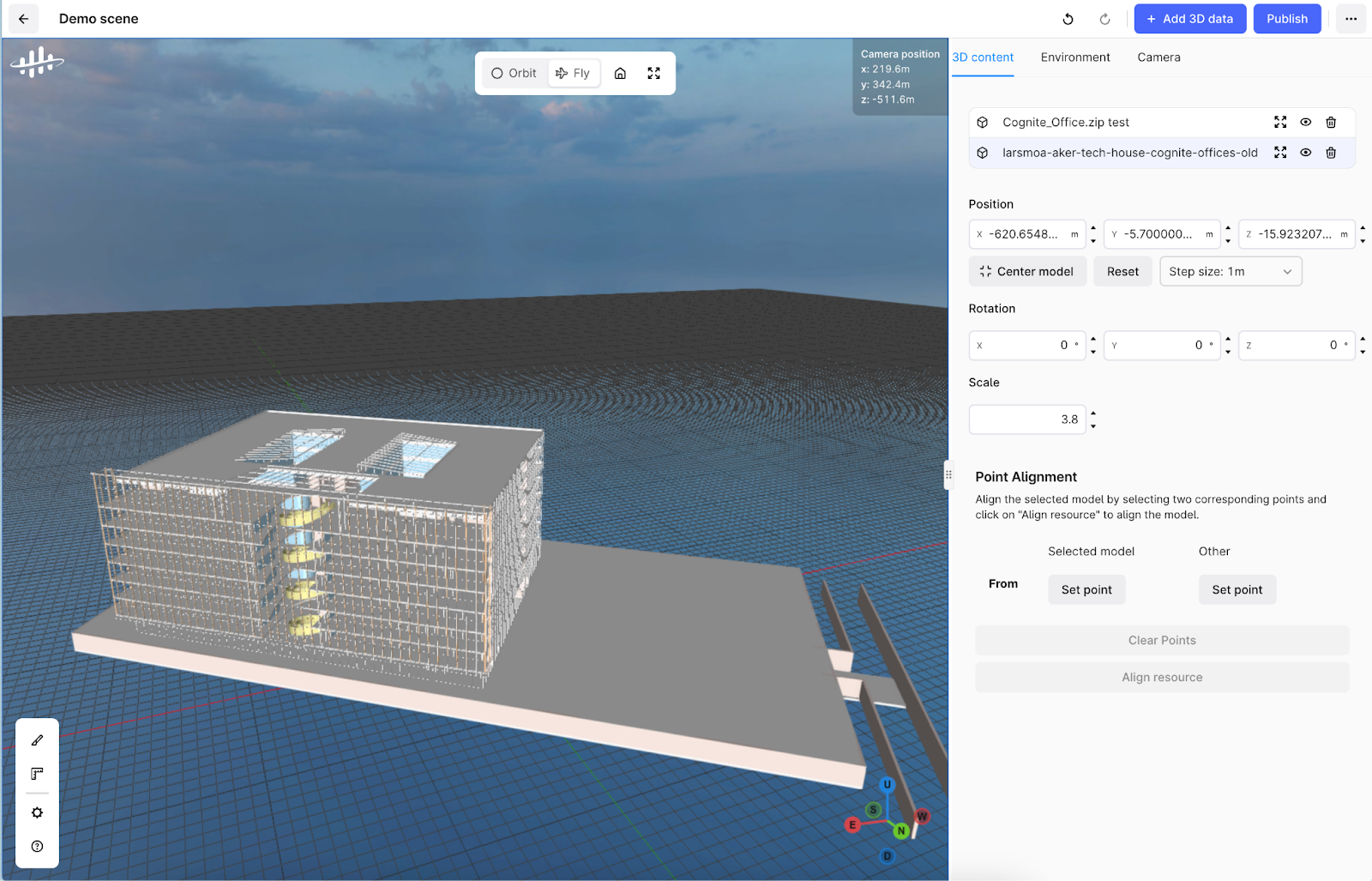
3D | contextualization and configuration enhancements
New 3D Scene Configurator aligns all 3D data correctly in relation to each other, addressing the challenge of viewing different models representing the same location together in one view. This improvement simplifies workflows and ensures accurate spatial relationships, providing a more immersive and precise representation of real-world environments for decision-makers in Cognite’s Industrial Tools or 3rd party applications developed with Reveal.
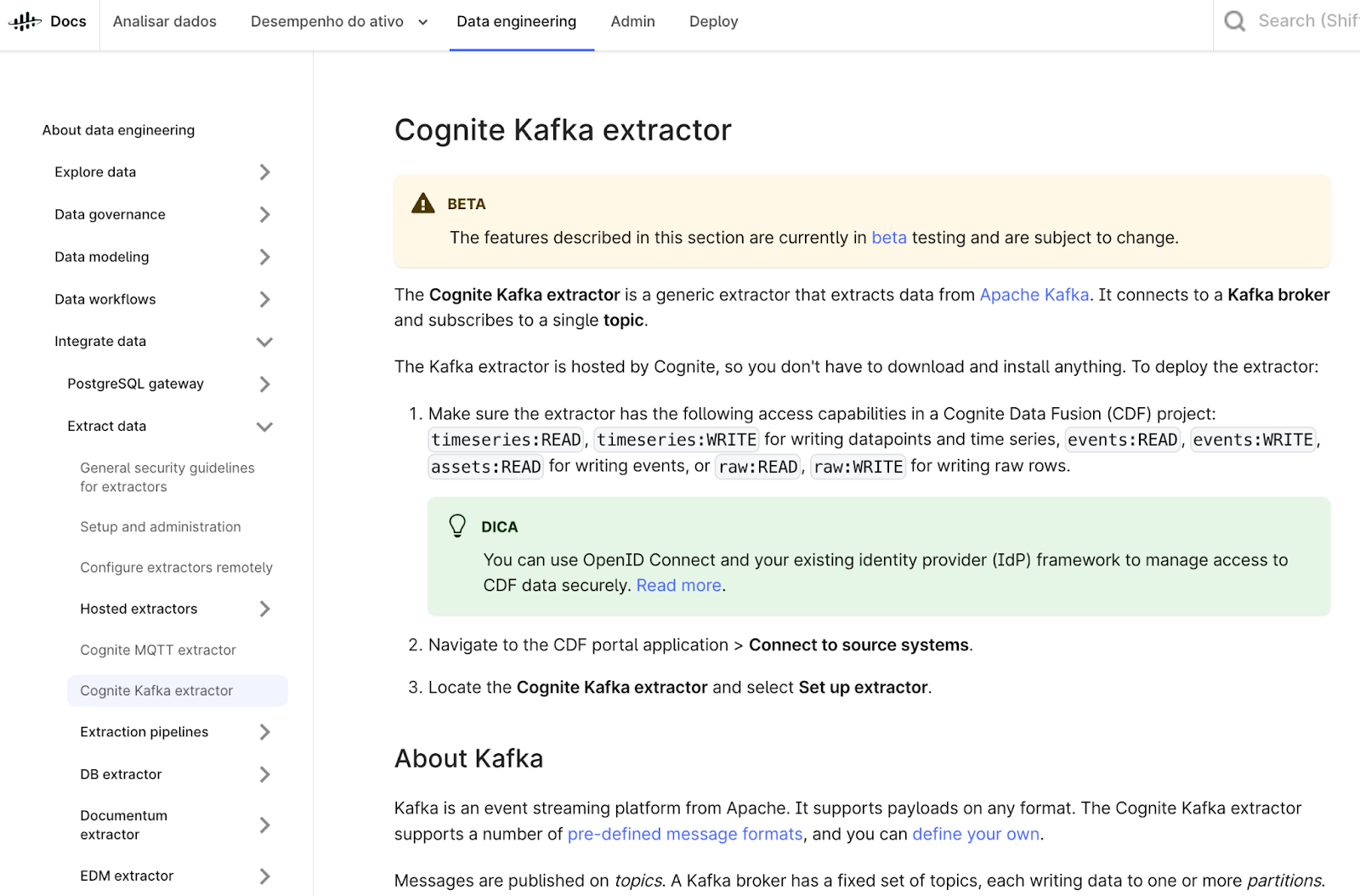
Extractors | Kafka hosted extractor (beta)
Support for Kafka messages as a hosted extractor eliminates the need for custom extractor development and deployment. This new extraction method allows users to connect to a Kafka broker and subscribe to a single topic directly. By supporting this popular event streaming protocol, the update provides instant connectivity, removing the need for downloading and installing extractors, and significantly streamlines the process for clients already using Apache Kafka.
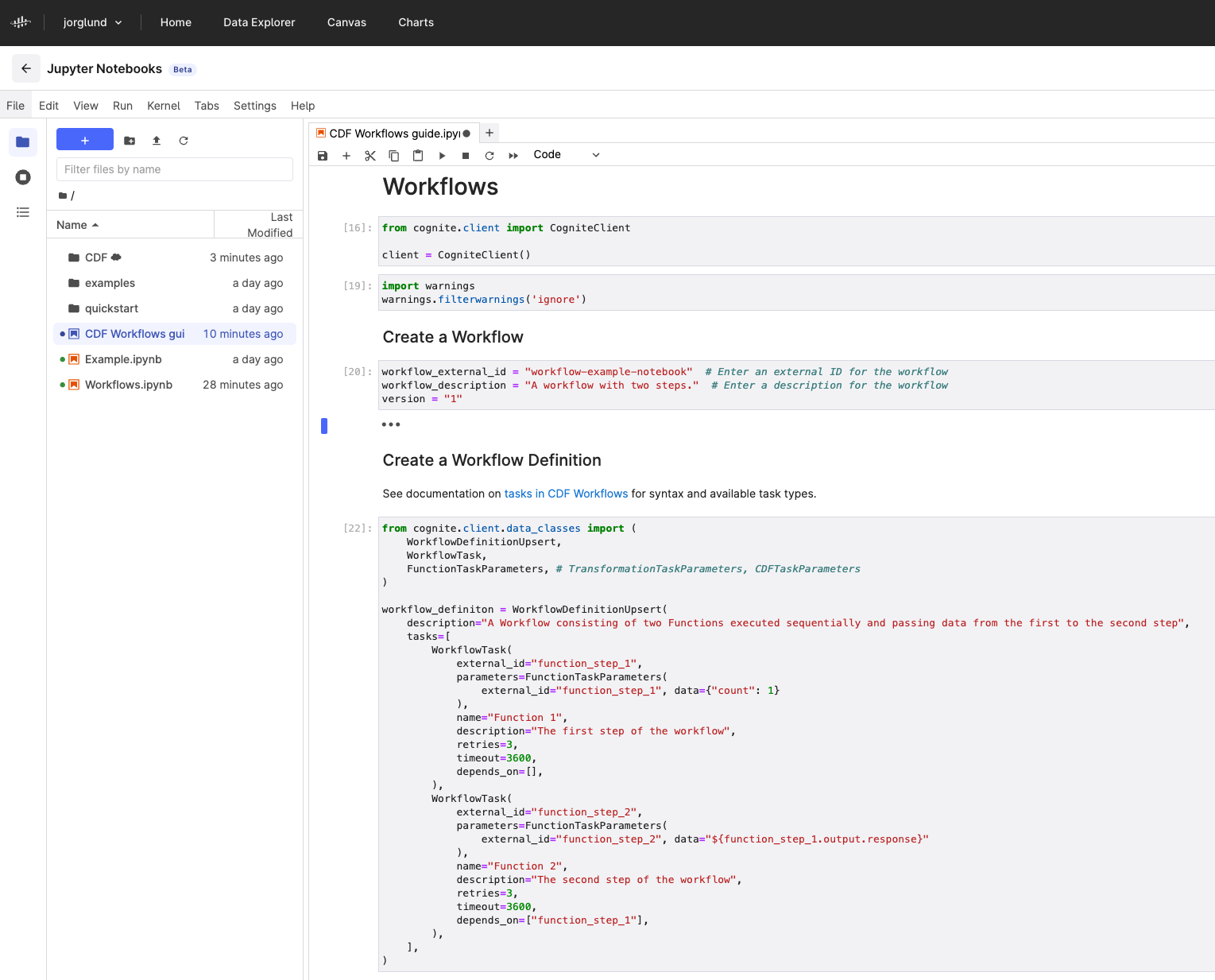
Data Workflows | data orchestration API
Official launch of the Data Workflows API allows users to orchestrate workflows that consist of Transformations, Functions, and CDF requests, along with their interdependencies. This update addresses the challenges of fragile pipelines, stale data, and difficulties in monitoring and scaling. By enabling the orchestration and monitoring of these workflows, users can minimize the effort required to manage data processes, significantly enhance the robustness and performance of data pipelines, and gain comprehensive observability of end-to-end pipelines rather than just individual processes.
Time Series | data quality status codes
Representation of time series data quality is now based on OPC UA standard status codes. This feature addresses the issue of users having to assume gaps in time series data are due to bad quality. By clearly indicating the quality status of each data point, users gain increased trust in the data. They can also choose how to treat good, bad, and uncertain data points in their calculations, preventing the automated removal of low-quality data during onboarding and ensuring more reliable data analysis.

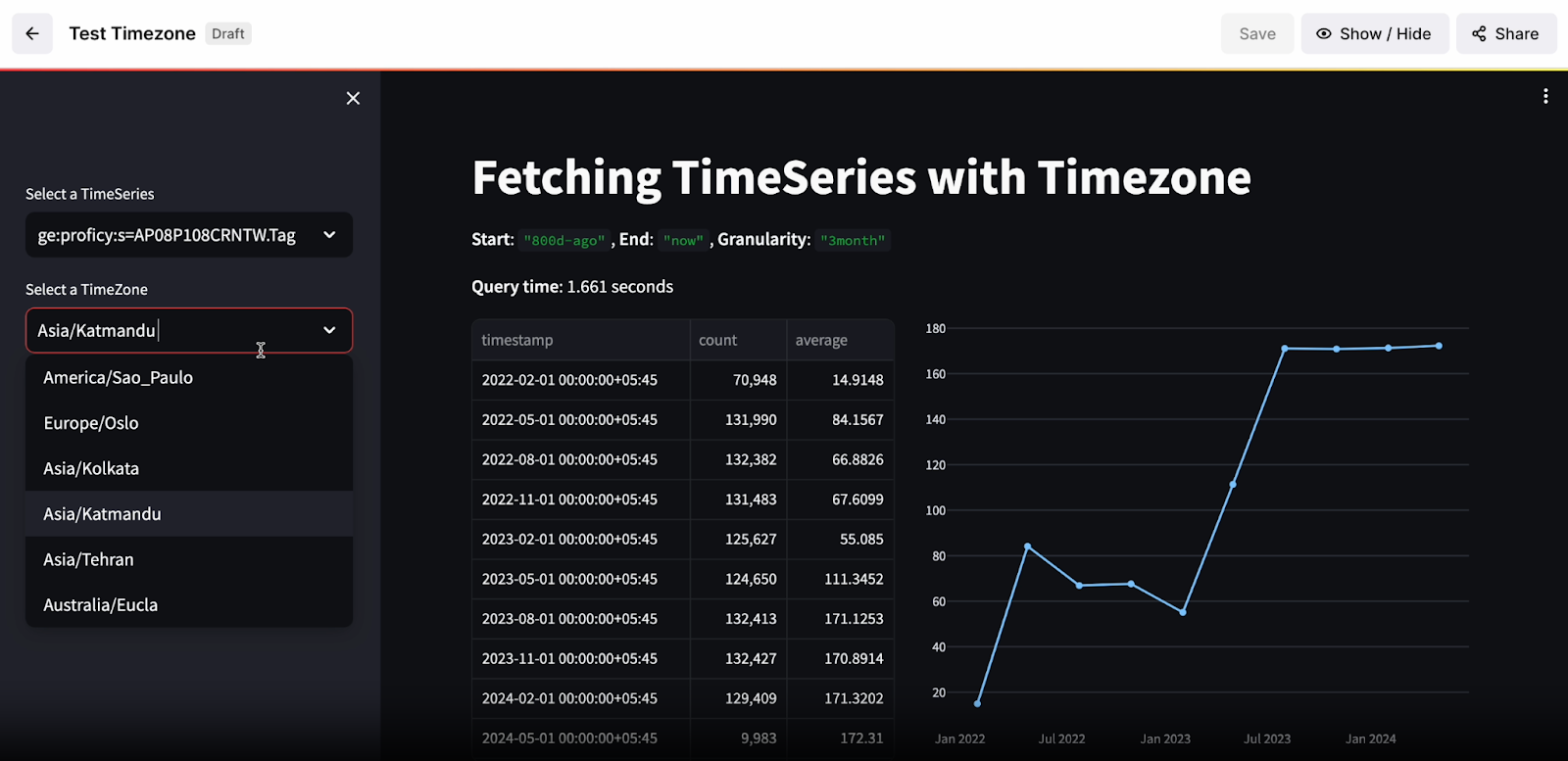
Time Series | improved data point queries (beta)
Enhanced capabilities for retrieving data points and aggregates address the need for convenient time series data point queries. Users can retrieve data points based on a named time zone or specified time offsets in 15-minute increments. Additionally, data point aggregates can be obtained using Gregorian calendar units such as days, weeks, months, quarters, and years. This feature increases developer speed by providing a convenient API for data retrieval and improves the accuracy of queries by reducing the likelihood of code errors.