Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


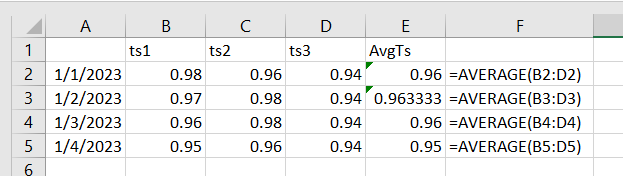
Are Synthetic Time Series able to reference other Synthetic Time Series in their formulas specified?
This is the problem I am trying to solve:
- Synthetic Time Series is limited to referencing 100 time series
- Sometimes a unit/facility/system/functional location/site may have more than 100 direct child assets
- I need to calculate a “Synthetic Time Series” that is the daily average of a time series found on all child assets
My thought is that, for 300 assets, I would have:
- STS A: Sum for assets 1-100
- STS B: Sum for assets 101-200
- STS C: Sum for assets 201-300
- STS D: Sum of STS A, B, and C divided by 300
Is there a better way to accomplish something like this in CDF?
Best answer by Torgrim Aas
View original