Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support



We have an equipment with name PI91111 on the P&ID and on the other hand we have this equipment in the asset Hierarchy.
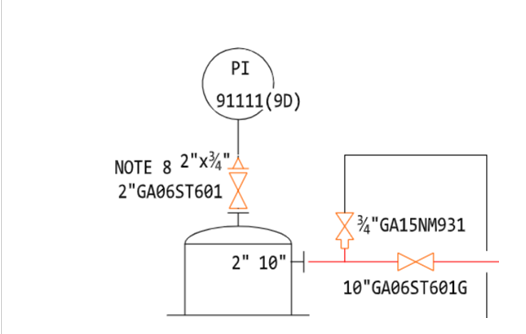
This equipment is not getting contextualized for this P&ID.
I have used standard model and advanced model with min tokens 1 & 2 as well.
The ocr output for this is below:

Best answer by Ola Liabøtrø
View original