Check the
documentation
Check the
documentation Ask the
Community
Ask the
Community Take a look
at
Academy
Take a look
at
Academy Cognite
Status
Page
Cognite
Status
Page Contact
Cognite Support
Contact
Cognite Support


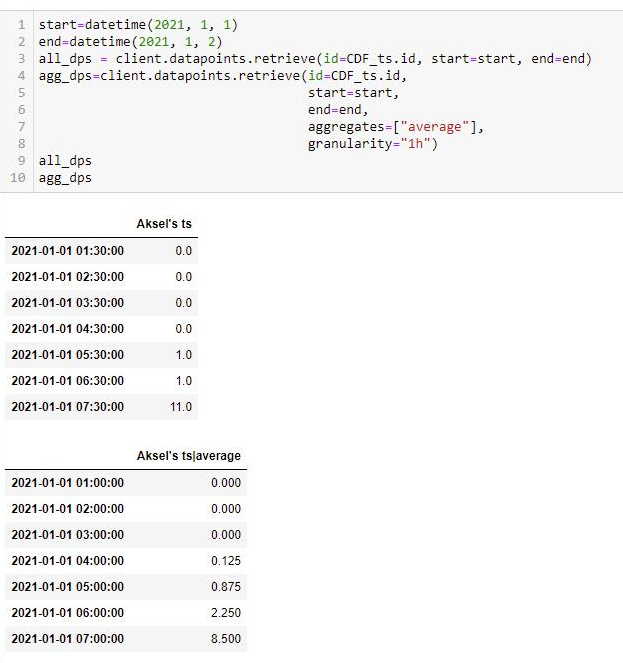
The example above shows that 1h aggregates of type average computed at time-point 03:00 takes into considereation the interpolated values in the time-span 03:00 to 04:00. Is it always like this as long as i choose granualarity 1h ?
I could not find the answer to my question here:
Aggregation | Cognite documentation
Best answer by Håkon V. Treider
View original